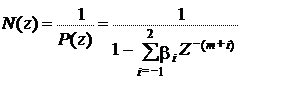 |
Кодовые книги бывают двух видов: детерминированные и стохастические. Детерминированная кодовая книга образуется из большого количества образцов речевого сигнала. Векторы параметров в процессе создания книги извлекаются из случайной разговорной речи достаточно большой длительности (30 … 40 мин) на мужских и женских голосах. Кодовые книги, образованные на основе реального речевого сигнала, называются детерминированными.
В отличие от детерминированных существуют стохастические кодовые книг, которые составляются из случайной последовательности с равномерным энергетическим спектром. Стохастические кодовые книги обусловливают меньшую точность синтеза сигнала. Однако преимущество стохастической кодовой книги заключается в том, что ее образование обходится без длительного процесса «обучения» на реальных речевых сигналах.
Для снижения искажений в кодере используется так называемый метод анализа (кодирования) сигнала через его синтез (декодирование). При этом на этапе кодирования производится декодирование, и синтезированный сигнал сравнивается с входным сигналом кодера.
Параметры кодирования настраиваются так, чтобы обеспечить минимум отличий между сравниваемыми сигналами.
Выбор оптимального вектора из кодовой книги
В кодирующем устройстве на вход синтезирующего фильтра подаются векторы из кодовой книги. Сначала подается вектор под номером 1. Путем оптимальной настройки коэффициента G усиления оценка дисперсии E разности между исходным речевым сигналом S(n) и синтезированным речевым сигналом S'(n) минимизируется. Оптимальный коэффициент усиления
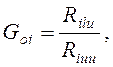 где
где 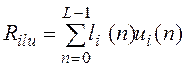 ,
,
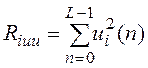 , где i – номер субкадра, li(n) и ui(n) – остаток предсказания на выходе фильтра долговременного анализа
и последовательность шума кодовой книги соответственно, L – число отсчетов в субкадре. Здесь Rilu отражает степень взаимной кореляции сигналов кодовой книги
и остатка «долговременного» предсказания, Riuu - мощность сигнала остатка предсказания.
, где i – номер субкадра, li(n) и ui(n) – остаток предсказания на выходе фильтра долговременного анализа
и последовательность шума кодовой книги соответственно, L – число отсчетов в субкадре. Здесь Rilu отражает степень взаимной кореляции сигналов кодовой книги
и остатка «долговременного» предсказания, Riuu - мощность сигнала остатка предсказания.
Затем номер (индекс, код) последовательности шума в кодовой книге увеличивается на единицу и снова вычисляется оценка дисперсии. Эта процедура повторяется до тех пор, пока не будет проанализировано все содержание кодовой книги и не будет найдена оптимальная последовательность шума, обеспечивающая минимум E. Эта оптимальная последовательность шума, то есть оптимальное возбуждение в виде индекса вектора N одновременно с коэффициентом усиления и параметрами кратковременного и долговременного анализирующих фильтров A(z) и P(z) передается на декодер.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.