· неявное размещение данных, как страниц памяти, с явным указанием доступа к данным, при котором пересылке подвергаются необходимые страницы не из общей памяти, а из узлов, имеющих их на текущий момент;
· явное размещение данных с указанием разделяемых процессорами страниц с неявным указанием доступа к данным посредством команд load (чтение), store (запись), при котором межпроцессорные передачи происходят согласно с таблицей отображения разделяемых процессорами страниц.
В последнем случае каждый элемент таблицы, используемый при выдаче обращений, должен содержать данные о компьютере-получателе (например, его имя), данные о конкретном месте расположения информации на странице, а также служебные данные, включающие в себя состоятельность рассматриваемого элемента, особенности маршрутизации и т.п.
В параллельной системе идеальная память в процессе обменных операций не должна вызывать простоев процессоров. Приближение к идеальному запоминающему устройству (ЗУ) достигается введением нескольких ступеней промежуточных ЗУ с меньшим объемом и предельно малым временем доступа. Такую память назвали кэш-памятью. Для однопроцессорных вычислительных систем типовая иерархия памяти включает регистровую память (64-256 слов с доступом в 1 такт процессора), кэш 1 уровня (8к слов со временем доступа 1-2 такта), кэш 2 уровня (256к слов – 3-5 тактов) и основную память (до 4 Гигаслов – 12-55 тактов).
В многопроцессорных системах для узлов с такой иерархией памяти идентичность данных в кэшах (когерентность кэшей) поддерживается с помощью межмодульных пересылок. Все действия с использованием транзакций шины доступны для отслеживания всем вычислительным модулям, так как в каждый момент данные на шину передает только один, а принимают эти данные все подключенные абоненты. Существует несколько реализаций алгоритмов, которые поддерживают в такой среде когерентность кэшей. Например, при обращении к кэш-памяти в ходе операции записи данных, после самой записи, процессор останавливается до тех пор, пока не выполнится последовательность следующих действий: измененная строка кэша пересылается в резидентную память вычислительного модуля (ВМ), затем, если строка была разделяемой, она пересылается из резидентной области памяти во все ВМ, указанные в списке разделяющих эту строку. После подтверждения, что все копии изменены, резидентный модуль разрешает процессору продолжить вычисления.
К настоящему моменту существующий протокол сетевого обмена аппаратно и функционально явочным порядком заменяется новым – масштабируемым когерентным интерфейсом (SCI – Scalable Coherent Interface). Его структуру и реализацию развивают более десятка известных фирм и организаций.
Подготавливаемый стандарт SCI обеспечивает построение легкой в реализации, масштабируемой, эффективной в стоимостном плане коммуникационной среды для объединения процессоров и памятей, либо для создания распределенной сети рабочих станций, либо для организации ввода/вывода супер-ЭВМ, высокопроизводительных серверов и рабочих станций на базе современных микропроцессоров.
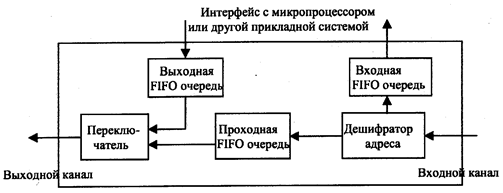 |
Рисунок 2.29.
Функциональная структура узла SCI приведена на рисунке 2.29. Узел позволяет отсылать сформированные в них пакеты с одновременным приемом в узел и пропуском через узел транзитных пакетов. Это оказалось возможным благодаря организации трех очередей.
Однонаправленность передач в SCI имеет принципиальный характер, так как исключает переключение выходных ножек микросхем с передачи на прием и обратно. Благодаря этому вместо физической шины используется множество парных соединений, что обеспечивает высокую скорость передач. Преодолеваются: фундаментальное ограничение шин – одна передача в каждый промежуток времени предоставления шины передающему устройству, и ограничения, связанные со скоростью распространения сигналов по проводам. Для асинхронных шин ограничение определяется временем передачи сигналов «запрос-подтверждение», а при синхронных шинах – разницей времени распространения тактового сигнала от его генератора и времени распространения данных, производимых в передающем устройстве.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.