Рассмотрим пример исправления однократной ошибки.
Пусть комбинация CRC-кода (7,4) 1001110,
сформированная с помощью образующего полинома ![]() ,
принята с ошибкой в третьем разряде: 1011110.
,
принята с ошибкой в третьем разряде: 1011110.
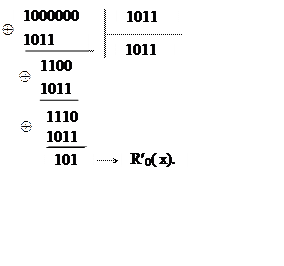
Для исправления ошибки находим
выделенный синдром ![]() , выполняя деление полинома
ошибки в старшем разряде
, выполняя деление полинома
ошибки в старшем разряде ![]() на образующий
полином
на образующий
полином ![]() в двоичном эквиваленте:
в двоичном эквиваленте:
 |
Находим остатки ![]() от деления принятой кодовой комбинации
на двоичный эквивалент образующего полинома
от деления принятой кодовой комбинации
на двоичный эквивалент образующего полинома![]() :
:
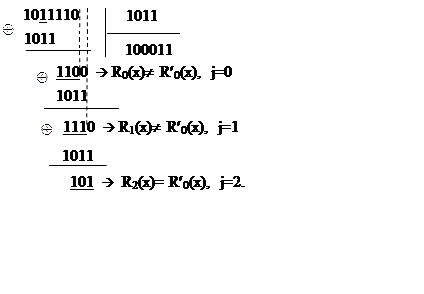 |
Остаток от деления совпал с ![]() после двух сдвигов (
после двух сдвигов (![]() =2). Следовательно, искажен символ
=2). Следовательно, искажен символ ![]() , что соответствует условию примера.
, что соответствует условию примера.
В общем случае декодирующее устройство содержит буферный регистр БР, схему деления на образующий полином СД, детектор ошибки ДО и сумматор коррекции СК (рис.3).
Декодирование осуществляется за 2n тактов. В течение первых n тактов кодовая комбинация
записывается в БР, а в СД формируется остаток ![]() от
деления принимаемой комбинации на образующий полином
от
деления принимаемой комбинации на образующий полином ![]() .
.
Исправление происходит в течение
последующих n тактов,
когда в БР продолжаются сдвиги. При этом ошибка перемещается к выходу БР, а в
СД продолжается деление сдвигаемой комбинации (ключ K разомкнут, и на вход СД поступают «нули»), и на
ДО, представляющий собой логическую схему, настроенную на выделенный синдром ![]() , поступают остатки
, поступают остатки ![]() . В момент, когда ошибка окажется в
старшем n-м разряде БР, на выходе СД
образуется выделенный синдром, ДО выдает сигнал «1», который поступает на СК,
изменяя значения очередного символа, поступающего на СК с выхода БР. Ошибка
исправляется.
. В момент, когда ошибка окажется в
старшем n-м разряде БР, на выходе СД
образуется выделенный синдром, ДО выдает сигнал «1», который поступает на СК,
изменяя значения очередного символа, поступающего на СК с выхода БР. Ошибка
исправляется.
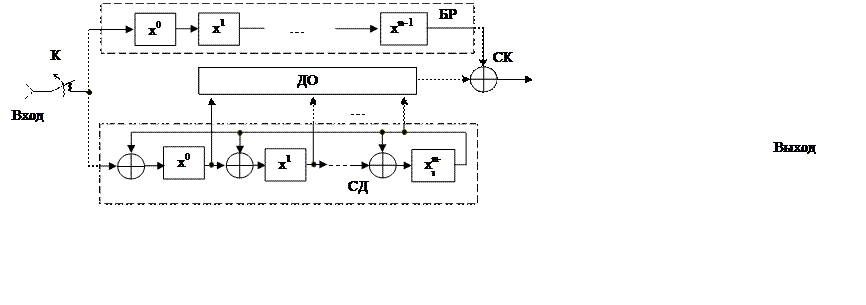 |
Рис.3. Схема декодирующего устройства с исправлением однократных ошибок
Эффективность корректирующих кодов
Эффективность корректирующего
кода характеризуется вероятностями правильного приема кодовой комбинации ![]() , обнаруживаемой
, обнаруживаемой ![]() и необнаруживаемой
и необнаруживаемой ![]() ошибок. Для этих вероятностей
справедливо соотношение:
ошибок. Для этих вероятностей
справедливо соотношение:
![]() .
.
Кроме того, для сравнения эффективности кодов пользуются коэффициентом повышения достоверности, который определяется для режима обнаружения и исправления следующим образом:
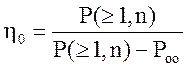 ,
,
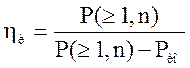 ,
,
где ![]() - вероятность
появления одной и более ошибок в n-разрядной кодовой комбинации;
- вероятность
появления одной и более ошибок в n-разрядной кодовой комбинации; ![]() - вероятность обнаружения ошибки;
- вероятность обнаружения ошибки; ![]() - вероятность исправления ошибки.
- вероятность исправления ошибки.
Коэффициент ![]() показывает, во сколько раз
применяемый корректирующий код уменьшает вероятность того, что выданная
получателю комбинация будет содержать ошибку по сравнению с безызбыточным кодом
той же разрядности.
показывает, во сколько раз
применяемый корректирующий код уменьшает вероятность того, что выданная
получателю комбинация будет содержать ошибку по сравнению с безызбыточным кодом
той же разрядности.
Рассмотрим расчет этих
показателей для кода (7,4) с минимальным кодовым расстоянием ![]() . Такой код позволяет обнаруживать
все ошибки кратности
. Такой код позволяет обнаруживать
все ошибки кратности ![]() , т.е.
, т.е. ![]() , и исправлять ошибки кратности
, и исправлять ошибки кратности 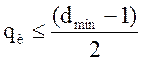 , т.е.
, т.е. ![]() .
Полагая, что ошибки независимы и возникают с вероятностью p, т.е. математическая модель
ошибок – биномиальный закон распределения, согласно которому вероятность
искажения
.
Полагая, что ошибки независимы и возникают с вероятностью p, т.е. математическая модель
ошибок – биномиальный закон распределения, согласно которому вероятность
искажения ![]() символов в n-разрядной комбинации равна [1,3]
символов в n-разрядной комбинации равна [1,3]
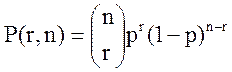 , (1)
, (1)
где 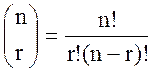 - биномиальные
коэффициенты.
- биномиальные
коэффициенты.
Показатели эффективности для режима обнаружения и исправления ошибки можно рассчитать следующим образом.
Режим обнаружения
Вероятность правильного приема
определяется из (1) при ![]() (ошибок нет)
(ошибок нет)
![]() . (2)
. (2)
Если код обнаруживает все ошибки
кратности ![]() , а также некоторые ошибки большей
кратности, то согласно (1) вероятность обнаружения ошибки будет равна
, а также некоторые ошибки большей
кратности, то согласно (1) вероятность обнаружения ошибки будет равна
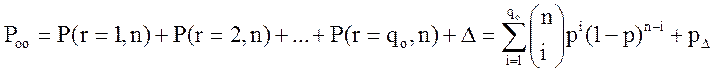 ,
(3)
,
(3)
где ![]() – вероятность
обнаруживаемых кодом ошибок, кратность которых больше
– вероятность
обнаруживаемых кодом ошибок, кратность которых больше ![]() .
.
Вероятность необнаруживаемых кодом ошибок
![]() . (4)
. (4)
Коэффициент повышения достоверности
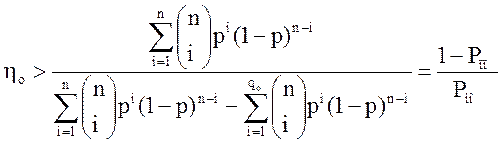 . (5)
. (5)
Режим исправления
Если код исправляет все ошибки
кратности ![]() , то в соответствии с (1) вероятность
правильного приема
, то в соответствии с (1) вероятность
правильного приема
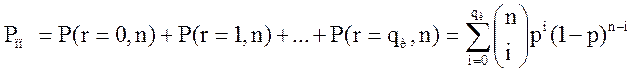 .
(6)
.
(6)
Вероятность исправления ошибки
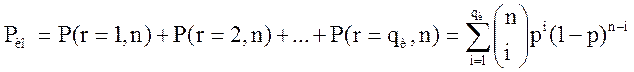 .
(7)
.
(7)
Вероятность неисправляемых ошибок
![]() . (8)
. (8)
Коэффициент повышения достоверности
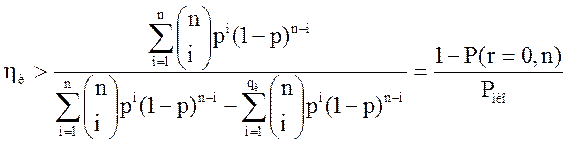 . (9)
. (9)
Экспериментально искомые вероятности роо, рис определяют с помощью точечных или интервальных оценок [4]. В качестве точечной оценки, как правило, используется эмпирическая частота
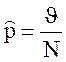 , (10)
, (10)
где N – число испытаний, J – число благоприятных исходов в N испытаниях (число появлений исследуемого события).
Поскольку J является случайным, то во многих случаях, особенно при малых N, такая оценка может оказаться далекой от действительного значения оцениваемой величины. Поэтому чаще указывают интервал, в пределах которого с вероятностью γ, близкой к единице, находится значение оцениваемой величины. Такой интервал (pв, pн), в котором с вероятностью γ находится значение оцениваемой величины:
![]() , (11)
, (11)
называется 100γ–процентным доверительным интервалом. Границы 95–процентных доверительных интервалов для оценок (10), полученных согласно [4] для канала с независимыми ошибками, представлены в табл.2 (значения pн,pв умножены на 103).
Таблица 2
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.