![]() Физический порядок строк в таблице соответствует порядку строк в
индексе. Вы должны создавать кластерный индекс, прежде чем создадите любой не
кластерный индекс, потому что кластерный индекс изменит физический порядок в
таблице. Строка, отсортированная в последовательном порядке, хранится в этом
порядке.
Физический порядок строк в таблице соответствует порядку строк в
индексе. Вы должны создавать кластерный индекс, прежде чем создадите любой не
кластерный индекс, потому что кластерный индекс изменит физический порядок в
таблице. Строка, отсортированная в последовательном порядке, хранится в этом
порядке.
![]() Значения уникальных ключей сохраняются особо, с ключевым словом UNIQUE, или неявно с внутренним уникальным идентификатором.
Этот уникальный идентификатор внутренний для SQL Server и пользователь не может
получить к нему доступ.
Значения уникальных ключей сохраняются особо, с ключевым словом UNIQUE, или неявно с внутренним уникальным идентификатором.
Этот уникальный идентификатор внутренний для SQL Server и пользователь не может
получить к нему доступ.
![]() Средний процент кластерного индекса около 5 процентов размера
таблицы. Однако размер кластерного индекса зависит от размера
проиндексированной колонки.
Средний процент кластерного индекса около 5 процентов размера
таблицы. Однако размер кластерного индекса зависит от размера
проиндексированной колонки.
![]() Когда строка удаляется, пространство освобождается и свободно для
записи новых строк.
Когда строка удаляется, пространство освобождается и свободно для
записи новых строк.
![]() Во время создания индекса, SQL Server временно использует дисковое
пространство из текущей базы данных. Это пространство автоматически
освобождается после создания индекса. Убедитесь, что у вас достаточно
свободного места при создании индекса.
Во время создания индекса, SQL Server временно использует дисковое
пространство из текущей базы данных. Это пространство автоматически
освобождается после создания индекса. Убедитесь, что у вас достаточно
свободного места при создании индекса.
Не кластерные индексы часто используются, когда пользователю требуется несколько способов для поиска данных. Когда вы создаёте не кластерный индекс, рассматривайте следующие замечания и рекомендации:
![]() Если тип индекса не указан, то по умолчанию будет создан не
кластерный индекс;
Если тип индекса не указан, то по умолчанию будет создан не
кластерный индекс;
![]() Сервер SQL автоматически
перестраивает индексы, когда наступает любое из следующего:
Сервер SQL автоматически
перестраивает индексы, когда наступает любое из следующего:
o Существующий кластерный индекс удалён;
o Кластерный индекс создан;
o Опция DROP_EXISTING использовалась для определения кластерного индекса.
![]() Порядок листьев не кластерного индекса не соответствует
физическому порядку в таблице.
Порядок листьев не кластерного индекса не соответствует
физическому порядку в таблице.
![]() Уникальность создаётся на листовом уровне с кластерными ключами
или идентификаторами строки.
Уникальность создаётся на листовом уровне с кластерными ключами
или идентификаторами строки.
![]() Вы можете создавать до 249 индексов на таблицу.
Вы можете создавать до 249 индексов на таблицу.
![]() Создавайте сначала кластерный индекс.
Создавайте сначала кластерный индекс.
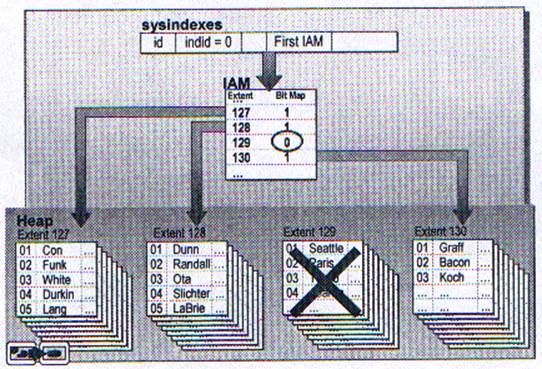
Когда в таблице нет индекса, SQL Server должен использовать сканирование таблицы для получения строк. Сервер SQL использует sysindexes таблице для поиска IAM страниц. Так как IAM страница содержит список всех страниц относящихся к этой таблицы, как битовому массиву пространств по 8 страниц.
Использование сканирования таблицы очень невыгодно, когда нужно найти небольшое количество строк из большой таблицы. Строки возвращаются не отсортированными. После удаления, новые строки вставляются в промежуток делая порядок непредсказуемым.
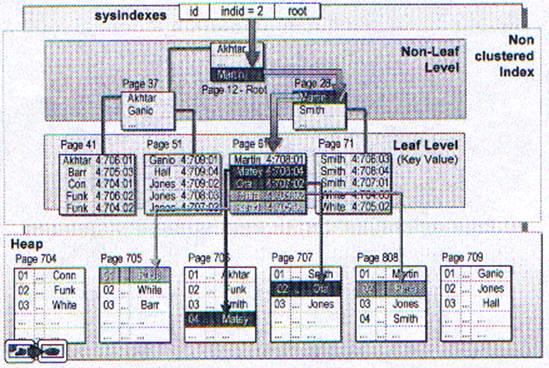
Не кластерный индекс похож на содержание текстовой книги. Данные хранятся в одном месте, а индекс хранится в другом. Указатели показывают расположение проиндексированных данных.
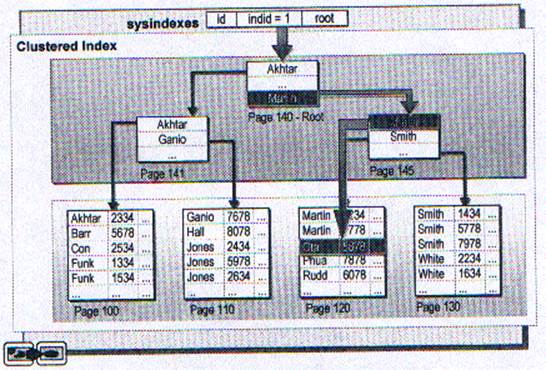
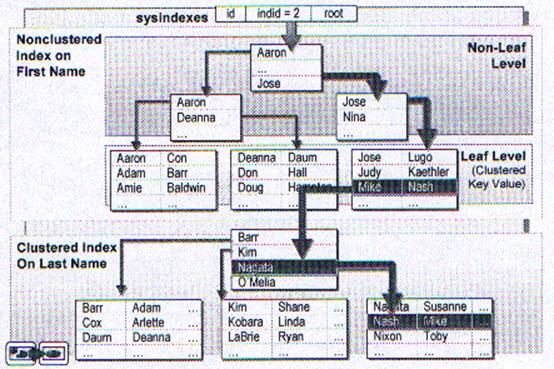
В этой секции обсуждается, как SQL Server поддерживает индексы и кучу во время вставки, редактирования и удаления строк.
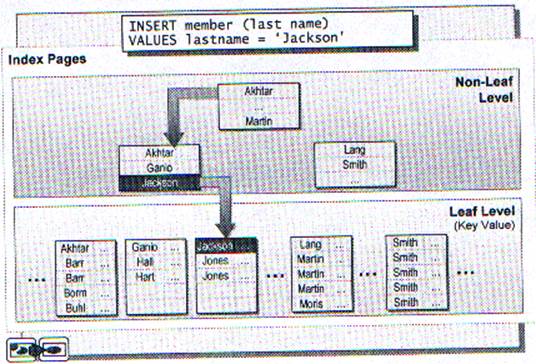
Если страница данных или индексная страница не имеет достаточного пространства для хранения данных, добавляется новая страница. Этот процесс называется разделением страниц. Приблизительно половино данных остаётся в старой странице, а другоая половина перемещается в новую.
Логически, новая страница следует за оригинальной: физически новая страница может занимать любое свободное пространство. Если испытывается большое количество разделённых страниц, то перестройка индекса может повысить производительность.
Разделение страниц не работает в куче. Сервер SQL имеет разные средства управления обновлением или встав, когда страница данных полная.
Вставка новой строки в кучу не может вызвать разделения страницы, потому что новая строка может быть вставлена в любое доступное место.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.