Отметим что один и тот же документ может входить сразу в несколько групп согласно экспертным оценкам. Соответствующее распределение изображено на рисунке 1. Тем самым многие из получившихся групп имеют большой процент общих документов. На рисунке 2 проиллюстрирована сильная пересекаемость составов коллекций. В частности для каждой из 15 тематик (из 140) существует ”поглощающая” тематика, которая содержит не менее 70% входящих в эту тематику документов. Максимальный процент поглощения достигает 99%, например, для тематики посвященной военным действиям в Ираке и тематики посвященной военным действиям во
Number of best matches
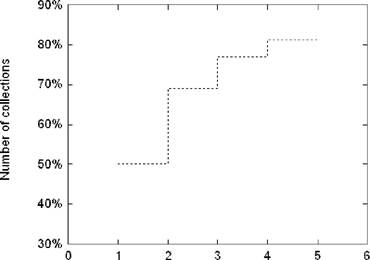
Рис. З: Вероятность появления указанной экспертами тематик среди первых лт выбранных автоматически лучших тематик
|
Класс (N) |
Число кандидатов |
Всего в классе |
|||
|
1 |
2 |
З |
4 |
||
|
1 |
50.1% |
69.0% |
77.1% |
81.3% |
25704 |
|
2 |
29.4 % |
46.8% |
57.5% |
10648 |
|
|
З |
21.0% |
36.4% |
8382 |
||
|
4 |
14.4 % |
7613 |
|||
Table 2: Вероятность попадания лт помеченных экспертами тематик в несколько лучших при автоматической классификации документов класса лк .
всем мире.
В качестве группы задающих тематику документов, мы использовали 50 случайным образом выбранных документов из соответствующего тематического набора. На базе объединенного множества документов, использовавшихся для задания тематик, строилась функция семантической близости термов (как это описано в разделе 3.3).
Отметим, что в наших экспериментах для описания каждой тематики использовалось в среднем [4] 12% относящихся к ней документов из используемой экспериментальной базы, в отличие, например, от экспериментов описанных в работе [8], где для описания тематик использовалось более 50% доступных документов.
В ходе проводимых экспериментов для каждого из 25181 рассматриваемых документов вычислены оценки его близости каждой из рассматриваемых тематик. По результатам этих оценок для каждого из документов был построен упорядоченный список тематик в порядке их оценок близости. Далее проводился анализ полученной информации.
Результаты практических экспериментов показали, что наилучшая[5] тематика, выбранная при помощи описанного подхода, попадает в множество указанных экспертами для данного документа (”искомых”) тематик в более 50% случаев. А вероятность попадания указанной экспертами тематики в автоматически отобранную тройку лучших тематик превысила 75%. Для такого сложного набора тестовых данных эти результаты выглядят весьма прилично. Зависимость вероятности нахождения ”искомой“ тематики среди первых лт отобранных лучших тематик проиллюстрирована на графике З.
В используемом нами экспериментальном наборе данных для многих документов эксперты указали более одной тематики, к которой по их мнению относится этот документ. Естественно, что пользователи системы автоматической классификации заинтересованы в том чтобы система относила документ ко всем релевантным тематикам, а не только к какой-нибудь одной из них.
Для того,
чтобы оценить насколько хорошо предложенный подход справляется с этой задачей
мы раздели![]() все множество используемых документов на классы
по количеству указанных экспертами для данного документа тем. В первый класс
вошли все доступные документы, во второй — только те документы для которых
экспертами было указано не менее двух тематик, в третий — не менее трех, и т.д.
все множество используемых документов на классы
по количеству указанных экспертами для данного документа тем. В первый класс
вошли все доступные документы, во второй — только те документы для которых
экспертами было указано не менее двух тематик, в третий — не менее трех, и т.д.
Для каждого класса К мы вычислили процент документов из этого класса для которых среди первых лт лучших тематик встречалось не менее К указанных экспертами. Полученные результаты проиллюстрированы в таблице 2.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.