
Практика 06 (часть I).
Однофакторный дисперсионный анализ. Группировка данных по классифицирующему признаку.
Если вы хотите продвинуться в исследовании различий нескольких групп, то дальнейший анализ следует вести в диалоге Группировка и однофакторный дисперсионный анализ (Breakdown & one-way ANOVA). Мы применяем t-критерий, чтобы сравнить средние значения двух переменных. Если переменных больше двух, то применяется дисперсионный анализ. Английское сокращение дисперсионного анализа – ANOVA (analysis of variation).
6.1. Группировка данных по классифицирующему признаку.
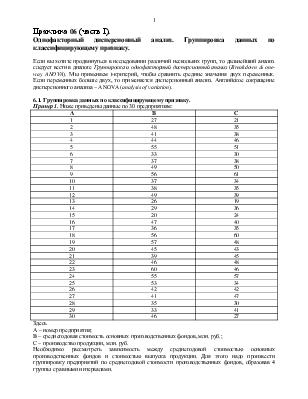
Пример 1. Ниже приведены данные по 30 предприятиям:
|
А |
В |
С |
|
1 |
27 |
21 |
|
2 |
48 |
35 |
|
3 |
41 |
38 |
|
4 |
44 |
46 |
|
5 |
55 |
51 |
|
6 |
33 |
30 |
|
7 |
37 |
38 |
|
8 |
49 |
50 |
|
9 |
56 |
61 |
|
10 |
37 |
34 |
|
11 |
38 |
35 |
|
12 |
49 |
39 |
|
13 |
26 |
19 |
|
14 |
29 |
36 |
|
15 |
20 |
24 |
|
16 |
47 |
40 |
|
17 |
36 |
35 |
|
18 |
56 |
60 |
|
19 |
57 |
48 |
|
20 |
45 |
43 |
|
21 |
39 |
45 |
|
22 |
46 |
48 |
|
23 |
60 |
46 |
|
24 |
55 |
57 |
|
25 |
53 |
34 |
|
26 |
42 |
42 |
|
27 |
41 |
47 |
|
28 |
35 |
30 |
|
29 |
33 |
41 |
|
30 |
46 |
27 |
Здесь
А – номер предприятия;
В – среднегодовая стоимость основных производственных фондов, млн. руб.;
С – производство продукции, млн. руб.
Необходимо рассмотреть зависимость между среднегодовой стоимостью основных производственных фондов и стоимостью выпуска продукции. Для этого надо произвести группировку предприятий по среднегодовой стоимости производственных фондов, образовав 4 группы с равными интервалами.
По каждой группе и совокупности всех предприятий определить:
Результаты группировки необходимо представить в сводной таблице.
 Шаг 1.
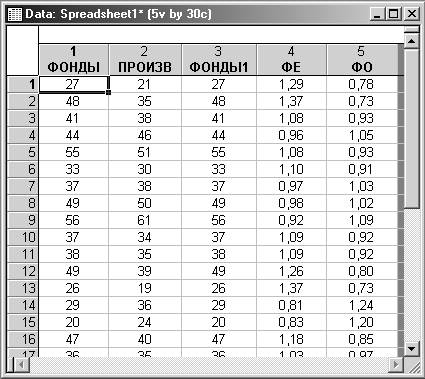
Создайте новый документ. В первый столбец (ФОНДЫ) и третий столбец (ФОНДЫ1) введите
производственные фонды (В), а во второй (ПРОИЗВ) – производство продукции (С).
В четвертый столбец (ФЕ) введите фондоемкость продукции - определяется путем
деления столбца ФОНДЫ на столбец ПРОИЗВ; в пятый (ФО) – фондоотдачу -
определяется путем деления столбца ПРОИЗВ на столбец ФОНДЫ.
Шаг 1.
Создайте новый документ. В первый столбец (ФОНДЫ) и третий столбец (ФОНДЫ1) введите
производственные фонды (В), а во второй (ПРОИЗВ) – производство продукции (С).
В четвертый столбец (ФЕ) введите фондоемкость продукции - определяется путем
деления столбца ФОНДЫ на столбец ПРОИЗВ; в пятый (ФО) – фондоотдачу -
определяется путем деления столбца ПРОИЗВ на столбец ФОНДЫ.
Шаг 2. Определите минимальное и максимальное значение среднегодовой стоимости производственных фондов по всем предприятиям (используйте опцию Описательные статистики (Descriptive Statistics)). Получим: max=60, min=20. Исходя из полученного размаха выборки R = 60 – 20 = 40, определим четыре интервала группировки: [20,30); [30,40); [40,50); [50,60].
Шаг 3. Чтобы произвести группировку переменной ФОНДЫ1 выделите столбец, вызовите на верхней панели инструментов меню Vars (переменные) и выберите Recode (перекодировка).
Шаг 4. В появившемся окне задайте границы интервалов таким образом:
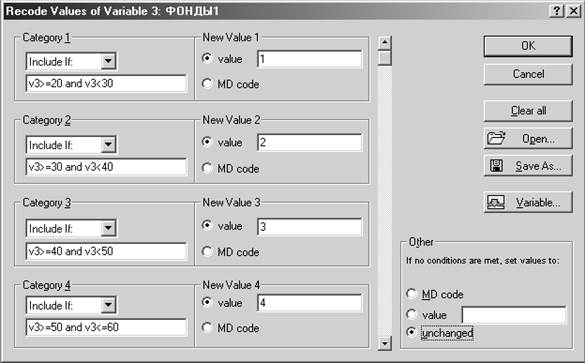
В третьем столбце вместо введенных данных появятся номера групп 1,2,3,4, в которые попали предприятия.
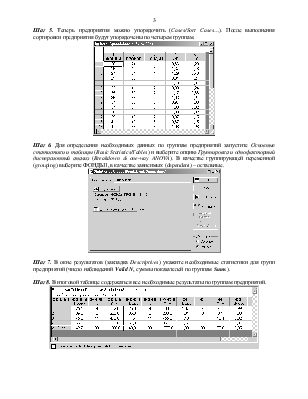
Шаг 5. Теперь предприятия можно упорядочить (Cases/Sort Cases…). После выполнения сортировки предприятия будут упорядочены по четырем группам.
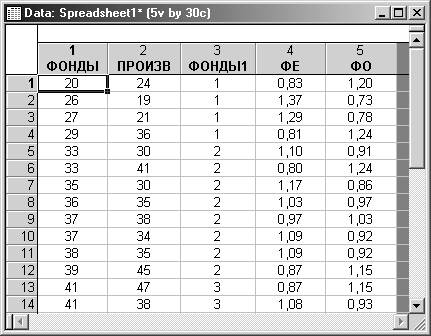
Шаг 6. Для определения необходимых данных по группам предприятий запустите Основные статистики и таблицы (Basic Statistics/Tables) и выберите опцию Группировка и однофакторный дисперсионный анализ (Breakdown & one-way ANOVA). В качестве группирующей переменной (grouping) выберите ФОНДЫ1, в качестве зависимых (dependent) – остальные.
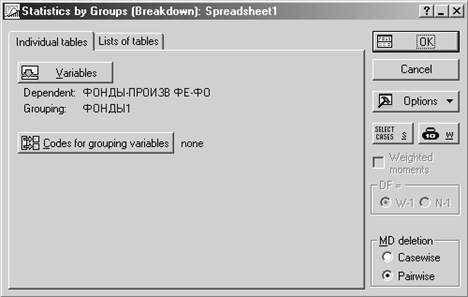
Шаг 7. В окне результатов (закладка Descriptives) укажите необходимые статистики для групп предприятий (число наблюдений Valid N, суммы показателей по группам Sums).
Шаг 8. В итоговой таблице содержаться все необходимые результаты по группам
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.