Правила нормализации таблиц, действующие в рамках концепции реляционной модели, рекомендуют разбивать данные на множество таблиц. Следовательно, в базе данных, разработанной в соответствии с концепцией реляционной модели, информация, как правило, хранится в нескольких связанных между собой таблицах. Поэтому, для получения достаточно полной информации из такой базы данных обычно требуется извлекать данные из нескольких таблиц (Рисунок 1). SQL позволяет получать информацию из двух и более таблиц путем формирования многотабличных запросов.
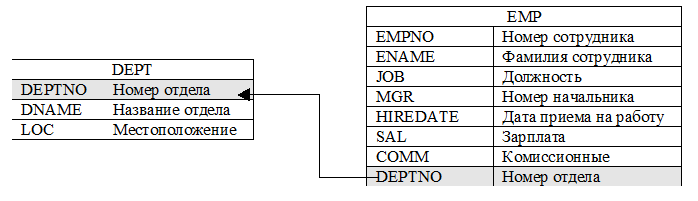
Рисунок 1 Таблицы, связанные отношением «первичный ключ/внешний ключ»
Основой многотабличного запроса является объединение таблиц, получающееся в результате формирования пар строк путем сравнения содержимого соответствующих столбцов. Поэтому очень важной является задача выбора столбцов для объединения таблиц. Лучше всего для этой цели подходят столбцы, являющиеся первичным или внешним ключом. Причем, если ключ является составным, объединение можно производить по всем входящим в него столбцам. Объединение на основе отношения «первичный ключ/внешний ключ» подразумевает совместимость таблиц, что обеспечивает целостность данных.
Чтобы информация, полученная в результате многотабличного запроса, была полноценной, необходимо, чтобы сравниваемые столбцы имели одинаковые или совместимые (т.е. такие, которые можно преобразовать друг в друга) типы данных. Значения, содержащиеся в столбцах, по которым производится объединение, должны быть сравнимыми. Например, столбцы DNAME и ENAME (Рисунок 1) имеют один тип данных, но объединять таблицы на основе этих столбцов не имеет смысла, т.к. информация, полученная в результате сравнения названия отдела с фамилией сотрудника, не будет иметь никакой ценности. Имена сравниваемых столбцов могут быть разными, хотя чаще всего они совпадают. Если в столбцах, по которым производится сравнение, имеются неопределенные значения, то они пропускаются, т.к. неопределенное значение не может быть равно никакому, в том числе неопределенному, значению. Связанные столбцы можно не включать в результирующее множество, т.к. чаще всего они представляют собой идентификаторы, которые сами по себе интереса не представляют.
Основные типы объединения таблиц:
§ Эквисоединения (объединение по равенству)
§ Не-эквисоединения (объединения по неравенству)
Кроме этого существуют следующие типы объединения таблиц
§ Внешние соединения
§ Соединения с собой (самообъединения)
Все рассмотренные типы объединения таблиц могут быть получены путем составления многотабличного запроса и представляют собой объединение столбцов из разных таблиц. Если Вы хотите объединить не столбцы, а строки таблиц, многотабличный запрос Вам не поможет. В этом случае необходимо использовать операторы множеств, которые позволяют объединять строки из разных таблиц, не основываясь на сравнении значений из соответствующих столбцов.
В связи с тем, что многотабличные запросы выполняются путем сравнения столбцов, оператор SELECT должен содержать условие поиска, которое определяет соотношение столбцов. Если условие поиска опущено или недействительно, результирующее множество будет содержать все возможные комбинации пар строк из обеих таблиц (декартово произведение). В примере ниже показано декартово произведение двух таблиц: DEPT, состоящей из 4-х строк и EMP, содержащей 14 строк. Результирующее множество представляет собой таблицу, состоящую из 56 (4´14) строк.
SQL> SELECT d.deptno, dname, e.deptno, ename FROM dept d, emp e;
DEPTNO DNAME DEPTNO ENAME
--------- -------------- --------- ----------
10 ACCOUNTING 20 SMITH
20 RESEARCH 20 SMITH
30 SALES 20 SMITH
40 OPERATIONS 20 SMITH
10 ACCOUNTING 30 ALLEN
20 RESEARCH 30 ALLEN
30 SALES 30 ALLEN
40 OPERATIONS 30 ALLEN
…
56 rows selected.
Чтобы избежать декартова произведения, используйте условие соединения таблиц. Причем минимальное количество условий соединения должно быть равно количеству объединяемых таблиц минус один. Это правило может не относиться к таблицам, первичный ключ которых состоит из нескольких столбцов, т.к. уникальный идентификатор строк такой таблицы предполагает несколько значений. Условия соединения, как правило, объединяются с помощью логического оператора AND, т.к. оператор OR недостаточно ограничивает объединение таблиц.
SELECT [DISTINCT] {*, таблица1.столбец [псевдоним], …}
FROM таблица1, таблица2, …
[WHERE условие соединения]
[ORDER BY {столбец | псевдоним | позиция} [ASC | DESC];
Для корректного построения многотабличного запроса необходимо задать условие соединения таблиц. Условие соединения указывается в предложении WHERE. Перед именами столбцов в списке SELECT рекомендуется указывать имена соответствующих таблиц. Имя таблицы отделяется точкой от имени столбца. Это правило носит рекомендательный характер в том случае, если имена столбцов, перечисленных в списке SELECT, уникальны (имеются только в одной таблице). Если Вы запрашиваете столбцы с одинаковыми именами из разных таблиц, обязательно указывайте имена таблиц перед именами столбцов.
SQL> SELECT deptno, dname, deptno, ename
2 FROM dept, emp
3 WHERE deptno=deptno;
WHERE deptno=deptno
*
ERROR at line 3:
ORA-00918: column ambiguously defined
SQL> SELECT dept.deptno, dname, emp.deptno, ename
2 FROM dept, emp
3 WHERE dept.deptno=emp.deptno;
DEPTNO DNAME DEPTNO ENAME
--------- -------------- --------- ----------
10 ACCOUNTING 10 CLARK
10 ACCOUNTING 10 KING
10 ACCOUNTING 10 MILLER
20 RESEARCH 20 SMITH
20 RESEARCH 20 ADAMS
20 RESEARCH 20 FORD
20 RESEARCH 20 SCOTT
20 RESEARCH 20 JONES
30 SALES 30 ALLEN
30 SALES 30 BLAKE
30 SALES 30 MARTIN
30 SALES 30 JAMES
30 SALES 30 TURNER
30 SALES 30 WARD
14 rows selected.
Имена таблиц могут оказаться слишком длинными. В этом случае при составлении корректного запроса код SQL может оказаться очень большим, что увеличит время отклика, т.к. на обработку такого запроса понадобится больше времени. Чтобы уменьшить код SQL, и, следовательно, ускорить выполнение запроса, используйте псевдонимы вместо имен таблиц в многотабличных запросах. Использование псевдонима таблицы при однотабличном запросе может, наоборот, увеличить время отклика.
SQL> SELECT d.deptno, d.dname, e.deptno, e.ename
2 FROM dept d, emp e
3 WHERE d.deptno=e.deptno;
DEPTNO DNAME DEPTNO ENAME
--------- -------------- --------- ----------
10 ACCOUNTING 10 CLARK
10 ACCOUNTING 10 KING
10 ACCOUNTING 10 MILLER
20 RESEARCH 20 SMITH
20 RESEARCH 20 ADAMS
20 RESEARCH 20 FORD
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.



