Когда вы используете DROP_EXISTING, примите к сведению следующие факты и рекомендации:
![]() Для кластерного индекса сервер требует пространство для
физического перестроения индекса;
Для кластерного индекса сервер требует пространство для
физического перестроения индекса;
![]() Опция DROP_EXISTING
ускоряет процесс построения кластерного и не кластерного индекса с помощью исключения
процесса сортировки;
Опция DROP_EXISTING
ускоряет процесс построения кластерного и не кластерного индекса с помощью исключения
процесса сортировки;
![]() Вы не можете перестроить индексы на системной таблице;
Вы не можете перестроить индексы на системной таблице;
![]() Опция DROP_EXISTING
на кластерном индексе помогает вам избежать ненужной работы по удалению и
воссозданию не кластерного индекса, если кластерный индекс перестраивается на той
же колонке;
Опция DROP_EXISTING
на кластерном индексе помогает вам избежать ненужной работы по удалению и
воссозданию не кластерного индекса, если кластерный индекс перестраивается на той
же колонке;
![]() Не кластерный индекс перестраивается только однажды и если ключи
разные.
Не кластерный индекс перестраивается только однажды и если ключи
разные.
Пример
Этот пример перестраивает существующие индексы. Индекс перестраивается как кластерный, составной со значением заполнения страниц 65%. Этот оператор выдаст ошибку, если кластерный индекс для данной таблицы уже существует:
CREATE UNIQUE NONCLUSTERED INDEX U_OrdID_ProdID
ON [Order Details] (OrderID, ProductID)
WITH DROP_EXISTING, FILLFACTOR=65
Выполните следующий код для создания индекса:
USE ClassNorthwind
SET NOCOUNT ON
GO
/*
** If the objects already exist (i.e. if this is a rebuild), drop them.
*/
IF EXISTS (SELECT name FROM sysindexes WHERE name =
'Orders_Customers_link')
DROP INDEX Orders.Orders_Customers_link
GO
/* Create the Index with a FILLFACTOR of 75 */
CREATE NONCLUSTERED INDEX Orders_Customers_link ON Orders(CustomerID)
WITH FILLFACTOR = 75
GO
SET NOCOUNT OFF
GO
Для получения информации о индексе выполните:
EXEC sp_help Orders
Рассмотрите в качестве дополнительного примера скрипт из файла CreaIndx2.SQL.
Для проверки структуры индекса используйте скрипт из файла ExamIndex.SQL.
Статистика созданная для индекса, также может быть создана для колонки. Так как оптимизатор запросов использует статистику для оптимизации запросов, вы должны знать, как они собраны, хранятся, созданы, обновлены, просматриваются.
Сервер SQL собирает статистику с помощью чтения всех значений колонок или шаблона значений колонок для создания равномерного распределённого и отсортированного списка значений, известного как распределённые шаги. Сервер SQL динамически определяет процент строк, которые должны быть опробованы, основываясь на количестве строк в таблице. Оптимизатор запросов выполняет одно из двух – полное сканирование или шаблоны строк при сборке статистики.
![]() Опция SAMPLE (шаблон) – это значение по умолчанию для обновления и
создания статистики;
Опция SAMPLE (шаблон) – это значение по умолчанию для обновления и
создания статистики;
![]() Опция FULLSCAN (полное сканирование) используется когда:
Опция FULLSCAN (полное сканирование) используется когда:
o Создаётся индекс;
o Опция FULLSCAN указана в операторе CREATE STATISTICS.
o Выполнен оператор UPDATE TATISTICS.
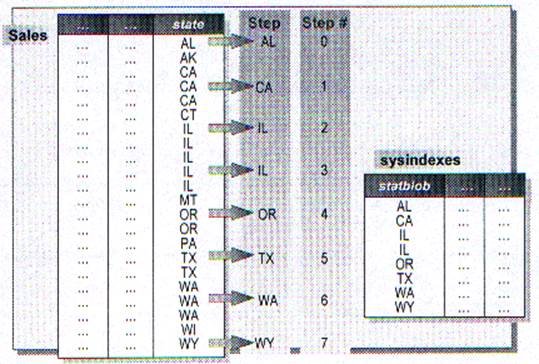
Каждое значение, хранящееся в колонке, называется распределённым шагом. Распределённый шаг ссылается на пространство между шаблонами или как много строк существует между началом и концом шага. Первое и последнее значение всегда включаются в статистику. Здесь может быть до 300 значений.
В дополнении сохраняется:
![]() Дата и время, когда статистика последний раз обновлялась;
Дата и время, когда статистика последний раз обновлялась;
![]() Количество строк в таблице;
Количество строк в таблице;
![]() Количество строк шаблона для создания гистограммы и определения
плотности;
Количество строк шаблона для создания гистограммы и определения
плотности;
![]() Количество распределённых шагов;
Количество распределённых шагов;
![]() Среднее значение ключа;
Среднее значение ключа;
![]() Плотность индивидуальной колонки и всех комбинированных колонок;
Плотность индивидуальной колонки и всех комбинированных колонок;
![]() Количество строк, попавших шаг гистограммы;
Количество строк, попавших шаг гистограммы;
![]() Количество строк, которые равны значению верхней границы шага;
Количество строк, которые равны значению верхней границы шага;
![]() Количество определённых значений в шаге гистограммы.
Количество определённых значений в шаге гистограммы.
Вы можете создавать статистику автоматически или вручную. Однако, вы должны позволять серверу SQL создавать для вас статистику автоматически.
Когда опция базы данных auto create statistics включена, сервер автоматически предоставляет для вас статистику для:
![]() Индексных колонок, которые содержат данные;
Индексных колонок, которые содержат данные;
![]() Не индексированных колонок, которые используются для объединения.
Не индексированных колонок, которые используются для объединения.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.