



7. Статистическое кодирование.
Для дискретных каналов без помех К. Шенноном была доказана следующая теорема: если производительность источника RИ<С-ε, где e - сколь угодно малая величина, то всегда существует способ кодирования, позволяющий передавать по каналу все сообщения источника. Передачу всех сообщений при RИ>C осуществить невозможно.
Для рационального использования пропускной способности канала необходимо применять соответствующие способы кодирования сообщений. Статическим или оптимальным называется кодирование, при котором пропускная способность канала связи без помех используется наилучшим образом. При оптимальном кодировании фактическая скорость передачи сообщений по каналу R приближается к пропускной способности С, что достигается путем согласования источника с каналом. Сообщения источника кодируются таким образом, чтобы они в наибольшей степени соответствовали ограничениям, которые накладываются на сигналы, передаваемые по каналу связи. Поэтому структура оптимального кода зависит как от статистических характеристик источника, так и от особенностей канала.
Энтропия источника сообщений.
В теории связи основное значение имеет не количество информации, содержащееся в отдельном сообщении, а среднее количество информации, создаваемое источником сообщений. Среднее значение (математическое ожидание) количества информации, приходящееся на одно элементарное сообщение, называется энтропией источника сообщений.
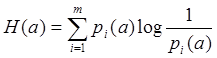
Как видно из формулы, энтропия источника определяется распределением вероятностей выбора элементарных сообщений из общей совокупности. Обычно отмечают, что энтропия характеризует источник с точки зрения неопределенности выбора того или иного сообщения. Энтропия всегда величина вещественная, ограниченная и неотрицательная: H(x)>0.
Найдем энтропию источника сообщений:
m-объем алфавита дискретного источника = 2;
вероятность приема “1” (Р(1)) = 0,8;
вероятность приема “0” (Р(0)) = 0,2;
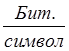 Для вычисления энтропии
воспользуемся формулой:
Для вычисления энтропии
воспользуемся формулой:
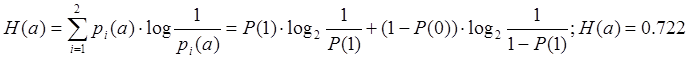 При
m=2 Hmax(a)=1 наблюдается при
равновероятном приеме 0 и 1, т.е. P(1)=P(0)=0,5. Если же энтропия не максимальна, то
вводят коэффициент избыточности.
При
m=2 Hmax(a)=1 наблюдается при
равновероятном приеме 0 и 1, т.е. P(1)=P(0)=0,5. Если же энтропия не максимальна, то
вводят коэффициент избыточности.
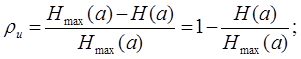
Этот коэффициент показывает, какая доля максимально возможной энтропии не используется источником. Если ρи>20%, то необходима перекодировка сообщения для снижения коэффициента избыточности.
Подсчитаем коэффициент избыточности :
H(a)=0.722;Hmax(a)=log2m=log22=1; ,тогда…
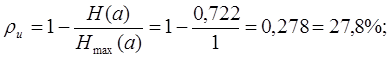
Коэффициент избыточности получился больше 20%, следовательно, необходима перекодировка сообщения.
Для повышения эффективности передачи сообщение должно быть закодировано таким образом, чтобы коэффициент избыточности (ρи) кодовой последовательности был как можно меньше. Коды, обеспечивающие такое преобразование, называют статистическими. Если источник не имеет памяти и избыточность обусловлена только неравновероятностью элементов сообщения, то она может быть уменьшена кодированием наиболее вероятных элементов сообщения в наиболее короткие, а наименее вероятных—в наиболее длинные кодовые комбинации.
Наибольшее снижение избыточности, достигается кодированием по методу Фано-Шеннона-Хаффмена.
Осуществим статистическое кодирование восьми трехбуквенных комбинаций, состоящих из элементов двоичного кода 1 и 0: 000, 001, 010, 011 100, 101, 110, 111. Для кодирования воспользуемся алгоритмом неравномерного кодирования Хаффмена.
Для этого:
1. Вычислим вероятности этих комбинаций и расположим их в порядке убывания вероятностей в таблицу (таблица 7.1).
Таблица 7.1
|
Символы |
a1 |
a2 |
a3 |
a4 |
a5 |
a6 |
a7 |
a8 |
|
Кодовые комбинации |
000 |
001 |
010 |
100 |
011 |
101 |
110 |
111 |
|
Вероятности |
0.008 |
0.032 |
0.032 |
0.32 |
0.128 |
0.128 |
0.128 |
0.512 |
P(a1)=P(0)·P(0) ·P(0)=0.2·0.2·0.2=0.008;
P(a2)=P(0)·P(0) ·P(1)=0.2·0.2·0.8=0.032;
P(a3)=P(0)·P(1) ·P(0)=0.2·0.8·0.2=0.032;
P(a4)=P(1)·P(0) ·P(0)=0.8·0.2·0.2=0.032;
P(a5)=P(1)·P(0) ·P(0)=0.2·0.2·0.2=0.128;
P(a6)=P(1)·P(0) ·P(1)=0.2·0.2·0.2=0.128;
P(a7)=P(1)·P(1) ·P(0)=0.2·0.2·0.2=0.128;
P(a8)=P(1)·P(1) ·P(1)=0.8·0.8·0.8=0.512;
2. Составим сводную таблицу ветвления кодовых комбинаций по принципу:
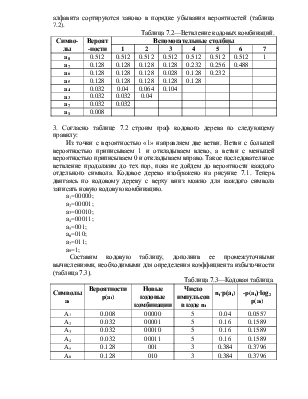
Два последних символа в начальном столбце, с наименьшими вероятностями, объединяют в одну группу и приписывают ей суммарную вероятность объединяемых символов в следующем столбце. Символы алфавита сортируются заново в порядке убывания вероятностей (таблица 7.2).
Таблица 7.2—Ветвление кодовых комбинаций.
|
Симво- лы |
Вероят-ности |
Вспомогательные столбцы |
||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
||
|
a8 |
0.512 |
0.512 |
0.512 |
0.512 |
0.512 |
0.512 |
0.512 |
1 |
|
a7 |
0.128 |
0.128 |
0.128 |
0.128 |
0.232 |
0.256 |
0.488 |
|
|
a6 |
0.128 |
0.128 |
0.128 |
0.028 |
0.128 |
0.232 |
||
|
a5 |
0.128 |
0.128 |
0.128 |
0.128 |
0.128 |
|||
|
a4 |
0.032 |
0.04 |
0.064 |
0.104 |
||||
|
a3 |
0.032 |
0.032 |
0.04 |
|||||
|
a7 |
0.032 |
0.032 |
||||||
|
a1 |
0.008 |
|||||||
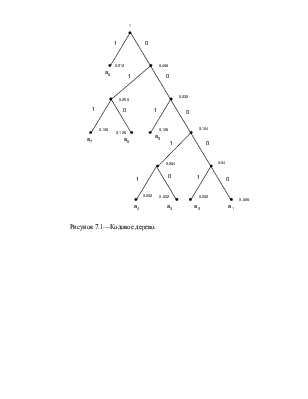
3. Согласно таблице 7.2 строим граф кодового дерева по следующему правилу:
Из точки с вероятностью «1» направляем две ветви. Ветви с большей вероятностью приписываем 1 и откладываем влево, а ветви с меньшей вероятностью приписываем 0 и откладываем вправо. Такое последовательное ветвление продолжим до тех пор, пока не дойдем до вероятности каждого отдельного символа. Кодовое дерево изображено на рисунке 7.1. Теперь двигаясь по кодовому дереву с верху вниз можно для каждого символа записать новую кодовую комбинацию.
а1=00000;
а2=00001;
а3=00010;
а4=00011;
а5=001;
а6=010;
а7=011;
а8=1;
Составим кодовую таблицу, дополнив ее промежуточными вычислениями, необходимыми для определения коэффициента избыточности (таблица 7.3).
Таблица 7.3—Кодовая таблица.
|
Символы ai |
Вероятности p(ai) |
Новые кодовые комбинации |
Число импульсов в коде ni |
ni·p(ai) |
-p(ai)·log2 p(ai) |
|
A1 |
0.008 |
00000 |
5 |
0.04 |
0.0557 |
|
A2 |
0.032 |
00001 |
5 |
0.16 |
0.1589 |
|
A3 |
0.032 |
00010 |
5 |
0.16 |
0.1589 |
|
A4 |
0.032 |
00011 |
5 |
0.16 |
0.1589 |
|
A5 |
0.128 |
001 |
3 |
0.384 |
0.3796 |
|
A6 |
0.128 |
010 |
3 |
0.384 |
0.3796 |
|
A7 |
0.128 |
011 |
3 |
0.384 |
0.3796 |
|
A8 |
0.512 |
1 |
1 |
0.512 |
0.4945 |
Средняя длина кодовой комбинации вычисляется по формуле:
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.