Министерство Образования РФ
Российский государственный гидрометеорологический университет
Обработка данных программой Serfer.
Выполнила: с-т гр. МО-512
Маслов П.А.
Проверил: Сычев В. И.
Санкт-Петербург
2009г.
Цели и задачи: целью данной работы является обучение методам восстановления данных в узлы регулярной сетки из промежуточных точек. Так же сравнение трех наиболее популярных метода между собой.
Исходные данные: в качестве исходных данных взяты среднегодовые значения температуры в северной Атлантике за 1990г.
Исходный ряд температур имеет следующие статистические характеристики, по ним в дальнейшем будет проводиться оценка методов восстановления.
Data Counts
Active Data: 64
Original Data: 64
Excluded Data: 0
Deleted Duplicates: 0
Retained Duplicates: 0
Artificial Data: 0
Superseded Data: 0
Minimum: 4
Maximum: 27.3
Mean: 17.2778125
Standard Deviation: 7.0285172
Variance 49.400054
Первым был использован наиболее распространенный метод Kriging и получено следующее распределение:
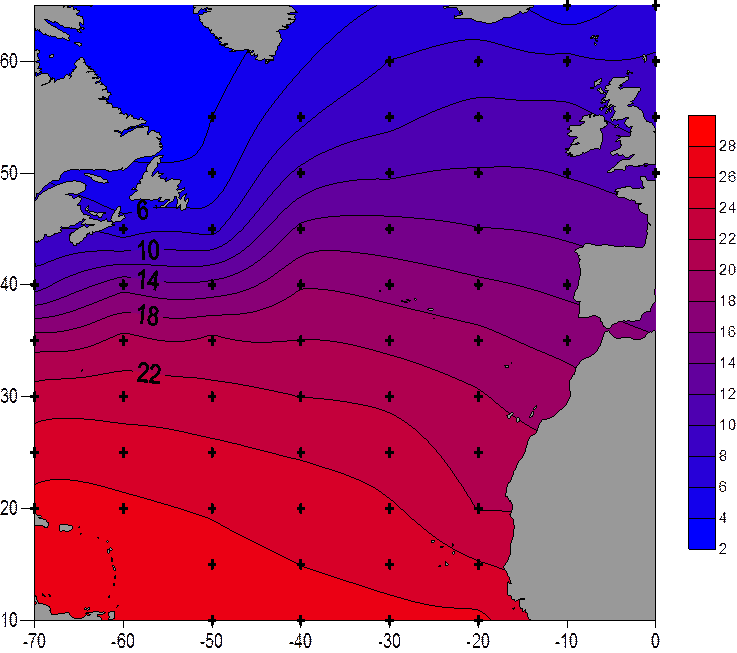
Grid File Name: E:\йцукен\Laba_Sich.grd
Grid Size: 56 rows x 71 columns
Total Nodes: 3976
Filled Nodes: 3976
Blanked Nodes: 0
Minimum: 2.0433247631441
Maximum: 27.845847661886
Mean: 16.140848109144
Standard Deviation: 7.7010081028066
Variance: 59.305525799493
Сравнивая статистически характеристики восстановленного ряда можно отметить следующие различия: первое это понижение минимального значения на 2 , а среднего примерно на 1 , увеличилась дисперсия и изменчивость. Несмотря на эти изменения, которые говорят о некачественном восстановлении, данный метод не плох, так как отмеченные изменения не являются принципиально большими, зато визуально, очень хорошее распределение.
Следующий метод Triangulation with Linear Interpolation.
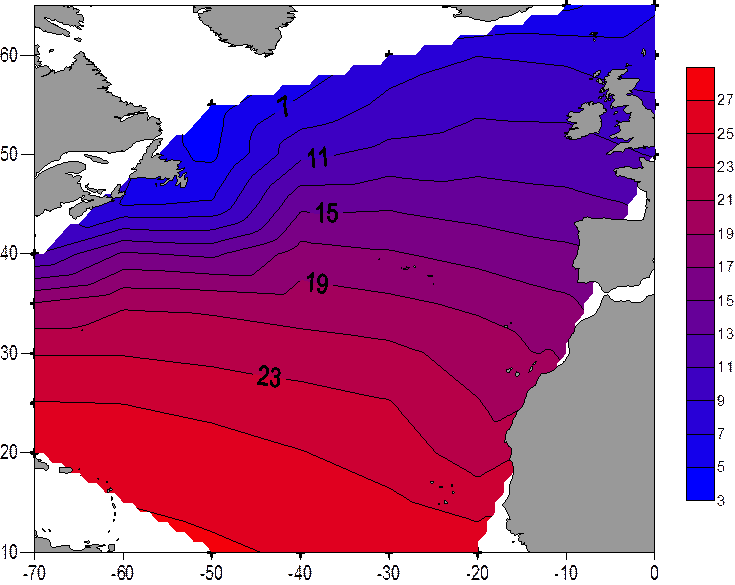
Grid File Name: E:\йцукен\Laba_Sich2.grd
Grid Size: 56 rows x 71 columns
Total Nodes: 3976
Filled Nodes: 2861
Blanked Nodes: 1115
Minimum: 4
Maximum: 27.3
Mean: 17.439575323314
Standard Deviation: 6.5903563478
Variance: 43.432796790988
Главное, что хочется отметить в данном методе то, что после восстановления для новых данных все статистические характеристики остались неизменными, однако визуальное распределение значительно уступает рассмотренному ранее методу Kriging.
Последний из рассматриваемых методов Inverse Distance to a Power
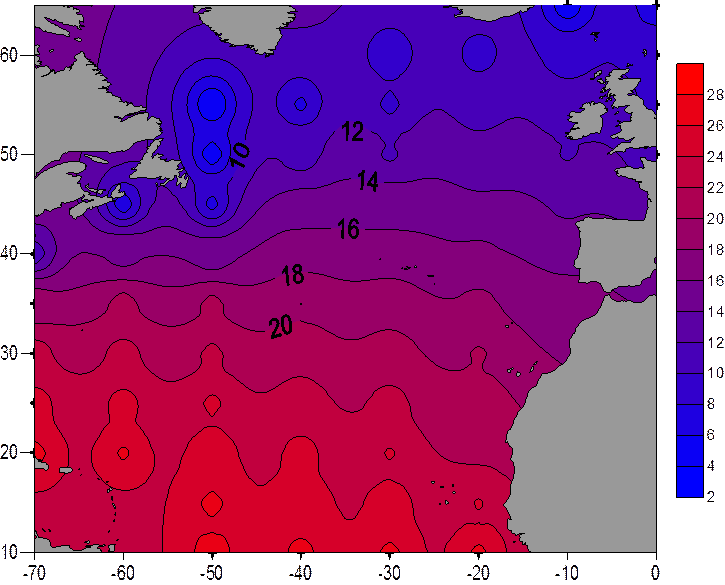
Grid File Name: E:\йцукен\Laba_Sich3.grd
Grid Size: 56 rows x 71 columns
Total Nodes: 3976
Filled Nodes: 3976
Blanked Nodes: 0
Minimum: 4
Maximum: 27.3
Mean: 17.007571740369
Standard Deviation: 5.1088867771986
Variance: 26.100724102235
В данном методе отмечается сохранение значений максимума, минимума и среднего значения. Однако, произошло уменьшение дисперсии и изменчивости, что говорит о хорошем восстановление и о том, что этим данным можно доверять. Визуально же распределение вызывает сомнения в его достоверности.
Вывод:
Обобщая рассмотренные методы, можно сделать следующее заключение. Если требуется восстановить данные при этом не потеряв их общих статистических значений, или потери были не значительны, то тогда лучше всего использовать 2 и 3 методы. Если требуется хорошая, достоверная картинка, тогда лучше всего использовать 1 метод. Но при этом для получения данных высокого качества и надежности, для всех методов одинаково важно количество точек с исходной информацией, их не должно быть много меньше, чем точек восстановления и так же важно их расположение по отношению к восстанавливаемой области, они должны равномерно достаточно плотно покрывать ее.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.