Тема 6 :Физическое представлене данных.
6.1 Общие положения
Современные СУБД обладают высоким быстродействием поиска информации. Базы данных, имеющие мощность (т.е. количество записей) до ≈ 106 дают скорость только ≈ 2 сек. за счет чего, это быстродействие реализуется .В настоящее время существует 2 пути:
1. Использование языка SQL – для реализации запросов
SQL является реляционным языком, использующим элементы реляционной алгебры и реляционного исчисления кортежей.
В реляционных системах запросов существует возможность выбора эффективной стратегии для вычисления реляционного выражения с помощью которого сформирован запрос.
Этот процесс – выбор эффективной стратегии вычислений выполняет оптимизатор. Он позволяет в отдельных случаях, сократить количество операций, которые необходимо произвести для организации поиска на 4 порядка т.е. в 10 000 раз. То есть мы имеем редкое увеличения скорости 104 раза., т.е. поиск старым оператором языка и SQL выиграл в 104 раза. Изучая обработку данных с помощью ЭВМ мы постепенно обращаемся к трем выделенным областям:
1. реальному миру;
2. информации;
3. данным.
Между этими тремя областями существуют определенные взаимосвязи. Тема рассматриваемая сегодня имеет отношение к 3 – й области – к области данных.
А область данных, как вы помните состоит из 3-х компонент:
3.1. Общая логическая структура данных (или данные в представлении администратора данных);
3.2. Данные в представлении программиста;
3.3.Представление данных в памяти ЭВМ.
Т.е. логическая структура данных и представление этой структуры в памяти ЭВМ это два важных, но различных между собой понятия.
Логические структуры данных это:
· реляционные;
· древовидные;
· сетевые структуры.
Что касается представления данных в памяти, то существует два метода :
Первый метод заключается в том, что каждому элементу данных указывается адрес памяти ЭВМ. Размещение данных (т.е. их запоминание) и их выборка осуществляется по известному адресу.
Второй метод заключается в том, что содержание ключа конкретной записи преобразуется определенным методом (существует несколько методов) в адрес памяти ЭВМ. В этом случае размещение данных и их выборка осуществляются по известному значению ключа, т.е. определяются по содержимым самих данных. Этот случай хорошо реализуется в ассоциативной памяти ЭВМ или с помощью специального программного обеспечения в обычной памяти ЭВМ.
Для первого и второго метода существует общая проблема – как эффективно отобразить логическую структуру данных на физическую структуру хранения.
Т.е. речь идет о нахождении адресной функции, которая позволяла бы быстро вычислять где хранятся необходимые данные.
6.2. 1 –й метод представления данных в памяти ЭВМ.
6.2.1. Последовательное распределение памяти.
Пусть у нас есть определенный тип записи с экземпляром записей У1, У2,…, Уп.
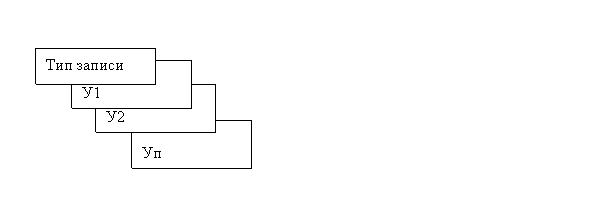
Будем считать, что запись, состоящая из элементов данных, хранится целиком и разделение на атрибуты или элементы данных происходит после выборки записи.
Такую структуру можно определить как линейное упорядочение записей, т.е. номера записей следуют один за другим или линейный список.
В такой структуре каждая запись идентифицирована своим порядковым номером. Обозначим через:
N – количество записей в списке
m- размер записей в байтах
β – адрес базы, указывающий на начало вектора данных в памяти
i – текущая запись в списке
α – адрес физической памяти.
В этом случае адрес каждой записи можно вычислить с помощью адресной функции, отображающий логический индекс, идентифицирующий адрес в структуре, в адрес физической памяти.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.




