§ для каждого некластерного индекса, созданного для таблицы, значение indid может варьировать от 2 до 251;
§ если в таблице есть хотя бы одна колонка типа text, ntext или image, то в sysindexes добавляется строка с indid = 255.
Хипы
|
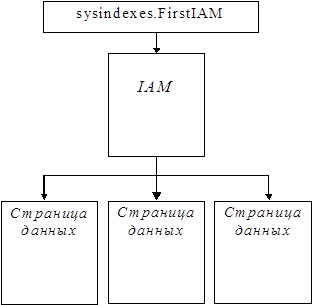
Колонка FirstIAM указывает на список IAM для набора страниц данных таблицы. Поскольку страницы в наборе страниц данных не объединены в список, для поиска нужной страницы сервер использует IAM-страницы. Сканирование таблицы базирующейся на хипе выполняется следующим образом: 1. Читается первый IAM первого файла (первой файловой группы) и сканируются все экстенты этого IAM. 2. Процесс повторяется с каждым IAM хипа в файле. 3. Действия 1 и 2 повторяются для каждого файла или файловой группы БД до тех пор, пока не будет обработан последний IAM для хипа. |
|
Кластерные индексы
|
|
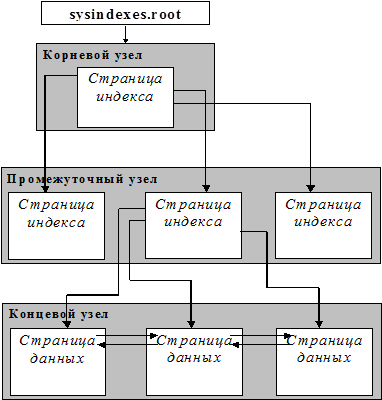
Колонка root таблицы sysindexes указывает на начало B-tree дерева кластерного индекса. Сервер использует дерево индекса для поиска страниц данных: § SQL Server перемещается вниз по индексу, чтобы найти строку данных, соответствующую значению ключа. § Для нахождения диапазона ключевых значений SQL Server перемещается вниз по индексу, чтобы найти начальное ключевое значение диапазона, а затем сканирует страницы данных, используя указатели на предыдущую и следующую страницы. § Чтобы найти первую страницу в списке страниц данных, SQL Server использует самый левый указатель в корневом узле индекса. |
Некластерные индексы
|
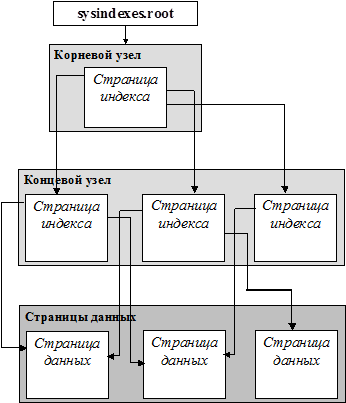
В колонке root содержится указатель на начало B-tree дерева некластерного индекса. Однако в отличие от кластерного индекса строки данных не отсортированы и хранятся в неупорядоченном порядке. Кроме того, концевые узлы индекса содержат не страницы данных, а индексные страницы. Каждая строка индекса содержит значение некластерного ключа, а также один или более указателей на строки данных, содержащих ключевые значения. Некластерный индекс может быть создан как для хипа, так и для кластерной таблицы. Указатель строки в строках некластерного индекса может иметь следующий вид: § для хипа – это указатель строки, который складывается из ID файла, номера страницы данных и номера строки на странице (Row ID) § для кластерной таблицы – это значение кластерного ключа для строки. Если кластерный индекс не уникален, SQL Server добавляет внутреннее значение, которое делает уникальными повторяющиеся ключи. SQL Server извлекает строки данных, используя ключ кластерного индекса, хранящийся в концевом узле некластерного индекса, и выполняя поиск по кластерному индексу. |
|
Данные типа text, ntext и image
Колонка FirstIAM указывает на список IAM-страниц, управляющий страницами text, ntext или image. Каждая таблица имеет только один набор страниц для данных типа text, ntext и image, содержащий данные такого типа для всех строк таблицы. Одна страница подобного типа может содержать данные нескольких строк. Более того, такая страница может содержать смесь из данных text, ntext и image.
SQL Server 6.5 и более ранних версий работал со страницами text, ntext и image, организованными в списки. В SQL Server 2000 страницы text, ntext и image логически организованы в B-tree структуру, что обеспечивает более быструю навигацию по такой структуре, т. к. не требует сканирования списка страниц.
Начальный экстент в диапазоне экстентов, отображаемых IAM, указан в заголовке страницы IAM. IAM содержит большую битовую карту, в которой каждый экстент представлен одним битом:
· значение бита равно 1 – соответствующий экстент выделен для объекта – собственника IAM.
Когда SQL Server должен вставить новую строку, а свободного пространства на текущей странице не достаточно, он использует страницы IAM и PFS, чтобы найти страницу со свободным пространством, достаточным для вставки данной строки. SQL Server использует страницы IAM, чтобы найти экстенты, выделенные для объекта. Для каждого такого экстента SQL Server просматривает страницы PFS, чтобы определить есть ли в экстенте страницы, на которых свободного места достаточно для содержания новой строки. Поскольку страницы IAM и PFS покрывают достаточно большое количество страниц данных, страниц IAM и PFS в базе данных немного, что позволяет хранить их в кэш буфере SQL Server.
SQL Server выделяет объекту новый экстент только в том случае, если он не может быстро найти страницу, имеющую достаточное количество свободного пространства, в существующем экстенте.
SQL Server 2000 автоматически сжимает базы данных, которые имеют большое количество свободного пространства и опция autoshrink для которых установлена в true. В этом случае сервер периодически проверяет использование пространства такой базой данных и автоматически уменьшает размер файлов данных, если обнаружит пустое пространство.
Сжать базу данных можно и вручную. Для этого используются команды DBCC SHRINKDATABASE и DBCC SHRINKFILE.
|
1. Дж. Пэйдж Вильям Использование Oracle8/8i: пер. с англ. – М.: Издательский дом "Вильямс", 1999.
2. SQL Server Books Online. (Интерактивная помощь в составе SQL Server).
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.