Часто в процессе идентификации нечеткой модели, описывающей сложную, в плане исследований, систему, возникают следующие проблемы:
проблема дефицита информации, недостатка экспериментальных данных;
проблема нечеткости самих экспериментальных данных. Имеются в виду не возможные ошибки измерения, а объективная нечеткость самой исследуемой системы.
проблема разнородности экспериментальных данных, которые могут быть четкими числами, а также нечеткими числовыми, интервальными и лингвистическими оценками.
Во всех этих случаях классические способы идентификации неприемлемы, так как они оперируют только обычными числовыми данными и при их использовании предполагается наличие достаточной по объему обучающей выборки. В то же время известные процедуры идентификации нечетких моделей точно также предполагают наличие достаточной по объему обучающей выборки – либо полноценной реальной, либо грубой, либо гипотетической, что не представляется всегда возможным.
В связи с этим предлагается диалоговая человеко-машинная процедура идентификации нечетких моделей с недостаточной мощностью обучающей выборки, которая рассматривается на примере идентифицируемого фрагмента модели [1], связывающей заболеваемость i-ой болезнью с превышением уровня концентраций загрязняющих веществ (ЗВ), попадающих в организм человека через один канал поступления:
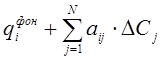
где:
qiфон - фоновая заболеваемость i-ой болезнью.
ai – коэффициент заболеваемости i-ой болезнью.
ΔСj – степень превышения предельно допустимой концентрации (ПДК) j-ого загрязняющего вещества.
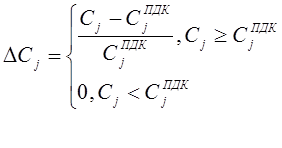
где Сj – концентрация j-ого ЗВ; CjПДК- предельно допустимая концентрация j-ого ЗВ.
Данная модель является нечеткой, так как коэффициенты aij рассматриваются как лингвистические переменные.
Кроме того имеется недостаточная по своему объему обучающая выборка {qов}, компоненты которой qов - разнородные нечеткие данные.
Требуется настроить коэффициенты модели aij.
Укрупненная схема диалоговой процедуры идентификации состоит из следующих этапов:
Структурная идентификация модели.
Представление настраиваемых коэффициентов в виде нечетких переменных.
Формирование обучающей выборки в виде массива нечетких чисел.
Параметрическая идентификация модели, которая, в зависимости от результата настройки, может состоять из следующих операций:
определение областей варьирования выходных экспериментальных данных и области допустимых значений для настраиваемых параметров.
настройка параметров модели с использованием оптимизационных процедур.
расширение области приемлемых значений экспериментальных данных с помощью модификатора их функций принадлежности.
настройка параметров модели с помощью изменения a -уровня.
настройка параметров модели с помощью модификации их функций принадлежности.
Первые две операции являются обязательными. Дальнейшую конфигурацию процедуры идентификации определяет эксперт.
Литература:
1. Косарев В.А., Муратова С.Ю. . Модель оценки комплексного воздействия выбросов металлургического производства на здоровье человека //Информационные технологии в образовании и металлургии: Сборник научных трудов. – М.: МИСИС, 1998.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.
