
















Представление информации в ЭВМ
Хотя компьютеры создавались для выполнения численных расчетов, сегодня они превратились в универсальное средство для обработки информации всех видов. Поэтому всякая информация (текст, звуки, изображения, показания приборов и т.д.) должна быть преобразована в числовую форму, чтобы быть обработанной компьютером, а затем вновь получить форму своего первоначального представления.
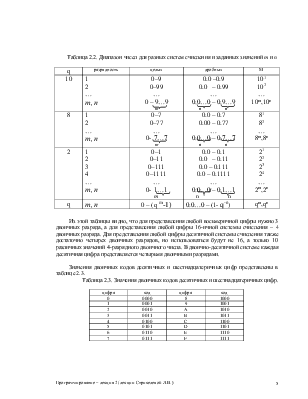
Информация представлена в компьютере в виде двоичных кодов. Для удобства работы введены следующие термины, обозначающие совокупности двоичных разрядов и используемые в качестве единиц измерения объемов информации, хранимой или обрабатываемой компьютером.
|
Количество двоичных разрядов в группе |
1 |
8 |
16 |
8*1024 |
8*10242 |
8*10243 |
8*10244 |
|
Наименование единицы измерения |
бит |
байт |
параграф |
Килобайт (К) |
Мегабайт (М) |
Гигабайт (Г) |
Терабайт (Т) |
Если на странице текста помещается в среднем 2500 знаков, то 1 М – примерно 400 страниц, а 1 Г – 400 000 страниц.
Последовательность нескольких битов или байтов часто называют полем данных. Биты в числе (в слове, в поле и т.д.) нумеруются справа налево, начиная с 0-го разряда.
В компьютере могут обрабатываться поля постоянной и переменной длины.
Поля постоянной длины:
|
Слово |
2 байта |
|
Полуслово |
1 байт |
|
Двойное слово |
4 байта |
|
Расширенное слово |
8 байт |
Поля переменной длины: могут иметь размер от 0 до 256 байт, но обязательно равный целому числу байтов.
Представление текстовой информации
Информатика и ее приложения интернациональны. Компьютер – универсальный преобразователь информации. Тексты на естественных языках, числа, математические и специальные символы – все это должно иметь возможность быть введенным в компьютер.
Для обработки на компьютере текстовой (символьной) информации при вводе в компьютер каждая буква кодируется определенным числом, а при выводе на экран или печать для восприятия человеком по этим числам строятся соответствующие изображения букв. Соответствие между набором символов и числами называется кодировкой символов.
В силу приоритета использования двоичной системы счисления при внутреннем представлении информации в компьютере, кодирование «внешних» символов основывается на сопоставлении каждому из них определенной группы двоичных знаков. При этом из технических соображений и из соображений удобства кодирования-декодирования пользуются равномерными кодами, т.е. двоичными группами равной длины. В текстовом режиме изображение состоит (в зависимости от видеоадаптера) из [25, 43, 50] строк по [40, 80] символов расширенного набора ASCII, формируемых знакогенератором (возможны примитивные рисунки, гистограммы, рамки, составленные с использованием символов псевдографики[1]).
Стандартные шрифты имеют матрицы изображения 8х16 или 8х14. При режимах работы, использующих 43 или 50 строк представления информации, матрица изображения имеет размер 8х8.
Для представления одного символа в текстовом режиме требуется два байта: один (младший) – на ASCII-код символа, другой (старший) – на его атрибут. Байт атрибута содержит цвет символа (разряды 0-2), интенсивность изображения (разряд 3), цвет фона (разряды 4-6), бит мерцания (разряд 7).
Для человека, заинтересованного в использовании лишь одного естественного алфавита (скажем, английского) требуется отображать символов: для букв 52 = 26 х 2 (прописные и строчные); 10 цифр; 10 знаков препинания; 10 разделительных знаков (три вида скобок, пробел и т.д.); знаки привычных математических операций; несколько специальных символов (типа #, $, & и пр.) – итого примерно 100. Чтобы получить 100 разных кодовых комбинаций достаточно иметь равномерный код из 7 двоичных знаков, т.к. 27=128. Однако для кодирования хотя бы двух естественных алфавитов этого недостаточно. Минимально достаточно 8 двоичных знаков: 28=256.
Как правило, код символа хранится в одном байте (коды символов могут принимать значения от 0 до 255), и символ в памяти ЭВМ может быть представлен двумя шестнадцатеричными цифрами (две тетрады по 4 бита). Такие кодировки называют однобайтными. Они позволяют использовать до 256 различных символов. Будем представлять байт состоящим из двух полубайтов:
!__!__!__!__½__!__!__!__!
старший младший полубайт полубайт
Код ASCII (American Standard Code for Information Interchange – Американский стандартный код для обмена информацией) имеет основной стандарт с номерами от нуля до 127 (использует для кодировки символов шестнадцатеричные коды 00 – 7F или их двоичный эквивалент 00000000 - 01111111) и его расширение с номерами 128 - 255 (использует шестнадцатеричные коды 80 – FF или их двоичный эквивалент 10000000 - 11111111). Основной стандарт является международным и используется для кодирования управляющих символов, цифр и букв латинского алфавита. В расширении стандарта кодируются символы псевдографики и буквы национального алфавита.
Фирма IBMпри разработке компьютера IBM PC заложила кодировку (ставшую стандартом), в которой символы с кодами 32-127 соответствовали кодировке ASCII, содержащей латинские буквы, знаки препинания, скобки, специальные знаки и пробел. А на позиции 128 – 255 и 0 – 31 фирма IBM поместила символы западноевропейских алфавитов (немецкого, французского и т.д.), символы псевдографики, позволяющие рисовать на экране рамки и диаграммы, некоторые греческие буквы и специальные символы.
В кодировочной таблице по вертикали указаны значения старшего
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.