При
использовании того же регистра деления, что применяется при кодировании
(назовем его схемой деления второго типа), соответствие между векторами ошибок
и остатками на n такте будет иное. Теперь вместо вычисления синдрома
полинома U (x)
определяется синдром полинома хr U (x) (по модулю g (x)),
что равносильно, как указывалось выше, нахождению остатка от деления хr![]() на g (x).
Так, если ошибка появилась в старшем разряде
на g (x).
Так, если ошибка появилась в старшем разряде ![]() = х6,
то остаток от деления х6+3 = х9 на g (x) =
х3 + х + 1 равен х2, что в двоичном представлении – 100.
= х6,
то остаток от деления х6+3 = х9 на g (x) =
х3 + х + 1 равен х2, что в двоичном представлении – 100.
Табл. 8.2. является таблицей декодирования рассматриваемого выше кода при применении схемы деления 2-го типа.
Таблица 8.2.
|
Вектор ошибки |
Многочлен
|
Остаток r (x) |
Вектор ошибки |
Многочлен
|
Остаток r (x) |
|
0000000 |
0 |
000 |
0001000 |
Х3 |
101 |
|
1000000 |
Х6 |
100 |
0000100 |
Х2 |
111 |
|
0100000 |
Х5 |
010 |
0000010 |
Х1 |
110 |
|
0010000 |
Х4 |
001 |
0000001 |
Х0 |
011 |
На рис. 8.3 представлена схема декодирующего устройства, отвечающая данной таблице декодирования. ДО выделяет синдром 100, т.е. реализует логическую функцию у = авс.
При декодировании кодов с dмин = 4 все одиночные ошибки исправляются, а ошибки второй кратности обнаруживаются. Функционирование устройства в том случае отличается от рассмотренного выше тем, что при появлении в конце цикла коррекции остатка отличного от нуля, информация, записанная в выходном регистре, уничтожается. В схеме модуля стирание информации при обнаружении неисправляемых ошибок осуществляется на 2-м такте. Если остаток нулевой, то содержимое Вых.Р сохраняется.
Схема соответствующего устройства представлена на рис. 8.4. Она составлена для (7, 3)- кода, образующего многочлен
g (x) = x4 + x3 + x2 + 1.
Декодирование укороченных кодов
Для декодирования укороченных кодов возможно использовать аппаратуру полных циклических кодов при условии, что каждой укороченной комбинации предпосылается i нулей. Цикл декодирования укороченного кода при этом займет не n-i такт, а все n тактов.
Декодирование, однако, можно осуществлять быстрее,
если в генераторе синдрома одновременно с делением на g (x)
производить операцию умножения на хi. Тогда
вместо вычисления синдрома U (x) будет вычисляться синдром полинома хi U (x) (по модулю g (x)), что равносильно
нахождению остатка от деления ![]() хi
на g (x).
Эта операция позволяет сократить нахождение выделяемого синдрома на 2 i
тактов (за два цикла).
хi
на g (x).
Эта операция позволяет сократить нахождение выделяемого синдрома на 2 i
тактов (за два цикла).
В качестве примера рассмотрим построение декодирующего устройства укороченного (6, 3) – кода, g (x) = x3 + x + 1.
Укорочение кода на один информационный символ равносильно исключению из образующей матрицы (7, 4) – кода первой строки и левого столбца. Соответственно, для рассматриваемого кода:
G(6, 3) = 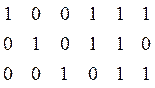
Если в регистре деления будем производить одновременно
операцию предварительного умножения на х1 и деления на g (x),
то выявленным синдромом опять явиться синдром 101, а нахождение его осуществляется
за n – 1 = 6 тактов.
Действительно, пусть вектор ошибки 100000 (искажен старший разряд), т.е. ![]() = х5. Тогда содержимое РД будет
отвечать делению многочлена х1
= х5. Тогда содержимое РД будет
отвечать делению многочлена х1 ![]() = х6.
= х6.
Из табл. 8.1. видно, что одночлену х6 принадлежит остаток 101. вектору ошибки 010000 теперь соответствует остаток от деления х1х4=х5 , т.е. остаток 111. Рассуждая дальше подобным образом, можно построить таблицу декодирования для (6, 3) – кода.
Схема декодирующего устройства представлена на рис. 8.5. Схема ориентирована на элементную базу лабораторного модуля.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.