Процессорные ядра
|
Блок-схема процессорного ядра Sundy Bridge изображена на рис.X.3.
Обозначения на рисунке:
Здесь:
ALU (ArithmeticLogicUnit) – арифметико–логическое устройство.
Load – функциональное устройство загрузки данных
Store – функциональное устройство сохранения данных.
StoreAddress – функциональное устройство, осуществляющее передачу в память адресной информации.
StoreData – функциональное устройство, осуществляющее передачу в память данных.
AVXFPBlend –реализация команд, обеспечивающих гладкую стыковку отрезков в машинной графике.
AVXFPMUL –реализация команд умножения векторов с плавающей запятой.
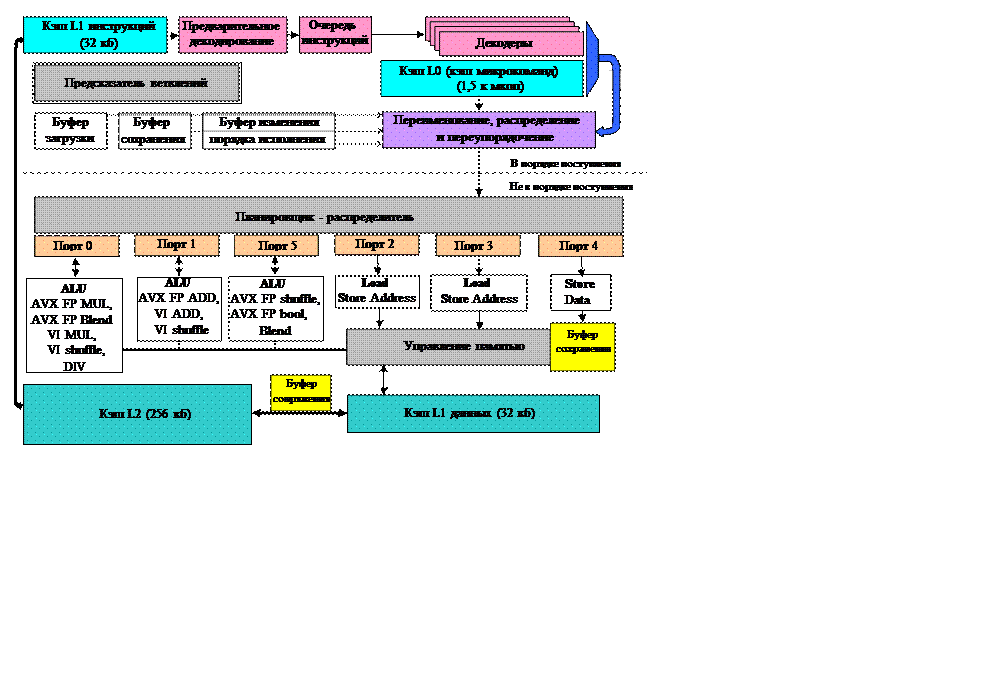
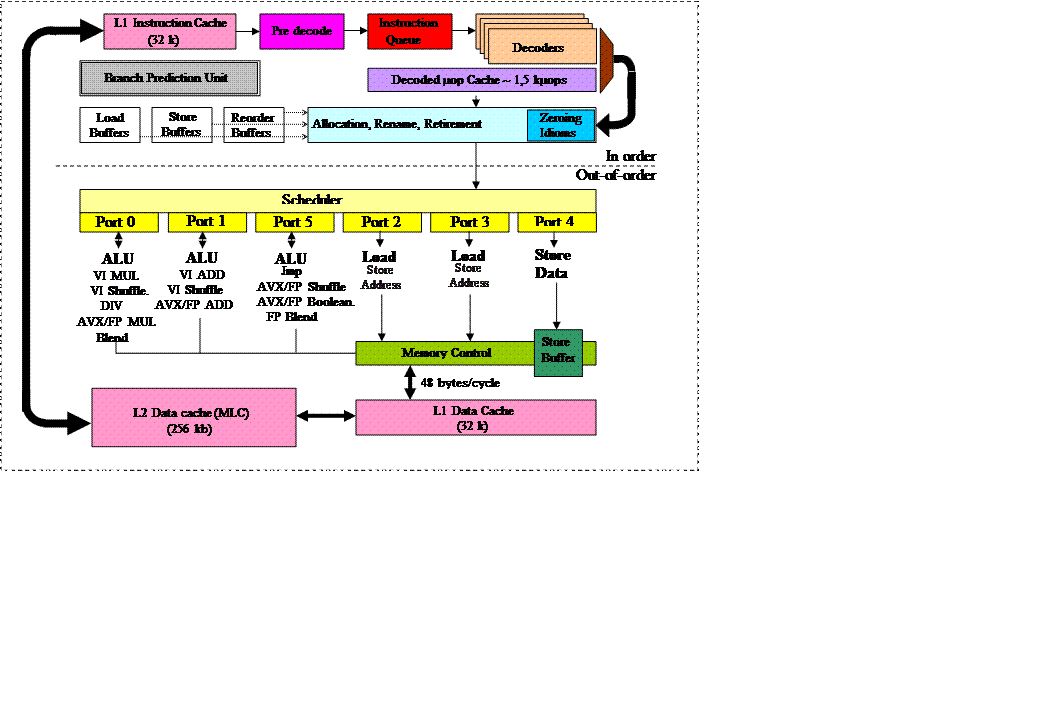
Рис X.3 Блок схема процессорного ядра Sandy Bridge
AVXFPADD – реализация команд сложения векторов с плавающей запятой.
AVXFPshuffle – реализация команд перетасовки векторов с плавающей запятой.
AVXFPbool – реализация операций с булевыми функциями.
VI ADD -
VI MUL –
VI shuffle –
DIV – реализация команд деления.
Кэш L1 инструкций представляет собой восьмиканальную (8-ми входовую) множественно-ассоциативную кэш-память емкостью 32 килобайт с размером строки (блока) равной 64 байт. После выборки из кэш-памяти с помощью блока упреждающей выборки команд, который располагается в модуле предсказания ветвлений (BranchPredictionUnit), строка инструкций Х86 подается на ступень предварительного декодирования (Predecoder). Дело в том, что инструкции Х86 имеют переменную длину, а у блоков, которыми информация загружается из кэш памяти, фиксированная длина. Предварительное декодирование заключается в том, что этот сплошной блок кодов, размером в 64 байт разбивается на отдельные инструкции Х86, и заносятся в буфер очереди команд (InstructionQueue). При предварительном декодировании команд нужно определять границы между отдельными командами. Информация о размерах команд хранится в кэш памяти инструкций L1 в специальных полях (по 3 бита информации на каждый байт инструкций). Процедура предварительного декодирования позволяет поддерживать постоянный темп декодирования независимо от длины и структуры команд.
Таким образом, перед собственно декодированием команд производится выделение команд из общего блока. Введение же буфера очереди команд позволяет уменьшить простои конвейера из-за конфликтов по управлению (за счет задержек при выборке команд из памяти). При этом, формирование очереди команд осуществляется со скоростью до шести инструкций за такт.
Из буфера очереди команд, работающей по принципу FIFO, инструкции поступают на 4 блока основного декодирования (Decoders), работающих параллельно. Блоки декодирования преобразуют инструкции Х86 разной длины в упорядоченный поток равномерных микрокоманд, которые определяют так называемые микрооперации (мкоп, micro-op, μops) – понятные для данного процессора примитивы. От оперативности работы декодеров, от их согласованности с блоком предсказания ветвлений и «умения» заполнять конвейер непосредственно зависит бесперебойность потока микроопераций, загрузка конвейера и, в конечном счете, производительность микропроцессора.
При этом в целом, этот четырехканальный декодер включает в себя три простых декодера, предназначенных для декодирования простых инструкций (сложения, вычитания, сравнения, логических операций и др., без выборки операндов из памяти) в одну микрокоманду, реализующую одну простую микрооперацию, и один сложный, способный декодировать одну (более сложную) инструкцию в четыре микрокоманды. Однако в любом случае декодеры, вне зависимости от поступающих инструкций выдают на выходе не более четырех микрокоманд за такт. При этом отметим, что все микрокоманды на выходе декодеров, имеют одинаковую фиксированную длину.
Сами все эти декодеры реализуются в аппаратном исполнении.
Одним из наиболее важных нововведений микроархитектуры Sandy Bridge является вновь введенный кэш декодированных микроопераций, или кэш L0. Он может хранить 1536 микрокоманд, с возможностью параллельного ввода и вывода одновременно шести микрокоманд. Кэш L0 кэширует на выходе декодеров все предварительно декодированные микрокоманды. Как только поступает на обработку новая инструкция, блок упреждающей выборки первым делом производит сверку с кэш L0, и в случае обнаружения совпадений, загрузка конвейера четырьмя микрокомандами за такт в обход декодеров осуществляется уже их КЭШа L0. Незадействованные и простаивающие устройства декодеров, достаточно сложные и поэтому потребляющие довольно много энергии в это время автоматически отключаются от источника питания. Если же кэш декодированных микрокоманд оказывается невостребованным, он переводится в режим экономии энергии, а декодеры продолжают обычную работу по выборке и декодированию инструкций. Кэш L0 в какой-то мере можно считать частью кэш L1, в который он, кстати, интегрирован, но отдельной и очень быстрой его частью. По словам представителей фирмы Intel, при работе с большинством приложений, вероятность удачного попадания в кэш декодированных микрокоманд весьма велика и может достигать 80%.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.