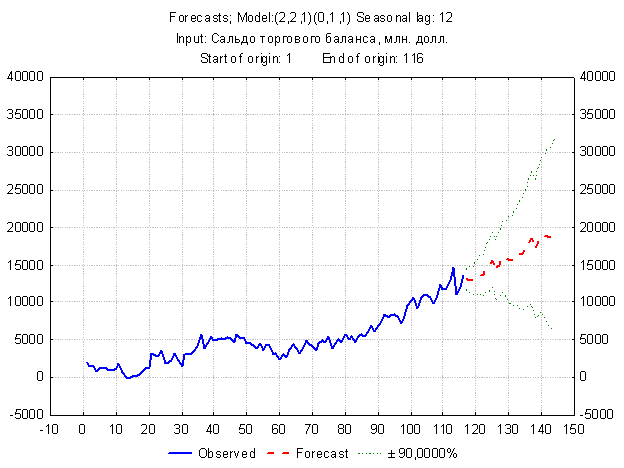
 Рисунок – 5.
Рисунок – 5.
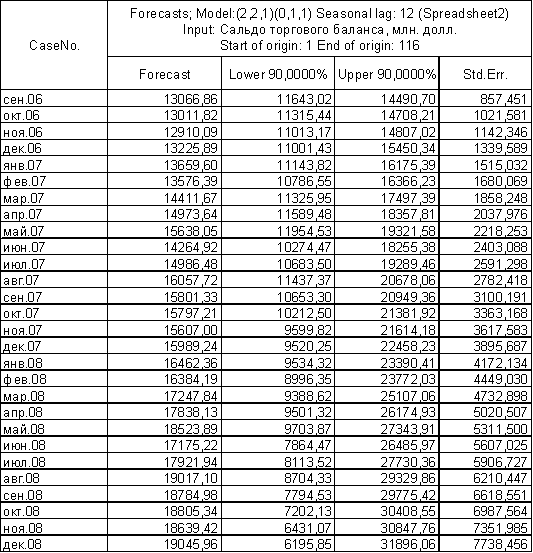 |
Рисунок – 6.
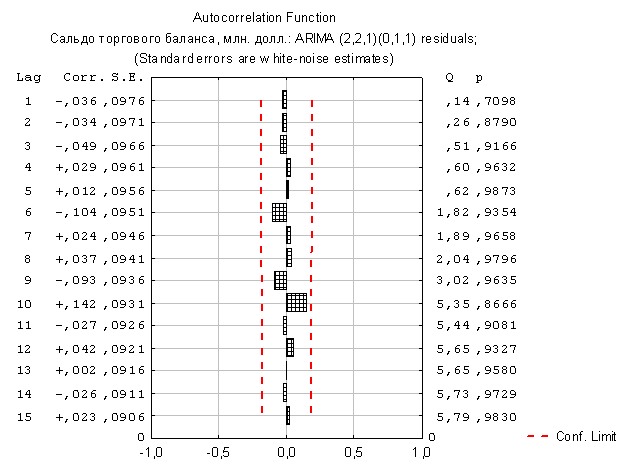 |
2. Прежде чем приступить к анализу имеющихся данных и построению прогноза целесообразно обозначить необходимость проведения этих операций.
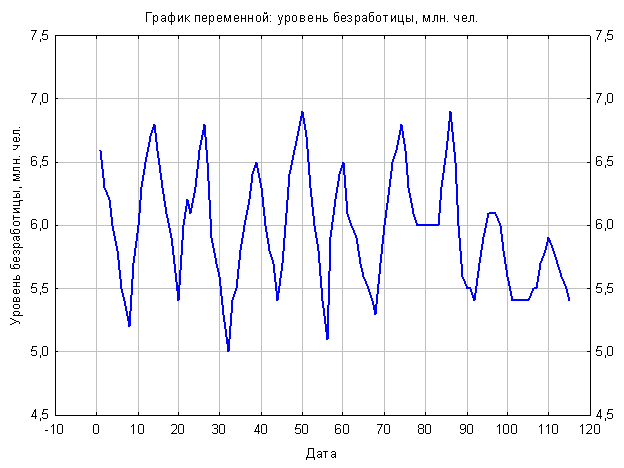
Показатель, который мы прогнозируем – это характеризующий уровень безработицы в Российской Федерации в период с 1997 года по 2006 год, в млн. человек.
При первичном рассмотрении данных можно заметить, что за анализируемый промежуток уровень безработицы практически не изменился, без учета сезонных колебаний в данных.
Из этого можно сделать вывод о том, что правительством практически не принимаются меры для снижения данного уровня, нет четко проработанной политики занятости, предложений новых вакансий, плохо работают органы службы занятости и другие подобные учреждения.
Так же в процессе анализа мы обнаруживаем сильные скачки данных, обусловленные сезонными факторами. По-моему мнению, это связано с тем, что в осенне-летний семестр особенно много людей устраиваются на сезонные работы, связанные, прежде всего, с посадкой и сбором урожая.
Прогнозирование в данной сфере поможет нам в организации процесса управления уровнем безработицы, он необходим для оценки возможностей и негативных моментов, это также позволит выявить негативные тенденции и свести к минимуму их последствия. Очевидно, что для полноты прогноза необходимо учитывать и факторы, влияющие на данный уровень, но это уже предмет другой работы. В данном исследовании мы попытаемся оценить влияние сезонных факторов (с помощью модели экспоненциального сглаживания) и на основе этого построить прогноз на 2,5 года.
Цель работы: изучить данные по уровню безработицы в Российской Федерации и составить прогноз до 2008 года включительно с применением метода экспоненциального сглаживания.
В процессе исследования мы будем опираться на данные по месяцам в период с января 1997 года по июль 2006 года. Данные представлены в таблице 1.
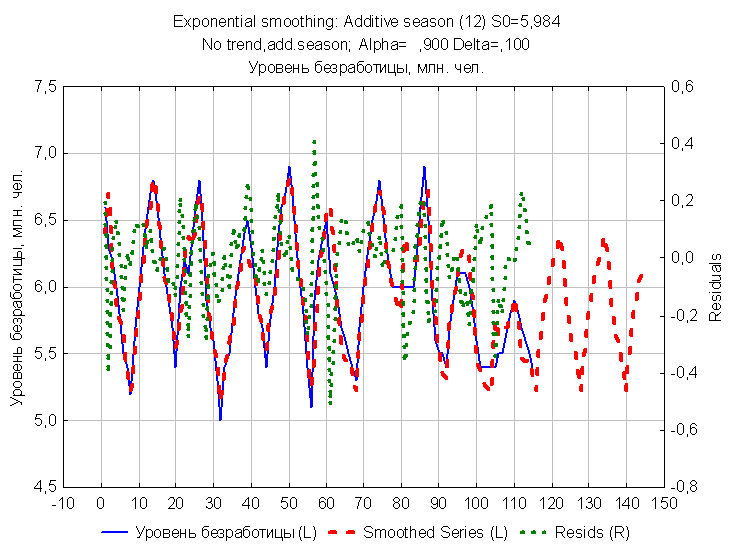
Очевидно, что модель аддитивная с хорошо выраженной сезонной компонентой и абсолютным трендом. Поэтому во вкладке нам необходимо выбрать модель аддитивную простую. После этого мы автоматически определяем наиболее оптимальные параметры α (альфа) и δ (дельта) по величине ошибок. В нашем случае они соответственно равны 0,9 и 0,1 и строим прогноз.
После построения прогноза необходимо оценить величину ошибок, которые считаются автоматически. В нашем случае ошибки не очень большие, график нормального распределения и гистограмма также не отклоняются от нормы, поэтому можно сделать вывод об адекватности выбранной модели.
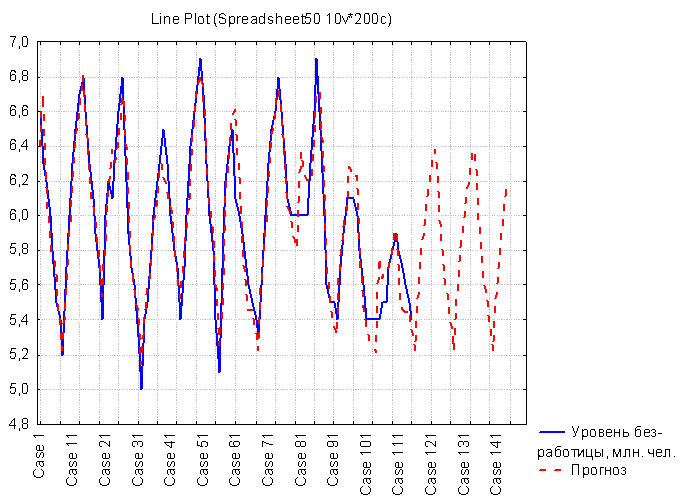
Итоговые данные и прогноз представлены в таблице 2.

 |
||
 |
||
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.