}
Ранее мы уже рассматривали несколько шаблонов для проверки правильности почтовых адресов. Последним приближением к идеалу был шаблон:
pattern = @"\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+\2*";
Подробный разбор этого шаблона был приведен ранее. Его недостатком является то, что он не пропускает строк вида: "name@[999.999.999.999]", которые считаются правильными email-адресами. В них TCP / IP адрес host-компьютера задан в числовом формате.
Теперь, когда вы получили некоторый опыт в анализе и синтезе регулярных выражений, можно попытаться критически осмыслить тот шаблон для email, который мы привели в начале этой главы. Он присутствует в документации MSDN по теме "Regular Expressions Examples4Confirming Valid E-Mail Format". Напомним его.
@"^([\w-\.]+)@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.)|(([\w-]+\.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(\]?)$"
Первая часть шаблона "^([\w-\.]+)@" не должна вызвать у вас затруднений в прочтении и расшифровке.
|
Подстрока |
Смысл |
|
^ |
Запрет пробелов и других пустых символов в начале строки |
|
([\w-\.]+) |
Группа номер 1 содержит буквы, дефисы, точки |
|
@ |
Содержит символ @ |
Прежде чем приступить к разбору второй части шаблона, давайте выявим структуру всего выражения, то есть выделим все его группы (выражения в круглых скобках). Для этого заменим текст группы ее обозначением, например, вместо [\w-\.]+ поставим g1 (группа номер 1). Действуя таким образом, мы заменим все выражение такой схемой:
^ (g1) @ ( (g3) | ( (g5) ) ) (g6) (g7) $
Отсутствие обозначений для групп 0, 2 и 4 в этой схеме можно пояснить рисунком:
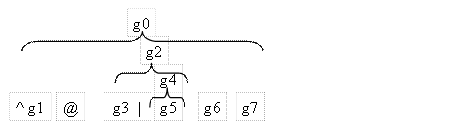
Группы нумеруются последовательно по мере появления скобок при движении слева-направо. Группа g2 представляет собой объединение ((g3)|((g5))) групп 3 и 4. Группа g4, как видно из текста, содержит внутри себя группу 5. Группа g3 представляет собой выражение:
(\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.)
которое (с точностью до символа '[') мы рассматривали ранее. Его суть предоставить возможность указать адрес почтового сервера в виде трех групп цифр. Сведем описание всех групп в таблицу. Заполните ее.
|
Группа |
Текст |
Функция |
|
g0 |
Вся строка шаблона |
|
|
g1 |
([\w-\.]+) |
|
|
g2 |
( (g3) | (g4) ) |
|
|
g3 |
(\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.) |
|
|
g4 |
( (g5) ) |
|
|
g5 |
([\w-]+\.)+) |
|
|
g6 |
([a-zA-Z]{2,4}|[0-9]{1,3}) |
|
|
g7 |
(\]?) |
Анализируя схему шаблона выражения, приходим к выводу, что одна из групп (g4) является архитектурным излишеством. Уберите в строке шаблона образующие ее скобки и убедитесь, что шаблон работает и производит тот же результат, но групп стало на одну меньше.
Схема, видимо, неточна, так как она пропускает адрес вида:
text = "....@-.-.-.com]";
Немного лучше работает шаблон:
text = @"^\w+([-.]\w+)*@((\[\d{1,3}\.\d{1,3}\.\d{1,3}\.)|\w+([-.]\w+)*)([a-zA-Z]{2,4}|\d{1,3})(\]?)$";
Недостатком автоматической нумерации групп является то, что при редактировании выражения (удалении или добавлении новых пар скобок) нумерация групп изменяется и существующие ссылки на группы становятся недействительными. Microsoft-расширение языка регулярных выражений имеет еще один механизм образования групп, который свободен от упомянутого недостатка. Этот механизм использует такую конструкцию группы: (?<name>...). Здесь name — это имя группы. Следующий пример, который приведен в MSDN, как пример шаблона адреса email, использует две именованные группы: <user> и <host>.
Regex ex = new Regex ("(?<user>[^@]+)@(?<host>.+)");
Первая, кроме имени, имеет тело [^@]+, которое требует наличия хотя бы одного символа, не являющегося спецификатором @. Вторая группа .+ допускает наличие произвольных символов. Между группами расположен символ @. Он требует наличия этого символа в испытуемой строке текста. Следующий фрагмент позволяет убедиться в том, что именованные группы действительно получили заданные имена.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.