






















































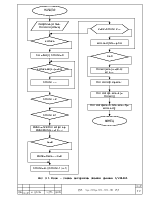


Следовательно, необходимый размер ОЗУ для хранения данных и индексов равен:
Размер блока * 2 + Размер блока *2 + Размер блока = 327675.
Где первое слагаемое – исходные данные продублированные для циклического сдвига, второе слагаемое массив указателей размером 16бит на указатель, третье слагаемое – выходные данные. Для этой цели идеально подходит микросхема статического ОЗУ фирмы «Aeroflex» - ACT-S128K32V.
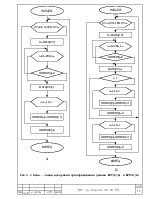
Проектирование операционного и управляющего автомата микропропроцессора проводится на языке описания цифровых устройств – Altera HDL, с последующей компиляцией для размещения в ПЛИС фирмы Altera /6/,/7/.
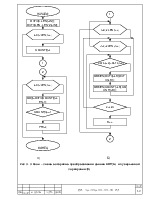
 Самым проблемным местом в любой реализации данного алгоритм является
большое время затрачиваемое на сортировку блока входных данных. Создание специализированного
процессора для сортировки может значительно уменьшить это время. Архитектура
процессора может быть построена на нескольких видах сортировки:
Самым проблемным местом в любой реализации данного алгоритм является
большое время затрачиваемое на сортировку блока входных данных. Создание специализированного
процессора для сортировки может значительно уменьшить это время. Архитектура
процессора может быть построена на нескольких видах сортировки:
1. Сортировка посредством сетей сортировки
2. Быстрая сортировка
3. Сортировка методом «пузырька»
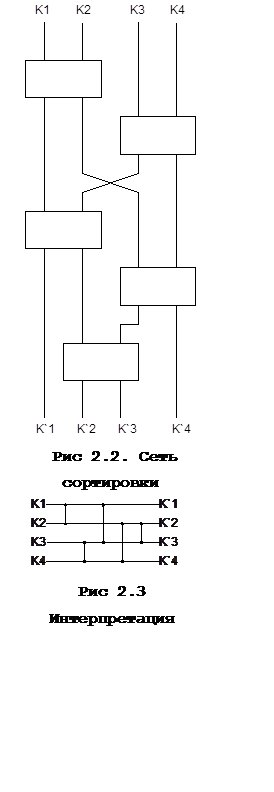
Наиболее предпочтительна по быстродействию сортировка посредством сетей/32/. Сети сортировки класс методов сортировки, удовлетворяющих некоторому ограничению. Это ограничение требует, чтобы последовательность сравнений не зависела от предыстории в том смысле, что если мы сравниваем Кi и Кj, то последующие сравнения для случая Кi < Кj в точности те же, что и для случая Кi > Кj, однако i и j меняются местами.
Простейшая сеть сортировки для 4-х элементов приведена на Рис 2.2 и 2.3. Прямоугольник в подобной сети представляет "модуль компаратора", имеющий два входа (изображены линиями, входящими в модуль сверху) и два выхода (изображены линиями, выходящими вниз); левый выход — меньший из четырёх выходов, а правый выход — больший из них. Элемент К`1 в нижней части сети есть наименьший из {K`1,K`2,K`3,K`4}, К`2 — второй в порядке возрастания и т. д. Технически модуль компаратора довольно легко изготовить. Еще одним важным преимуществом сетей сортировки является то, что часть операций можно совмещать, т. е. выполнять их параллельно. Например, пять шагов на рис 4.1 и 4.2 сокращаются до трех, если организовать одновременные не перекрывающиеся операции сравнения, так как можно объединить первые два и следующие два шага.
Сети сортировки были впервые исследованы Ф. Н. Армстронгом (Р. N. Armstrong), Р. Дж. Нельсоном (R. J. Nelson) и Д. Дж. O' Коннором (D. J. О'Connor) в 1954 году [U.S. Patent 2029413]. Независимо от них К. Э. Бэтчер (К. Е. Batcher) разработал общую стратегию слияния. Используя компараторы, число которых определяется рекурсивным выражением он доказал, что C(2t) = (t2-t+4)2t-2-1.[2.1]
Как Бэтчер, так и Флойд с Кнутом опубликовали свои конструкции лишь через некоторое время. В физических реализациях сетей сортировки и на компьютерах с параллельной архитектурой можно выполнять непересекающиеся операции сравнения-обмена одновременно, поэтому кажется естественным попытаться минимизировать время задержки. Время задержки сети сортировки равно максимальному числу компараторов, расположенных на каком-либо "пути" через сеть, если определить путь как траекторию любого движения слева направо, возможно, с переходом с одной линии на другую через компараторы.
Метод сортировки Бэтчета имеет время задержки T(n)=(1+log2n)* log2n/2 [2.2]
Таблица 2.1 Задержка и количество компараторов в сетях сортировки Бэтчера.
|
n |
4 |
8 |
16 |
32 |
64 |
128 |
256 |
512 |
1024 |
2048 |
4096 |
8192 |
16384 |
32768 |
65536 |
|
T(n) |
3 |
6 |
10 |
15 |
21 |
28 |
36 |
45 |
55 |
66 |
78 |
91 |
105 |
120 |
136 |
|
C(n) |
5 |
19 |
63 |
191 |
543 |
1471 |
3839 |
9727 |
24063 |
58367 |
139263 |
327679 |
761855 |
1753087 |
3997695 |
Из таблицы 2.1 видно, что временная задержка при сортировки блока в 65536 бит равна 136 задержкам компараторов, что при тактовой частоте 66MHz займет только 2040 нс, а если считать, что при реализации данной структуры на ПЛИС задержка распространения сигнала на компаратор составляет 4нс, то потребуется лишь 544нс. Но возникает новая проблема количество компараторов должно равняться 3997695 штук, что недостижимо, даже для самых современных ПЛИС.
Реализация метода быстрой сортировки довольно сложна из-за необходимости организации стека, размером log2n, что значительно усложнит управляющий автомат. Поэтому выбор был остановлен на довольно простом, но медленном алгоритме сортировки по методу «пузырька».
Как уже говорилось выше, самым «узким» местом в данном устройстве является необходимость сортировки довольно длинных контекстов. Соответственно для аппаратной реализации оптимальным будет вариант максимально – уменьшающий время сортировки.
Рассчитаем общее количество операций с учётом, того, что все они выполняются за один такт синхронизации, отбросив время загрузки (выгрузки) данных - интерфейс с шиной и процедуру MTF и используя регистровую блок-схему, приведённую на плакате №5
получим для самого плохого случая следующую формулу ((((17*RG_S)+12)*4095)+1)*RG_S+10*RG_S+1, где RG_S – размер блока данных. При RG_S=65535 (максимальный размер) получаем
298988244914161 операций.
При реализации на шине PCI2.2(66МГц), ПЛИС и использовании статического ОЗУ с задержкой доступа 15нс., нам потребуется
1/66Е6*4784907102846961 = 4484823с для выполнения вычислений.
При реализации на шине PCI2.2(66МГц), процессора DSP56300 с производительностью 150MIPS и использовании статического
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.