Необходимо отметить, что частота появления ошибок при коде со степенью 1/2 – это частота появления неисправленных ошибок , а Eb – энергия на один бит данных. Поскольку степень кодирования равна 1/2, каждому биту данных соответствуют два канальных бита, следовательно удельная энергия кодированного бита в два раза меньше удельного бита данных, т.е. разница Eb/N0 составляет 3дБ. Если рассмотреть удельную энергию кодированного бита такой системы, уровень битовых ошибок в канале составляет 2,4 х 10-2, или 0,024.
В завершение необходимо отметить, что если значение Eb/N0 – ниже определенного порогового, методы кодирования отрицательно сказываются на производительности системы. В примере, приведенном на рисунке, это пороговое значение равно приблизительно 5,4 дБ. При более низком значении Eb/N0 использование дополнительных контрольных битов снижает удельную энергию битов данных, что ведет к увеличению числа ошибок. Если значение Eb/N0 выше порогового, способность кода исправлять ошибки (эффективность кодирования) позволяет компенсировать снижение Eb и улучшить работу системы.
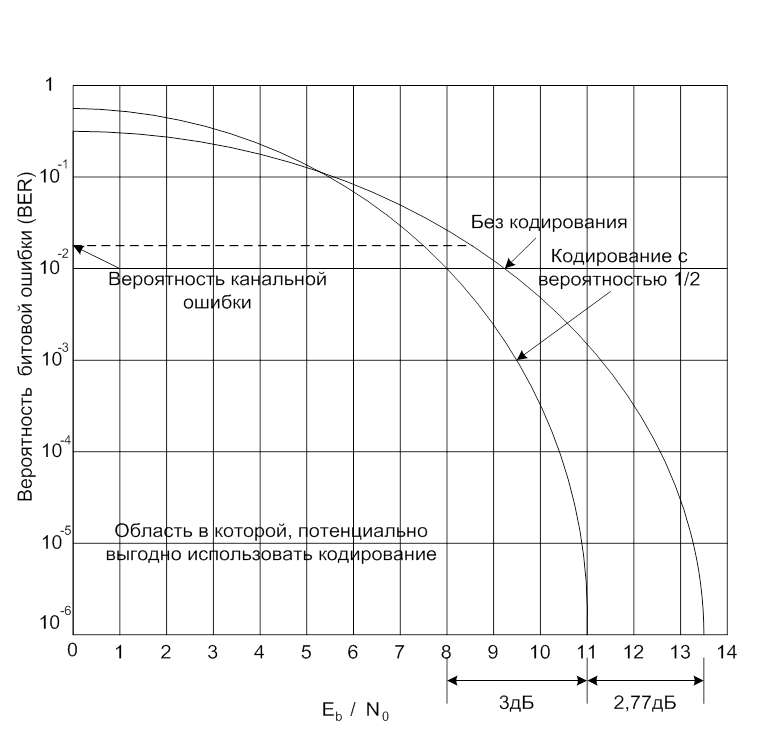
Рис. 2 Улучшение работы системы с помощью кодирования
Рассмотрим конкретные виды кодов с коррекцией ошибок.
Код Хэмминга
Коды Хэмминга- это семейство блочных кодов с коррекцией ошибок (n,k), которые характеризуются следующими параметрами
Длина блока n=2m-1
Количество битов данных k=2m-m-1
Количество контрольных битов n-k=m
Минимальное расстояние dmin=3
Здесь m > 3. Коды Хэмминга просты в использовании и легко поддаются анализу, однако редко используются на практике. Рассмотрим этот тип кодов, чтобы проиллюстрировать на их примере некоторые фундаментальные принципы работы блочных кодов.
Коды Хэмминга созданы для исправления 1- битовых ошибок. Для начала определим необходимую длину кода. Коды Хэмминга применяются также, как методы определения ошибок – в процессе кодирования сохраняются k бит данных и добавляются (n-k) контрольных битов. При декодировании используются две последовательности из (n-k) бит, одна из которых является кодовым словом входящего сигнала, а другая рассчитывается на основе полученных битов данных. Последовательности побитово сравниваются с помощью логического исключающего ИЛИ. Результат сравнения называют синдромом. Биту синдрома присваивается значение 0, если биты двух последовательностей совпадают, и 1 – в противном случае.
Синдром – это (n-k) – битовое слово в диапазоне от 0 до 2(n-k)-1. Значение 0 свидетельствует об отсутствии ошибки . Если же ошибка присутствует, ее местоположение определяется из синдрома. Поскольку ошибочным может быть любой из k бит данных или (n-k) проверочных битов, должно выполнятся следующее соотношение:
![]()
Приведенное уравнение определяет количество битов, необходимое для исправления 1- битовой ошибки в слове, содержащем k бит данных. В таблице приводится число контрольных битов, необходимое для последовательностей данных разной длины.
Таблица 1 Требования к кодам Хэмминга
|
Количество битов данных |
Исправление 1- битовых ошибок |
Исправление 1 – битовых ошибок; обнаружение 2 – битовых ошибок |
||
|
Количество контр битов |
Увеличение блока в % |
Количество контр битов |
Увеличение блока в % |
|
|
8 |
4 |
50 |
5 |
62,5 |
|
16 |
5 |
31,25 |
6 |
37,5 |
|
32 |
6 |
18,75 |
7 |
21,875 |
|
64 |
7 |
10,94 |
8 |
12,5 |
|
128 |
8 |
6,25 |
9 |
7,03 |
|
256 |
9 |
3,52 |
10 |
3,91 |
Для удобства генерируемый синдром должен обладать следующими свойствами:
• Если синдром состоит только из нулей – ошибки не обнаружены.
• Если один и только один бит синдрома равен 1 – ошибка присутствует в одном из контрольных битов; в этом случае исправлять ошибку не нужно.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.