2. Двойной ввод основан на том, что два оператора использующие различные устройства ввода, не могут допустить одну и ту же ошибку, если она не вызвана спецификой заполнения документа.
3. Корреляционный анализ, который заключается в корреляционной зависимости между значениями различных реквизитов. Он ориентирован на обнаружение смысловых ошибок. Корреляционные зависимости задаются, как правило, таблично и определяют запрещенные сочетания значений реквизитов. Поскольку методы корреляционного анализа основаны на естественной избыточности, имеющейся в совокупности данных, их реальная эффективность зависит от степени этой избыточности.
![]() количество разрушенных комбинаций
значений k - реквизитов;
количество разрушенных комбинаций
значений k - реквизитов;
![]() количество разрушенных значений i-го реквизита;
количество разрушенных значений i-го реквизита;
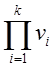 - Общее количество всевозможных сочетаний значений
реквизитов.
- Общее количество всевозможных сочетаний значений
реквизитов.
Относительная корреляционная избыточность k-реквизитов определяется
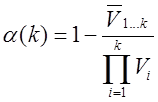
3.1.3. Прагматические ошибки не искажают информационных потоков, но значительно увеличивают трудоемкость выполнения операций обработки за счет расширения информационного потока данными, в процессе формирования управленческого решения. Эта группа ошибок обычно вызывается недостатками проектирования ИС, когда автоматизируется существующий технологический процесс обработки информации с изменением алгоритма формирования управленческого решения. Часть информационного потока не используется при обработке, но требует затрат на всех операциях технологического процесса.
Выявление прагматических ошибок осуществляется в процессе функционирования ИС контролем частоты использования данных. Статистика использования данных ведется в ИС для принятия решений о физической реорганизации.
3.2. Методы контроля орфографических ошибок.
Необходимым условием реализации методов контроля является введение избыточности в исходное сообщение. Введенная избыточность позволяет расширить область значений данных и разбить расширенное множество значений на два подмножества - расширенные комбинации символов и запрещенные. В зависимости от способов введения избыточности можно выделить три группы методов контроля орфографических ошибок использующих
- избыточные разряды;
- двукратную избыточность;
- естественную избыточность.
3.2.1. Методы контроля по модулю.
Контроль по модулю является наиболее эффективным и наиболее распространенным способом использования избыточных разрядов.
Сущность данного метода заключается в следующем.
Каждому разряду числа ![]() представляющего реквизит
присваивается определенный вес
представляющего реквизит
присваивается определенный вес ![]() . Избыточные
разряды, расширяющие область потенциальных значений исходного реквизита,
образуются обычно, как остаток отделения
. Избыточные
разряды, расширяющие область потенциальных значений исходного реквизита,
образуются обычно, как остаток отделения
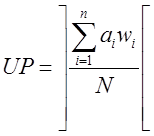 или
или 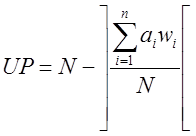
где: N - выбранное значение модуля.
Избыточные разряды формируются при проектировании классификаторов, которые используются при кодировании. Созданный механизм защиты позволяет на операции ввода проконтролировать правильность регистрации информации и правильность ввода. Технологию контроля информации можно представить в следующем виде (рис.3.2.)
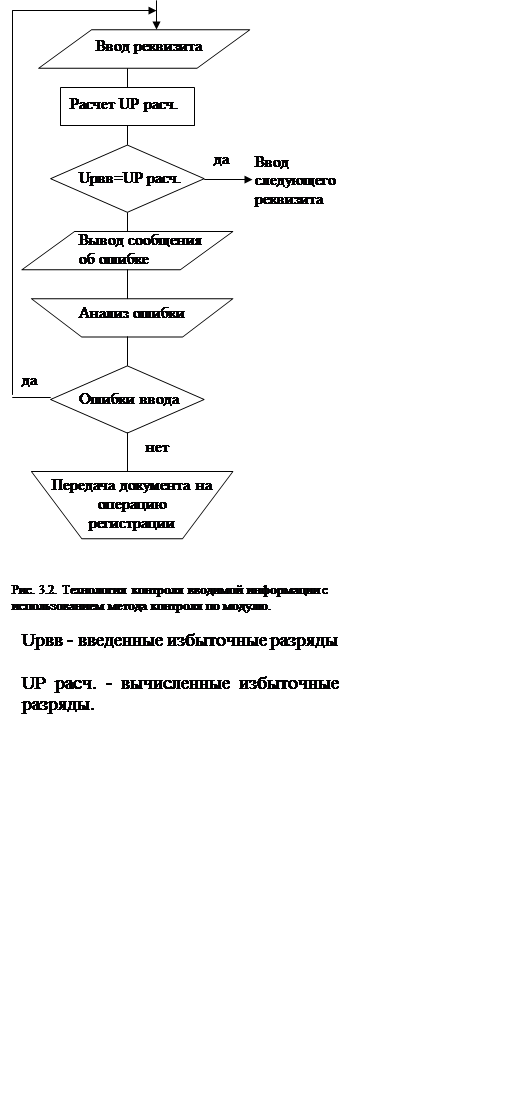
Рассмотрим алгоритмы обнаружения основных ошибок и исходные предпосылки к выбору значений wi и N.
¨ Однократные транскрипционные ошибки вида а®в.
Если в разряде i допущена ошибка, 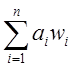 изменится на величину
изменится на величину ![]() , где
, где ![]() -
алгебраическая разность между правильным и измененным значением разряда i.
Эта ошибка не будет обнаружена только в тех случаях, когда
-
алгебраическая разность между правильным и измененным значением разряда i.
Эта ошибка не будет обнаружена только в тех случаях, когда ![]() окажется кратным модулю N.
Следовательно ни
окажется кратным модулю N.
Следовательно ни ![]() ни wi не
должны быть кратны N, а сам модуль должен быть простым числом. Поскольку
ни wi не
должны быть кратны N, а сам модуль должен быть простым числом. Поскольку ![]() целое число в интервале [0,9], то N
должно быть больше 9.
целое число в интервале [0,9], то N
должно быть больше 9.
¨ Многократные смежные транскрипционные ошибки, вида аlal+1
…® blbl+1 …. В этом
случае изменится на величину ![]() (wlwl+1
…) где
(wlwl+1
…) где ![]() =b-a. Для обнаружения ошибки
необходимо чтобы ни
=b-a. Для обнаружения ошибки
необходимо чтобы ни ![]() ни не
оказались кратными N. Следовательно, для обнаружения таких ошибок N должно быть
простым числом большим 9 и сумма двух и более последовательных весов не должна
быть кратна N.
ни не
оказались кратными N. Следовательно, для обнаружения таких ошибок N должно быть
простым числом большим 9 и сумма двух и более последовательных весов не должна
быть кратна N.
¨ Транспозиционные ошибки.
Замена местами двух разрядов aiaj,
каждый из которых является правильным к следующему изменению исходной суммы
![]()
Изменения не будут кратны N и транскрипционная ошибка будет обнаружена если все веса различны и разность между двумя любыми весами не кратна N.
¨ Сдвиговые ошибки.
Если группа из m разрядов аlai+1 …aj
сдвигается на l позиций влево или вправо так, что образующиеся пустые
места заполняются нулями изменится на
величину
![]() .
.
Очевидно, что сдвиговые ошибки могут быть обнаружены только в том случае, если при ращения исходной суммы не кратно N.
Принято считать, что возможности обнаружения сдвиговых ошибок ухудшаются, если последовательность значений wi образует арифметическую или геометрическую прогрессию. Однако более детальный анализ показывает что это не так.
Рассмотрим уравнение сдвига
![]()
где
![]() С - константа, принимающее значения
0, 1, 2 … .
С - константа, принимающее значения
0, 1, 2 … .
Для заданных значений m, ![]() - количество ненулевых корней этого
уравнения (векторов значений аi…aj+m-1) определяет
количество пропускаемых сдвиговых ошибок кратности l. Если
последовательность весов образует арифметическую прогрессию, то
- количество ненулевых корней этого
уравнения (векторов значений аi…aj+m-1) определяет
количество пропускаемых сдвиговых ошибок кратности l. Если
последовательность весов образует арифметическую прогрессию, то ![]() , но количество корней при этом не
увеличивается, а просто значения корней группируются другим образом, так что их
легче обнаружить. Свойства группировки корней при последовательности весов,
образующих арифметическую прогрессию могут быть использованы для повышения
эффективности контроля по модулю. Например: если m=2, веса составляют
арифметическую прогрессию с шагом 1, то
, но количество корней при этом не
увеличивается, а просто значения корней группируются другим образом, так что их
легче обнаружить. Свойства группировки корней при последовательности весов,
образующих арифметическую прогрессию могут быть использованы для повышения
эффективности контроля по модулю. Например: если m=2, веса составляют
арифметическую прогрессию с шагом 1, то ![]() и
уравнения сдвига имеет вид
и
уравнения сдвига имеет вид
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.