Если обновление требует больше пространства, чем доступно на самом деле на этой странице, строка будет перемещена в новую страницу данных. Строка имеет указатель на перемещённые данные в оригинальном месте расположения. Если строка должны быть перемещена снова, то данные перемещаются и оригинальный указатель изменяется.
Указатель продвижения гарантирует, что не кластерный индекс не требует изменения. Если требуется сокращение размера базы данных, то во время этого процесса данные возвращаются на свою позицию при обновлении всех данных.
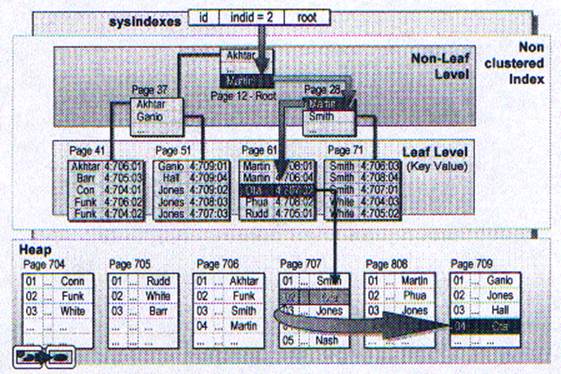
Обновление часто требует места без сильного воздействия на структуру данных. Обновление часто не требует перемещения строк. Перемещения не требуется, если обновление требует не столько же или меньше места в той же странице. Обновление обычно генерирует только одну строку в журнале.
Обновление требует перемещение строки, что заносится в журнал как удаление и вставка если:
![]() Обновление не помещается на странице в куче;
Обновление не помещается на странице в куче;
![]() Таблица имеет триггер обновления;
Таблица имеет триггер обновления;
![]() Таблица помечена для репликации;
Таблица помечена для репликации;
![]() Значение кластерного индекса требует строки для помещения в
другое место. Для примера, фамилия (по которой отсортировано) изменена и
требует перемещения строки в другое место.
Значение кластерного индекса требует строки для помещения в
другое место. Для примера, фамилия (по которой отсортировано) изменена и
требует перемещения строки в другое место.
При обновлении, вставке, удалении многих строк в одном запросе, SQL Server описывает каждый индекс, который был изменён в очереди индексов. Обновление партии строк выполняется на много быстрее, чем обновление каждой строки в отдельном запросе.
Удаление строки связано с индексами и страницами данных. Строка, удалённая из листвы индексов не удаляется напрямую. Она отмечается как неправильная и называется невидимой. Сервер SQL периодически запускает специальный процесс, которые проверяет невидимые строки и удаляет их индексы.
Когда последняя строка удалена из страницы данных, эта страница освобождается. Удалённые в куче строки не объединяются, пока пространство не потребуется для вставки.
Когда строки удалены, файл может быть сжат. Сервер SQL сокращает файл, с помощью перемещения данных в начало файла.
Планирование используемых индексов – одна из главных задач для повышения производительности запросов. Это требует понимания структуры индексов, и как используются данные.
Прежде чем вы создадите индекс, вы должны хорошо понимать данные, включая:
![]() Логическую и физическую структуру;
Логическую и физическую структуру;
![]() Характеристики данных;
Характеристики данных;
![]() Как используются данные. Для создания эффективных индексов, вы
должны хорошо проанализировать запросы, которые посылают пользователи. Плохой
анализ может привести к медленному выполнению запросов и ненужным блокировкам.
Вы должны определить, как пользователи получают доступ к данным наблюдая:
Как используются данные. Для создания эффективных индексов, вы
должны хорошо проанализировать запросы, которые посылают пользователи. Плохой
анализ может привести к медленному выполнению запросов и ненужным блокировкам.
Вы должны определить, как пользователи получают доступ к данным наблюдая:
o Типы выполняемых запросов;
o Частота запросов выполняемых пользователем.
Понимание этого, поможет вам определить, какие колонки надо проиндексировать и какой тип индекса использовать. Вы должны пожертвовать производительностью в одних запросах, чтобы повысить в других.
Ваше бизнес окружение, характеристики данных и использование данных определяют колонки, которые должны быть проиндексированы. Полезность индекса напрямую зависит от процента возвращаемых запросом строк. Маленький или большой процент более эффективен.
Создавайте индексы на колонки, по которым часто происходит поиск, такие как:
![]() Первичный ключ;
Первичный ключ;
![]() Вторичный ключ или колонка, которая часто используется для связи
таблиц;
Вторичный ключ или колонка, которая часто используется для связи
таблиц;
![]() Колонка, используемая для поиска ряда значений;
Колонка, используемая для поиска ряда значений;
![]() Колонка, по которой сортируются данные;
Колонка, по которой сортируются данные;
![]() Колонки, которые группируются во время агрегации.
Колонки, которые группируются во время агрегации.
Не индексируйте колонки:
![]() Редко используемые в запросе;
Редко используемые в запросе;
![]() Содержащие несколько уникальных значений, например колонки,
содержащие только значения мужской или женский пол;
Содержащие несколько уникальных значений, например колонки,
содержащие только значения мужской или женский пол;
![]() Объявленные как text, ntext или image типы данных. Колонки с этими типами данных не могут быть
проиндексированы.
Объявленные как text, ntext или image типы данных. Колонки с этими типами данных не могут быть
проиндексированы.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.