
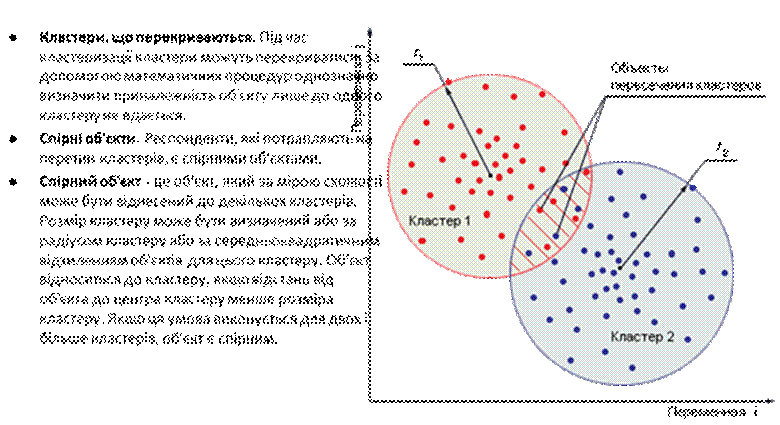
l Пояснимо, яким чином сформована таблиця:
l У першому стовпці розташований номер кластера - групи, дані якої наведені в рядку. Наприклад, перший кластер на 80% складається з чоловіків. 90% першого кластеру потрапляють у вікову категорію від 30 до 50 років, а 12% респондентів вважає, що пільги дуже важливі. І так далі.
l Спробуємо навести портрети респондентів кожного кластеру.
l Перша група - здебільшого чоловіки зрілого віку, які займають керівні позиції. Соцпакет (MED, LGOTI TIME - вільний час) їх не цікавить. Вони вважають за краще отримувати гарну зарплату, а не допомогу від працедавця.
l Група два навпаки віддає перевагу соцпакету. Її утворюють в основному респонденти "у віці", що займають невисокі пости. Зарплата для них безумовно важлива, але є й інші пріоритети.
l Третя група найбільш "молода". На відміну від попередніх двох, в наявності - інтерес до можливостей навчання й професійного зростання.
Як виникають помилки кластеризації?
Кількість кластерів.
Головне питання кластерного аналізу – питання про кількість кластерів. Тут відсутні чіткі правила, що дозволяють швидко прийняти рішення, але можна керуватися наступними.
l У ієрархічній кластеризації в якості критерію можна використовувати відстані, за якими об'єднують кластери.
l У неієрархічній кластеризації зображують графік залежності відношення сумарної внутрішньогрупової дисперсії до міжгрупової дисперсії від кількості кластерів. Точка, в якій спостерігається вигин або різкий поворот, вказує на прийнятну кількість кластерів.
Відносні розміри кластерів мають бути досить виразними. (Безглуздо створювати кластер з одним випадком).
Приклад ієрархічного кластерного аналізу
l Масив st01.sav
l Ознаки 210-214, що визначають міру згоди з перерахованими моральними принципами
l Метод Варда
l Метрика - квадрат евклідової відстані
Інтерпретація результатів кластерного анализу:
1)
кількість спостережень, що підлягають кластеризації, зазначена в
таблиці
Case Processing Summary
|
Case Processing Summary a,b |
|||||
|
Cases |
|||||
|
Valid |
Missing |
Total |
|||
|
N |
Percent |
N |
Percent |
N |
Percent |
|
1572 |
93,6 |
108 |
6,4 |
1680 |
100 |
|
a Squared Euclidean Distance used |
|||||
|
b Ward Linkage |
|||||
2) Визначення кількості кластерів за таблицею Agglomeration Schedule
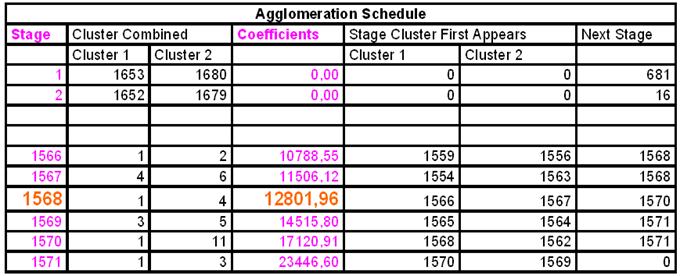
Кількість кластерів = N - S, де N - кількість анкет, що підлягали кластеризації, S - крок, після якого спостерігається скачок коефіцієнта. Кількість кластерів = 1572 - 1568 = 4.
Інтерпретація кластерів – опис кластерних центроїдів
|
N кластера |
Обсяг класте-ра |
210. Око за око |
211. Не обдуриш - не проживеш |
212. Варварство викорінюєть-ся варварством |
213. Кожен сам за себе |
214. Людина людині - вовк |
|
1 |
779 |
4,99 |
4,06 |
4,25 |
2,29 |
2,48 |
|
2 |
336 |
6,06 |
5,58 |
5,71 |
5,80 |
4,87 |
|
3 |
325 |
4,47 |
3,93 |
3,80 |
5,12 |
3,86 |
|
4 |
132 |
1,77 |
1,97 |
1,46 |
2,33 |
1,75 |
Оцінка надійності й достовірності. Маючи декілька висновків, зроблених в процесі кластерного аналізу, не слід приймати певне рішення про кластеризацію, не виконавши оцінку надійності й достовірності цього рішення. Формальні процедури оцінки надійності й достовірності рішень кластеризації досить складні і не завжди виправдані. Проте наступні процедури забезпечать адекватну перевірку якості кластерного аналізу.
l Виконуйте кластерний аналіз на підставі одних і тих же даних, але з використанням різних способів вимірювання відстані. Порівняйте результати, отримані на основі різних вимірювань відстані, щоб визначити, наскільки співпадають отримані результати.
l Використовуйте різні методи кластерного аналізу і порівняйте отримані результати.
l Розбийте дані на дві рівні частини випадковим чином. Виконайте кластерний аналіз окремо для кожної половини. Порівняйте кластерні центроїди двох підвибірок.
l Випадковим чином видаліть деякі змінні. Виконайте кластерний аналіз за скороченим набором змінних. Порівняйте результати з отриманими на основі повного набору змінних.
l У неієрархічній кластеризації рішення може залежати від порядку випадків в наборі даних. Виконайте аналіз кілька разів, змінюючи порядок випадків, до отримання стабільного рішення.
Висновки:
l Кластерний аналіз застосовують для групування (класифікації) об'єктів у відносно однорідні групи. Утворення кластерів залежить від наявних даних, а не визначається заздалегідь.
l Гомогенні респонденти (за певними відповідями) об'єднуються в одну групу, гетерогенні – у різні.
l Кластерні центроїди представляють середні значення об'єктів, що містяться в кожній змінній, які були основою кластеризації. Кластерні центроїди дозволяють описати кожен кластер.
l Кластерний аналіз є описовою процедурою, він не дозволяє зробити статистичні висновки, але надає можливість провести своєрідну розвідку - вивчити структуру досліджуваної сукупності.
l На відміну від факторного аналізу, кластерний аналіз може бути застосований для різних типів шкал.
Література:
l Паніотто В.І., Максименко В.С., Харченко Н.М. Статистичний аналіз соціологічних даних. – К.: «КМ Академія», 2004. – С. 232-241.
l Ядов В.А. Стратегия социологического исследования. Описание, объяснение, понимание социальной реальности. – М.: “Добросвет”, 1998.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.