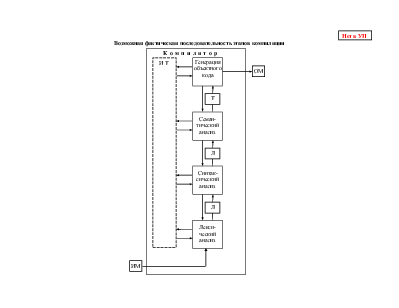
Возможная фактическая последовательность этапов компиляции
 |
|||
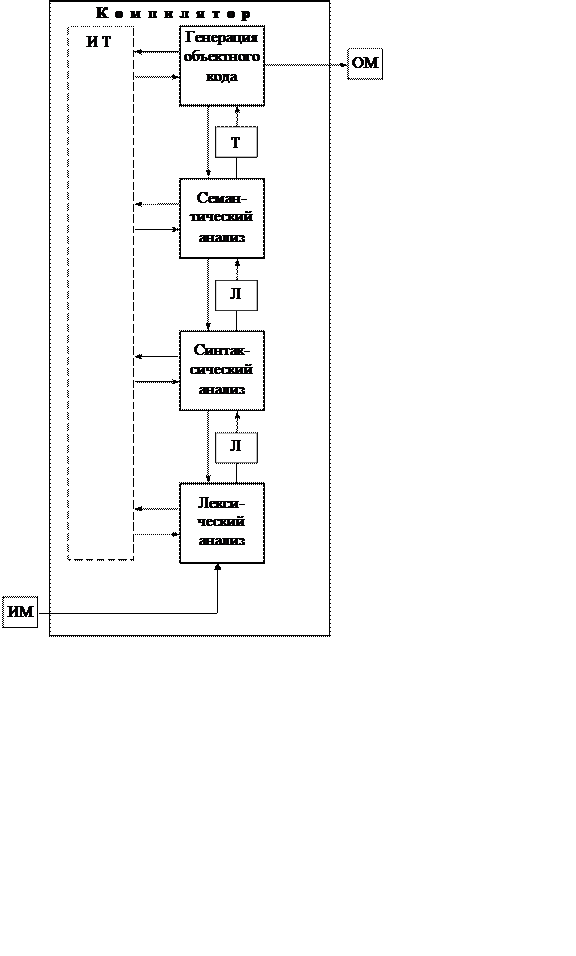
Обычная фактическая последовательность этапов компиляции
 |
Последовательность этапов работы интерпретатора
 |
|||
Системы автоматизации проектирования трансляторов.
Lex/Yacc, Flex/Bison, PCCTS, ANTLR, LLGEN, JavaCC …
|
|
|
 Учебный пакет автоматизации
проектирования трансляторов ВебТрансЛаб:
Учебный пакет автоматизации
проектирования трансляторов ВебТрансЛаб:
Лексический анализ
Постановка задачи
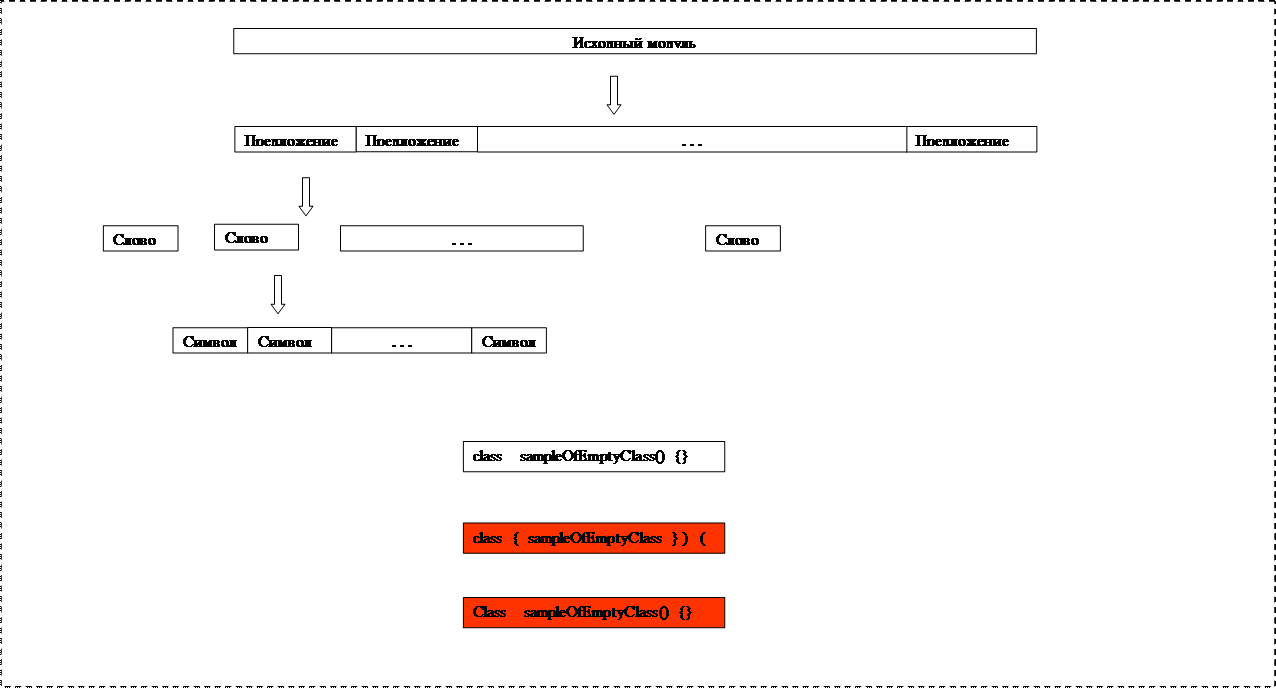 |
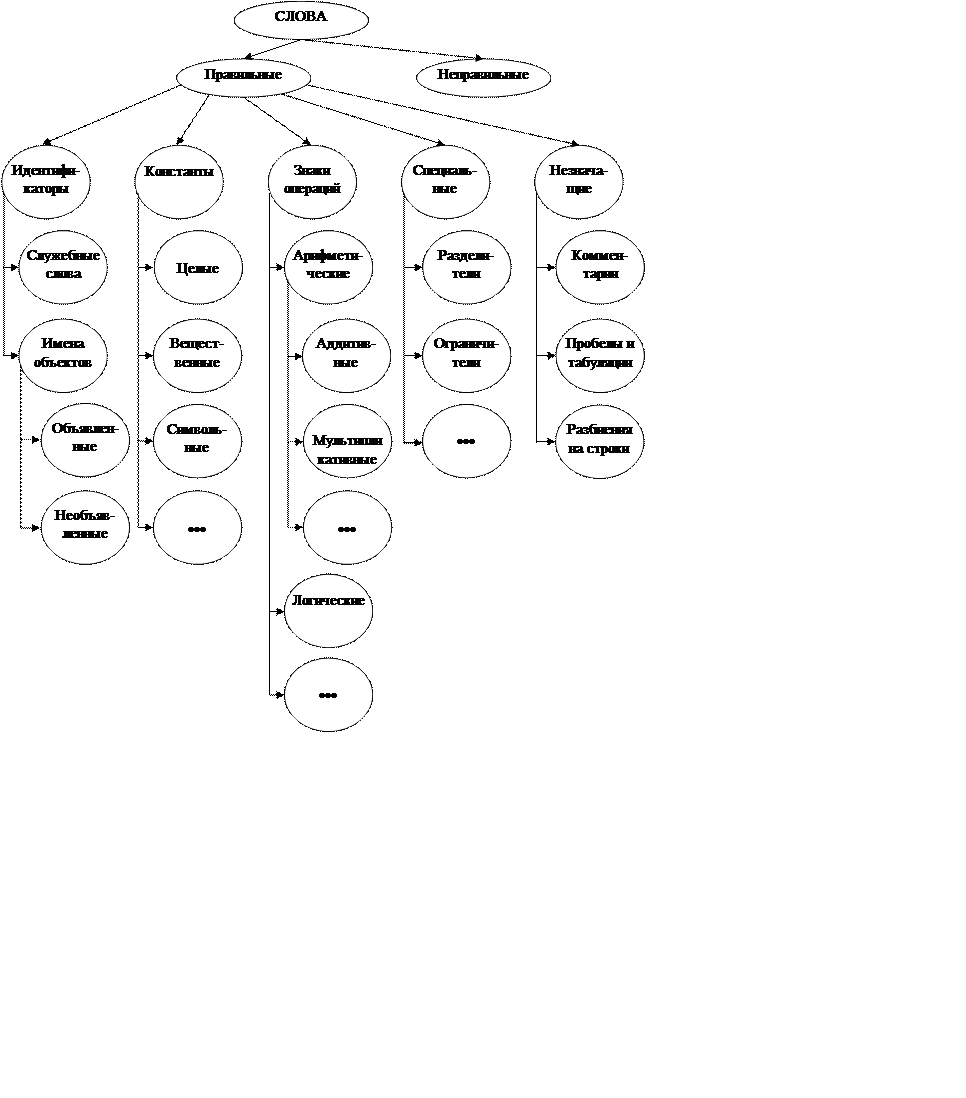
Алфавит языка. Символы. Цепочки символов. Пустая цепочка ε
Слова – цепочки символов, удовлетворяющие лексическим правилам.
Предопределенные слова.
Определяемые слова.
 |
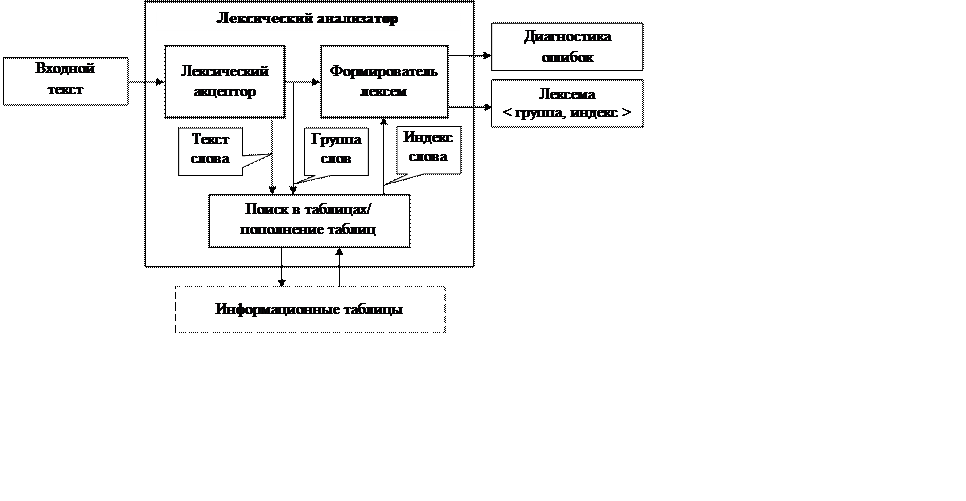
Структура лексического анализатора
 |
1. Процедурный
2. Автоматный
Процедурный способ реализации
Рассматривается на примере лексического анализатора для объектно-ориентированного языка JavaScript интерпретатора Rhino (носорог), встроенного в браузер Mozilla Firefox.
https://developer.mozilla.org/en/Rhino (сентябрь 2011)
ftp://ftp.mozilla.org/pub/mozilla.org/js/rhino1_7R2.zip (март 2011)
Лексический анализ в интерпретаторе Rhino реализован в классе TokenStream. Метод getToken(), код которого приводится для иллюстрации, по существу представляет собой лексический акцептор.
… //опущено: блок комментариев описания лицензии
packageorg.mozilla.javascript;
import java.io.*;
/**
* This class implements the JavaScript scanner.
*
* It is based on the C source files jsscan.c and jsscan.h
* in the jsref package.
*
* @see org.mozilla.javascript.Parser
*
* @author Mike McCabe
* @author Brendan Eich
*/
classTokenStream {
//опущено: методы, прямо не связанные с изучаемым материалом
finalintgetToken() throwsIOException { //прочитать очередное слово и вернуть код группы слов token
intc; //локальная переменная, хранящая код текущей литеры
retry:
for (;;) { //основной цикл чтения литер очередного слова
for (;;) { //подавить все незначащие символы кроме EOF (EndOfFile) и EOL(EndOfLine)
c = getChar(); //прочитать очередную литеру; заметим, что возврат каретки ‘\r’ подавляется методом getChar
if (c == EOF_CHAR) {
return Token.EOF; //вернуть лексему EOF
} else if (c == '\n') {
dirtyLine = false; //строка текста не содержала ничего, кроме незначащих символов
returnToken.EOL; //вернуть лексему EOL
} elseif (!isJSSpace(c)) { //частный метод isJSSpace возвращает истину, если его аргумент - пробел (0x20),
//табуляция (0x9), литера с одним из кодов 0xC, 0xB, 0xA0 или имеет категорию
//Zs (SPACE_SEPARATOR) согласно спецификации Unicode
if (c != '-') { //возможно, обрабатывается конец комментария в стиле HTML: -->
dirtyLine = true;
}
break;
}
}
// identifier/keyword/instanceof? watch out for starting with a <backslash>
booleanidentifierStart; //флажок начала идентификатора (или служебного слова или instanceof)
booleanisUnicodeEscapeStart = false; //флажок начала escape-последовательности
if (c == '\\') { //если первая литера – это \
c = getChar(); //читать следующую литеру
if (c == 'u') { //и если это литера u
identifierStart = true; //то взвести флажки
isUnicodeEscapeStart = true;
stringBufferTop = 0; //и подготовить символьный буфер к накоплению литер слова
} else { //иначе сбросить флажки, возвратить прочитанную литеру на вход
identifierStart = false;
ungetChar(c);
c = '\\'; //и сделать вид, что со входа ничего не читалось
}
} else { //если литера не «\», то проверить, может ли с нее начинаться идентификатор, если да – взвести флажок
identifierStart = Character.isJavaIdentifierStart((char)c);
if (identifierStart) {
stringBufferTop = 0; //подготовить буфер к приему слова
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.