Якщо спочатку результати, одержані методами класичної математичної статистики, утворювали тільки інформаційну базу, на основі якої дослідник приймав рішення про стан об’єкту, що спостерігався, то з початком комп’ютерної ери в розвитку людства, який припадає на середину XX століття, з’явилася можливість моделювання на ЕОМ розумових процесів, притаманних людині при прйнятті рішень. У міру значного прогресу в розвитку комп’ютерних інформаційних технологій наприкінці XX століття в рамках математичної статистики сформувався новий розділ “Аналіз даних”, який ґрунтується на статистичному аналізі вибіркових послідовностей ознак розпізнавання і спрямований на вирішення проблеми інформаційного синтезу ефективних СППР, що навчаються (самонавчаються). Оскільки основною функцією СППР є класифікація даних, які відображають властивості об’єкта класифікації (ОК), то за цим розділом останнім часом закріпилася назва “Класифікаційний аналіз даних” (КАД), яка здебільшого враховує його специфіку і конкретизує предмет навчальної дисципліни. Основні типові задачі КАД, які наведено на рис.В.1, спрямовані як на вирішення основної проблеми багатовимірного статистичного аналізу: виявити та скласти опис існуючих між показниками подій, що спостерігаються, статистичних взаємозв’язків, так і безпосередньо на вирішення проблеми синтезу СППР.
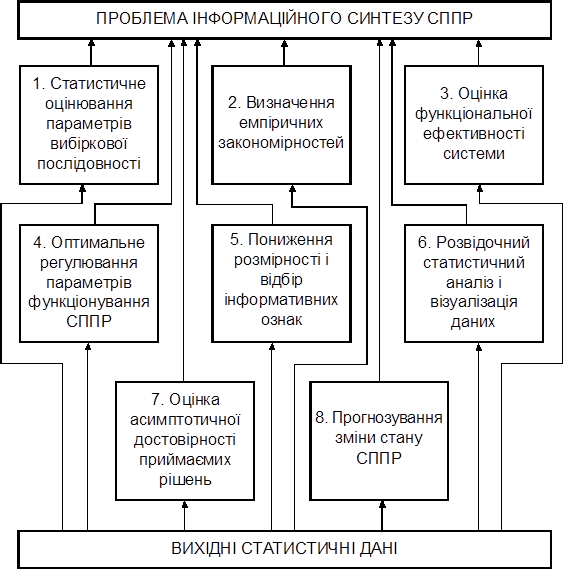
Рисунок В.1 – Типові задачі КАД
Взагалі залежно від вхідних даних і уявлень про побудову та функціонування складної системи існує три класи задач синтезу:
· інформаційний синтез, який передбачає оптимізацію (в інформаційному сенсі) поведінки та алгоритмів функціонування СППР;
· структурний синтез СППР при заданих алгоритмах її функціонування;
· узагальнений синтез структури та алгоритмів функціонування СППР, розподіл функцій за елементами системи та визначення їх оптимального складу.
Якщо при інформаційному синтезі як критерій оптимізації використовується безпосередньо інформаційний критерій функціональної ефективності (КФЕ) системи, то при узагальненому синтезі він є обов’язковою складовою частиною узагальненого КФЕ[ ].
Перша
і друга задачі КАД є типовими
задачами математичної статистики. Специфіка другої задачі полягає в тому, що
для аналізу результатів спостережень за множиною об’єктів ![]()
![]() з метою виявлення
емпіричних закономірностей даних розглядаються тільки такі багатовимірні
структури, які можуть бути подані або у вигляді матриць «об’єкт-властивість» для
кожного об’єкта, або у вигляді матриць відношень (попарних порівнянь)
між об’єктами. Звичайно матриця «об’єкт-властивість» є двовимірною, тобто
з метою виявлення
емпіричних закономірностей даних розглядаються тільки такі багатовимірні
структури, які можуть бути подані або у вигляді матриць «об’єкт-властивість» для
кожного об’єкта, або у вигляді матриць відношень (попарних порівнянь)
між об’єктами. Звичайно матриця «об’єкт-властивість» є двовимірною, тобто ![]()
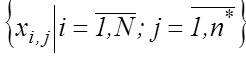 , де xi,j-
вибіркове значення
, де xi,j-
вибіркове значення ![]() -ї ознаки розпізнавання,
здобутої при
-ї ознаки розпізнавання,
здобутої при ![]() -му
спостереженні;
-му
спостереженні; ![]() -
кількість ознак розпізнавання;
-
кількість ознак розпізнавання; ![]() - кількість
спостережень, яка забезпечує достатню репрезентативність вибіркової
послідовності. У загальному випадку матриця «об’єкт-властивість» може бути тривимірною
(наприклад, при квантуванні значень ознак розпізнавання у часі) і чотиривимірною
(при квантуванні як у часі, так і за рівнем).
- кількість
спостережень, яка забезпечує достатню репрезентативність вибіркової
послідовності. У загальному випадку матриця «об’єкт-властивість» може бути тривимірною
(наприклад, при квантуванні значень ознак розпізнавання у часі) і чотиривимірною
(при квантуванні як у часі, так і за рівнем).
У матриці відношень ![]() елемент аk,l визначає результат зіставлення
об’єктів
елемент аk,l визначає результат зіставлення
об’єктів ![]() i
i ![]() в
сенсі деякого заданого відношення: схожості (відмінності), взаємозв’язку,
переваги, відстані та інше.
в
сенсі деякого заданого відношення: схожості (відмінності), взаємозв’язку,
переваги, відстані та інше.
Визначення В.2 Закономірність - це сталість параметрів та характеристик, що відображають властивості об’єкту дослідження і його взаємозв’язки з іншими об’єктами, системами та явищами.
Поряд з такими видами взаємозв’язків між компонентами багатовимірної структури даних, як кількісні, некількісні (якісні), змішані (різновидові) і порядкові, які досліджуються класичними методами статистичного аналізу, об’єктом дослідження класифікаційного аналізу даних є насамперед класифікаційний взаємозв’язок. Саме цей тип взаємозв’язку дозволяє розбивати досліджувану множину об’єктів на підмножини, які перебувають між собою у певному відношенні еквівалентності. Наприклад, для класифікаційної періодичної системи хімічних елементів Менделєєва таким відношенням еквівалентності є заряд атомного ядра елемента.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.