Индекс- линейный список с последовательном распределением памяти.
Элементы индекса – 1. значение элемента (узла) списка
2.адрес, где находиться элемент списка
2 список Линейный список со связанным распределением памяти
Необходимо найти Yк = 10 000 N = 106
1. Последовательный перебор элементов связанного списка 104 загрузок в ОЗУ
2. Составление конструкции
1. Ищем в индексе по формуле α (к) = β + (к-1) m => алгоритм в ОЗУ
2. По ссылке находим элемент Yк и загружаем его в ОЗУ для выполнения операций модификации или удаления =>т.е. вместе 104 загрузок в ОЗУ мы делаем 1 загрузку . Выигрываем в скорости 104 операций загрузку в ОЗУ.
Итак, в предыдущей лекции мы зафиксировали , что методы вычисления адреса представлены двумя группами:
1 группа методов – это методы, в которых адресная функция реализует взаимно однозначное соответствие адресов и ключей.
2 группа методов – это методы, в которых адресная функция реализует только однозначное преобразование ключа в адрес, обратные преобразования обычно не имеют места.
6.3.1.Методы 2 группы
Методы этой группы носят название - методы рандомизации или методы хеширования. Они основаны на вероятностных алгоритмах. Поясним эту мысль на таком примере.
Пусть у нас есть двухмерное пространство с координатами Х и У.
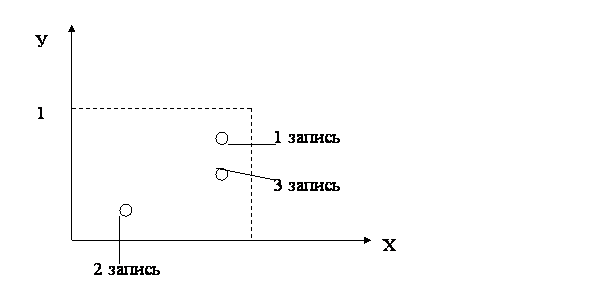
По координатам Х и У мы имеем генераторы случайных чисел (ГСЧ) в диапазоне значений от 0 до 1.
В результате работы ГСЧ будет заполнено всю плоскость адресного пространства. Однако адресное пространство будет заполняться неупорядоченно, т.е. адреса последовательных записей файла будут размещаться то в конце адресного пространства то середине, а затем опять в конце.
Адресная функция построенная на вероятностных алгоритмах называется хеш – функцией.
Методы построения хеш – функцией
Различают следующие методы построения хеш – функций:
1. метод квадратов;
2. метод деления;
3. метод умножения;
4. метод сдвига разрядов;
5. метод преобразования основания системы счисления;
6. метод деления полиномов.
Мы с вами рассмотрим метод деления.
Обозначим через key – значение ключа записи, тогда
h (key) = mod (key,m)
где h (key) – значение хеш – функции
m – число, близкое к размеру N участка памяти, отдельное для размещения записей файла.
mod (key,m) – остаток от деления значение ключа на размер участка памяти.
В качестве m рекомендуется выбрать простое число, близкое к размеру участка памяти.
Метод деления дает хорошие результаты для реальных файлов.
Пример Если число участков равно 7 000, то в качестве делителя можно использовать число 6997.
Пусть ключ записи равен 172 148 остаток от деления 4220.
Это будет относительный адрес памяти, в который направляется запись с ключом 172 148.
Выбор алгоритма хеширования
Наиболее приемлемый алгоритм хеширования выбирают следующим образом: берут достаточно представительный набор ключей файла, и применяют к нему все возможные алгоритмы перемешивания и определяют число записей, которые будут иметь одинаковые адреса, т.е. случаи возникновения коллизий.
Исследования показали, что лучшие результаты получаются в том случае, когда применяется метод деления.
Методы разрешения коллизий
1. метод открытой адресации;
2. метод цепочек.
Метод открытой адресации
Пусть у нас есть хеш – функция mod (key,1000)
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.