 |
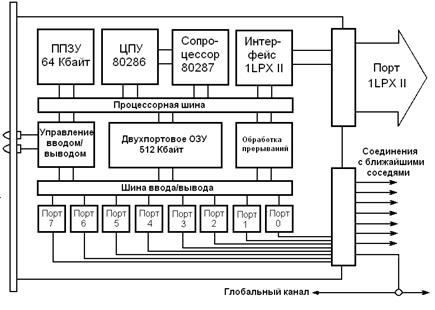
Рисунок 2.25. Структура вычислительного узла транспьютерного типа
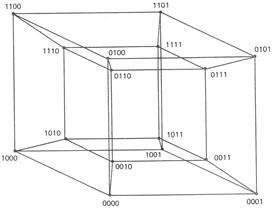 |
Рисунок 2.26. Структура канальных связей в 4-х мерном кубе
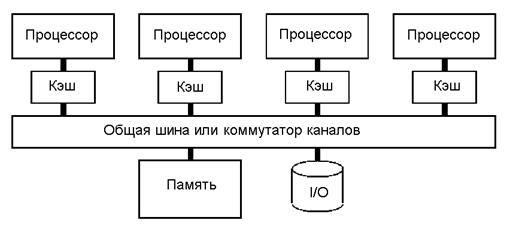 Рисунок 2.27. Структура системы с общей памятью процессоров.
Рисунок 2.27. Структура системы с общей памятью процессоров.
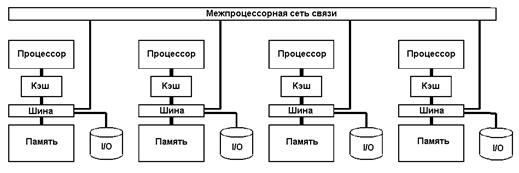
Рисунок 2.28. Структура с локальной памятью процессоров.
Реализация структуры по рис. 2.27 с увеличением числа процессоров резко увеличивает затраты на построение системы полнодоступной коммутации и много портовой памяти, однако снижает накладные затраты на передачу и обмен данными до минимально возможного уровня, равного сумме времен обращения в память и инициализации физической связи в коммутаторе каналов.
Система по рис. 2.28 существенно экономичнее по затратам, однако требует тщательной разработки интерфейсной части канала, ограничения физической длины сетевой связи и тщательной проработки структуры вычислительной задачи при программировании, с целью сокращения и временной упорядоченности обменов данными между процессорами. На первых порах вполне разумно было воспользоваться уже существующим сетевым интерфейсом TCC/IP.
Важнейшими составляющими параллельных вычислительных систем с точки зрения эффективного их использования для параллельных вычислений являются процессоры, память и средства коммуникации.
Распараллеливание вычислительных процессов на уровне арифметико-логических операций и потока команд в настоящее время практически во всех новейших процессорах уже реализовано на аппаратном уровне. Уже рядовым схемотехническим решением, существенно поднявшим производительность процессоров, является конвейеризация отдельных узлов, выполняющих, например, арифметические операции над потоком данных (конвейер данных), обработку команд (конвейер команд) и прочие действия, которые можно представить последовательностью нескольких независимых частных составляющих действия. Впервые высокая степень конвейеризации была реализована в суперкомпьютерах серии Cray-Х (около 12 конвейеров в первой модели).
Дальнейшее повышение эффективности конвейера команд можно получить дублированием функциональных устройств, которым в одном сегменте конвейера одновременно (в одном такте) будет предъявляться на выполнение несколько команд. В зачаточном виде идея реализации сверхдлинных командных слов нашла свое применение в так называемых суперскалярных процессорах таких, например, как Pentium, в котором одновременно выполняется две команды, как UltraSPARC – c четырьмя одновременно выполняемыми командами, и других. Последние достижения в разработке VLIW-процессоров (Very Large Instruction Word) представлены процессорами Itanium с командным словом на 168 бит, которое на этапе трансляции составляется из 7 простых независимых 24 битовых команд.
В борьбе за повышение быстродействия процессоров используются структуры с сокращенным набором команд, так называемые RISC-процессоры (Reduced Instruction Set Computer) с числом команд в несколько десятков. Противоположной тенденции, свойственной процессорам Pentium, являются процессоры CISC-архитектуры (Complete Instruction Set Computer) с числом команд до нескольких сотен. Статистика частот употребления в программах тех или иных команд позволяет аргументировано отдать предпочтение процессорам RISC-архитектуры, обеспечивая при этом существенное ускорение выполнения программ и более эффективную аппаратную реализацию. CISC-архитектуры требуют для своей реализации средства микропрограммирования, увеличивая тем самым среднее число машинных тактов, приходящихся в программе на одну команду.
Ускорение вычислений в современных процессорах добиваются также путем включения в состав команд векторных операций, реализуемых путем увеличения количества арифметико-логических узлов, выполняющих действия со всеми компонентами векторов одновременно или путем организации конвейерной обработки при глубине конвейера меньшей, чем длины векторных операндов.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.