Конструирование последовательной DLX
В концЕ этой книги мы разработем конвейерную DLX-машину с точными прерываниями, кэшэм и IEEE-совместимым сопроцессором для операций с плавающей точкой. Отправная точка нашей конструкции - последовательная DLX-машина без обработки прерываний, кэша и сопроцессора для операций с плавающей точкой. Стоимость эффективности более поздних разработок будет сравниваться со стоимостью эффективности этой основной машины.
Почти все разработки из этой главы мы сможем многократно использовать. Процесс разработки будет идти последовательно, строго сверху вниз.
3.1 Архитектура набора команд
МЫ ОПРЕДЕЛИМ набор команд DLX без инструкций для работы с плавающей запятой и обработки прерываний. DLX - RISC архитектура, которая имеет только три формата команд. Она использует 32 регистра общего назначения (универсальных) GPR[j]{31 : 0] для j € {0, ... 31}. Регистр GPR[0] всегда хранит 0.
Операции загрузки и сохранения перемещают данные между универсальными регистрами и памятью М. Существует только один способ адресации: эффективный адрес (effective address) ea равен сумме значения регистра и непосредственной константы. За исключением операций сдвигов, непосредственные константы - всегда знаковые.
|
|
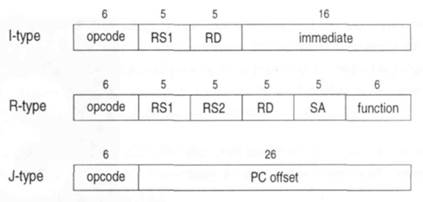
Рисунок 3.1 Три формата команд ядра DLX с фиксированной точкой. RS1 и RS2 - исходные регистры; RD– регистр назначения. SAопределен как регистр специального назначения или непосредственная величина сдвига; function - дополнительный 6-битный код операции.
3.1.1 Форматы команд
Все три формата команд (рисунок 3.1) имеют основной 6-битный код операции и определяют до трех явных операндов. Формат I-type (Immediate) (безотлагательный) определяет два регистра и 16-битную константу. Это стандартный формат для команд с непосредственным операндом. Формат J-type (Jump) (переход) используется для команд управления. Они не требуют явного операнда-регистра и следуют из большого 26-битного непосредственного операнда. Третий формат, формат R-type (Register), обеспечивает дополнительный 6-битный код операции (function). Оставшиеся 20 битов определяют три универсальных регистра и поле SA, которое определяет 5-битную константу или регистр специального назначения. Например, 5-битная константа является достаточной для сдвига.
3.1.2 Кодирование системы команд
Так как описание DLX в [HP90] не определяет кодирование набора команд, мы адаптируем кодирование машины MIPS R2000 ([PH94, KH92]) к системе команд DLX. Таблицы 3.1 - 3.3 описывают для каждой команды DLX ее действие и кодирование; префикс "hx" указывает, что число представлено в шестнадцатеричном виде. Принятые однажды, таблицы - почти, но не совсем - математическое определение семантики машинного языка DLX. Запомните, что математические определения имеют смысл, только если взяты буквально.
Таблица 3.1 Формат команд типа I-type. Все команды, за исключением команд управления, увеличивают PC на четыре; sxt (a) - знаковая версия a. Эффективный адрес доступа к памяти равняется ea = (GPR[RS1]} + (sxt(imm)}, где imm - 16-битный промежуток. Ширина доступа к памяти в байтах обозначена d. Таким образом, операнд памяти равен m = M[ea + d- 1],...,M[ea]
.
|
IR[31 : 26] |
Мнемоника |
d |
Действие |
|
Передача данных |
|||
|
hx20 |
lb |
1 |
RD = sxt(m) |
|
hx21 |
lh |
2 |
RD = sxt(m) |
|
hx23 |
lw |
4 |
RD = m |
|
hx24 |
lbu |
1 |
RD = 024m |
|
hx25 |
lhu |
2 |
RD = 016m |
|
hx28 |
sb |
1 |
m = RD[7 : 0] |
|
hx29 |
sh |
2 |
m = RD[15:0] |
|
hx2b |
sw |
4 |
m = RD |
|
Арифметические, логические операции |
|||
|
hx08 |
addi |
RD = RS1 + imm |
|
|
hx09 |
addi |
RD = RS1 + imm |
|
|
hx0a |
subi |
RD = RS1 - imm |
|
|
hx0b |
subi |
RD = RSl - imm |
|
|
hx0c |
andi |
RD = RS1 /\ sxt(imm) |
|
|
hx0d |
ori |
RD = RS1 \/ sxt(imm) |
|
|
hx0e |
xori |
RD = RS1 @ esxt(imm) |
|
|
hx0f |
lhgi |
RD = imm O16 |
|
|
Операции работы с битами |
|||
|
hx18 |
clri |
RD = ( false ? 1 : 0); |
|
|
hx19 |
sgri |
RD = (RS1 > imm ? 1 : 0); |
|
|
hx1a |
seqi |
RD = (RS1 = imm ? 1 : 0); |
|
|
hx1b |
sgei |
RD = (RS1 >= imm ? 1 : 0); |
|
|
hx1c |
slsi |
RD = (RS1 < imm ? 1 : 0); |
|
|
hx1d |
snei |
RD = (RS1 =/= imm ? 1 : 0); |
|
|
hx1e |
slei |
RD = (RS1 <= imm ? 1 : 0); |
|
|
hx1f |
seti |
RD = ( true ? 1 : 0); |
|
|
Управляющие операции |
|||
|
hx04 |
beqz |
PC = PC + 4 + (RS1 = 0 ? imm: 0) |
|
|
hx05 |
bnez |
PC = PC + 4 + (RS1 =/= 0 ? imm: 0) |
|
|
hx16 |
jr |
PC = RS1 |
|
|
hx17 |
jalr |
R31=PC + 4; PC = RS1 |
|
Таблица 3.2 Формат команд типа R-type. Все команды выполняют PC += 4. SAозначает 5-битное непосредственное количество сдвигов, определяемое битами IR[ 10 : 6].
|
IR[31 :26] |
IR[5 : 0] |
Мнемоника |
Действие |
|
Операции сдвига |
|||
|
hx00 |
hx00 |
slli |
RD = sll(RS1,SA) |
|
hx00 |
hx02 |
srli |
RD = srl(RS1,SA) |
|
hx00 |
hx03 |
srai |
RD = sra(RS1,SA) |
|
hx00 |
hx04 |
sll |
RD = sll(RS1,RS2[4:0]) |
|
hx00 |
hx06 |
srl |
RD = srl(RS1,RS2[4:0]) |
|
hx00 |
hx07 |
sra |
RD = sra(RS1,RS2[4:0]) |
|
Арифметические, логические операции |
|||
|
hx00 |
hx20 |
add |
RD = RS1 +RS2 |
|
hx00 |
hx21 |
add |
RD = RS1+RS2 |
|
hx00 |
hx22 |
sub |
RD = RS1-RS2 |
|
hx00 |
hx23 |
sub |
RD = RS1-RS2 |
|
hx00 |
hx24 |
and |
RD = RS1 /\ RS2 |
|
hx00 |
hx25 |
or |
RD = RS1\/ RS2 |
|
hx00 |
hx26 |
xor |
RD = RS @ RS2 |
|
hx00 |
hx27 |
lhg |
RD = RS2[15:0]016 |
|
Операции работы с битами |
|||
|
hx00 |
hx28 |
clr |
RD = ( false ? 1 : 0); |
|
hx00 |
hx29 |
sgr |
RD = (RS1 > RS2 ? 1 : 0); |
|
hx00 |
hx2a |
seq |
RD = (RS1 = RS2 ? 1 : 0); |
|
hx00 |
hx2b |
sge |
RD = (RS1 >= RS2 ? 1 : 0); |
|
hx00 |
hx2c |
sls |
RD = (RS1 < RS2 ? 1 : 0); |
|
hx00 |
hx2d |
sne |
RD = (RS1 =/= RS2 ? 1 : 0); |
|
hx00 |
hx2e |
sle |
RD = (RS1 <= RS2 ? 1 : 0); |
|
hx00 |
hx2f |
set |
RD = ( true ? 1 : 0); |
Таблица 3.3 Формат команд типа J-type, sxt(imm) – знаковая версия 26-бит, непосредственно называемая PC offset (смещение).
|
IR[31 : 26] |
Мнемоника |
Действие |
||
|
Операции управления |
||||
|
hx02 hx03 |
j jal |
PC = PC + 4 + R31=PC + 4; |
sxt(imm) PC = PC |
+ 4 + sxt(imm) |
Итак, попробуем выполнить действие
RD = (RS1 > imm? 1: 0)
принадлежащее команде beqz из таблицы 3.1 буквально: 5-битная строка RS1 сравнивается с 16-разрядной строкой imm используя сравнение ">", которое не применимо для таких пар строк. 1-битный результат сравнения присвоен 5-битной строке RD.
Этот беспорядок может быть остановлен соблюдением пяти правил, определяющих сокращения и соглашения, которые используются в таблицах.
1. RD - сокращение для GPR[RD]. Строго говоря, фактически это сокращение для GPR[(RD)]. То же самое верно для R1 и R2.
2. За исключением логических операций, непосредственные константы imm - всегда двоичные дополнительные числа.
3. В арифметических операциях и в операциях работы с битами уравнения работают с двоичными дополнительными числами.
4. Вся целочисленная арифметика по модулю 232. Она включает вычисления всех адресов и, в частности, все вычисления, затрагивающие PC.
Из Леммы 2.2 мы знаем, что [a] = (a) mod 232 для 32-битных адресов a. Таким образом, последнее соглашение подразумевает, что не имеет значения, интерпретируем ли мы адреса как двоичные дополнительные числа или как двоичные числа.
Цель сокращений и соглашений состоит в том, чтобы превратить длинные описания в короткие. В таблицах 3.1 - 3.3 это было сделано весьма успешно. Сейчас мы перечислим почти несокращенную семантику трех команд DLX, где sxt (imm) означает 32-разрядную знаковую версию imm.
1. Арифметическая команда addi:
[GPR[RD]] = [GPR[RS1]] + imm mod 232
= [GPR[RS1]] + [sxt(imm)].
2. Команда работы с битами sgri:
[GPR[RD]] = [([GPR[RS1]] > [imm] ?1:0)],
или, что тоже самое
GPR[RD] = 031 ([GPR[RS1]] > [sxt(imm)] ?1:0).
3. Команда ветвления beqz:
(PC) = (PC) +4+ ([GPR[RS1]] > 0 ? [imm]: 0) mod 232 = (PC) + 4 + ([GPR[RS1]] > 0 ? [sxt(imm)] : 0) mod 232.
Видно, что в более детальных уравнениях стало видно множество подсказок для реализации команд: непосредственные константы должны быть знаковыми а 1-битный результат тестов должен быть дополнен 31 нулем.
3.1.3 Организация памяти
Память – байтоадресуемая, то есть, каждый адрес памяти j определяет расположение ячейки памяти M[j], способной сохранить один байт. Память выполняет доступ к байту, пулуслову и слову. Все команды закодированы четырьмя байтами. В памяти данные и команды выровнены в следующем виде:
• полуслово должно иметь четные адреса (в байтах). Полуслово h с адресом e хранится в памяти таким образом:
h[15:0] = M[e+1 : e].
• слова или команды должны иметь адреса (в байтах), делимые на четыре. Эти адреса называются границами слова. Слово или команда w с адресом e хранится в памяти таким образом:
w[31:0] = M[e + 3:e].
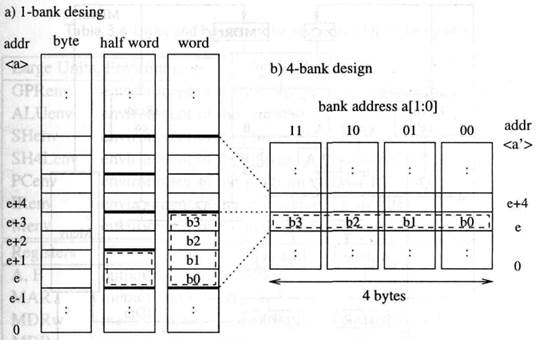
Критическая особенность этой схемы хранения в том, что полуслова, слова и команды сохраненные в памяти, никогда не пересекают границы слова (см. рисунок 3.2). Для границ слова e, мы определяем слово памяти с адресом e как
Mword[e] =M[e + 3:e].
Кроме того, мы нумеруем байты слов w [31: 0] в порядке “меньший в конце”
(рисунок 3.3), то есть:
bytej(w) = w[8j + 7:8j]
byte[i,:j](w) = bytei(w)...bytej(w)
Эти определения непосредственно подразумевают следующую лемму:
Лемма 3.1> Пусть (a[31 : 0]) - адрес памяти и пусть e – граница слова e = (a[31 :2]00). Тогда
1.байт с адресом (a) хранится в байте (a[1 : 0]) слова памяти с адресом e:
M((a)) = byte(a[1:0]}(Mword[(a[31 : 2]00)]).
|
|
Рисунок 3.2 Схема хранения в системе памяти с 1-банком (a) и с 4-банками (b). Банк всегда имеет ширину в один байт. a' = (a[31 : 2] 00) и e = (a').

Рисунок 3.3 Размещение байтов в пределах слова w[31 : 0] – порядок “little endian” (меньший в конце)
2. Часть данных шириной d-байт и имеющих адрес (a) хранится в байтах с (a[1 : 0]) по (a[1 : 0]) + d — 1 слова памяти с адресом e:
byte[(a[1:0])+d-1:(a[1:0])](Mword[(a[31 : 2]00)]).
3.2 Высокоуровневые пути данных
Рисунок 3.4 представляет высокоуровневый вид путей данных в машине. Он показывает шины, буфера, регистры, схемы проверки на ноль, мультиплексоры и окружения (environments). Окружения названы по имени некоторого главного модуля или регистра. Они содержат этот модуль или регистр плюс некоторую склеивающую логику (gluelogic), которая необходима для адаптирования этого
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.