Лабораторная работа
Исследование векторного квантования сигналов
(Исследование CELP–кодера речевого сигнала)
Цель работы
Оценить эффективность использования векторного квантования при сжатии (эффективном кодировании) потока данных речевого сигнала.
Краткие теоретические сведения о кодировании речевого сигнала с помощью векторного квантования.
При параметрическом спектральном анализе речевых сигналов успешно используется авторегрессионная модель формирования сигнала. В этом случае на выходе анализирующего фильтра речевого сигнала формируется сигнал остатка предсказания. В общем случае форма этого сигнала достаточно сложная для описания. Однако при невысоких требованиях к уровню искажений синтезированного на приемной стороне речевого сигнала остаток предсказания упрощенно моделируют либо последовательностью коротких прямоугольных импульсов, следующих с частотой основного тона, либо белым шумом. На основе такой модели остатка предсказания работает LPCречевой кодек.
Крупным недостатком LPC (LinearPredictionCoding)-кодека с возбуждением синтезирующего фильтра импульсами основного тона является низкое качество синтезируемого сигнала, которое обусловлено грубостью моделирования сигнала возбуждения (либо шум, либо последовательность импульсов). Разделение всех звуков на вокализованные и невокализованные является грубым, поскольку существуют звуки речи (звуки «Ж», «З»), синтез которых требует наличия в сигнале возбуждения коррелированных шумового и периодического компонентов.
С целью снижения искажений используют более точную модель остатка предсказания, которая потом используется при возбуждении синтезирующего фильтра (при синтезе сигнала) на приемной стороне канала связи. Повышение точности моделирования остатка предсказания в случае невокализованных звуков достигается заменой сегмента (короткого отрезка) остатка предсказания реализацией белого шума из перечня таких реализаций, которые хранятся под своими номерами (индексами) в особой области памяти – в кодовой книге. Выбирается такая реализация, которая наиболее точно соответствует данному сегменту остатка предсказания.
На приемную сторону передается номер реализации, которая извлекается из копии кодовой книги и подается на синтезирующий фильтр. Говорят, что синтезирующий фильтр возбуждается кодом, а речевой кодек называют CELP – кодеком (CodeExcitingLinearPrediction – CELP). Вышеописанные процессы анализа и синтеза сигнала соответствуют векторному квантованию сегмента остатка предсказания.
Если анализируется сегмент остатка предсказания в случае вокализованного звука, то этот сегмент проходит дополнительно процедуру «долговременного» предсказания, при котором по предыдущему импульсу основного тона предсказывается последующий импульс. В этом случае говорят о работе предиктора основного тона. По сути, процедура аналогична ранее рассмотренной процедуре линейного предсказания, которое называется в этом случае «кратковременным». После «долговременного» анализа остатка предсказания он становится похожим на белый шум, и к нему применяют вышеописанную процедуру векторного квантования.
Рассмотрим использование векторного квантования в CELP – кодеке более подробно. После анализирующего фильтра, присутствующего в схеме Ра нее рассмотренного LPC-кодека, с частотной характеристикой
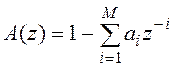 , где ai – коэффициенты «кратковременного» предсказания, M
– порядок предсказания, включают фильтр «долговременного» анализа (на основе
предсказывающего фильтра - предиктора основного тона). Частотная характеристика
фильтра имеет вид:
, где ai – коэффициенты «кратковременного» предсказания, M
– порядок предсказания, включают фильтр «долговременного» анализа (на основе
предсказывающего фильтра - предиктора основного тона). Частотная характеристика
фильтра имеет вид:
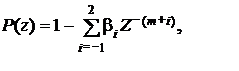 |
Назначение данного фильтра состоит в устранении корреляции в сигнале остатка предсказания, которую вносят импульсы основного тона. Структура фильтра долговременного анализа такая же, как и у анализирующего фильтра LPC–кодера (последний является фильтром кратковременного анализа сигнала). Однако в отличие от анализирующего фильтра, он содержит меньшее число звеньев (в основном — три звена).
Принцип работы фильтра долговременного анализа аналогичен работе анализирующего фильтра и отличается лишь величиной задержки входного сигнала в первом звене фильтра. У анализирующего фильтра она равна периоду дискретизации входного сигнала Тд, а у фильтра долговременного анализа - (Тот - Тд ), где Тот - период следования импульсов основного тона.
В процессе прохождения сегмента сигнала (кадра) через фильтр долговременного анализа он разбивается на несколько субкадров, далее вычисляются значения трех коэффициентов долговременного предсказания: β1, β2 и β3 для каждого субкадра. Чем больше число субкадров, тем точнее моделируется сигнал возбуждения. Сигнал на выходе фильтра практически лишен корреляционных связей и похож на белый шум.
Для формирования сигнала возбуждения синтезирующего фильтра в структуре кодека имеется фильтр, частотная характеристика которого обратна частотной характеристике фильтра долговременного анализа. Фильтр получил название фильтра долговременного синтеза. Его частотная характеристика имеет вид:
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.



