Когда необходимо добавить новый код в таблицу, используется хэшфункция в процедуре find_match для генерации корректного i. Процедура find_match генерирует адрес и затем проверяет, не использовался ли он уже. Если это так, то find_match выполняет вторую пробу и так до тех пор, пока не найдется свободное место. Хэш-функция, использованная в этой программе - простая "xor"-типа хэш-функция. Префикс кода и добавочный символ комбинируются для формирования адреса массива. Если содержимое префикса кода и символ в массиве сопоставляются им, то возвращается корректный адрес. Если элемент массива по этому адресу уже использован, выполняется фиксированное смещение для поиска нового места. Это выполняется до тех пор, пока не будет найдено свободное место или не произойдет сопоставление. Среднее число поисков в такой таблице - меньше 3, если используется таблица на 10-15% большего размера, чем необходимо. Оно может быть улучшено путем увеличения размера таблицы, однако для реализации на микроконтроллере это не приемлемо. Такое небольшое число обращений к словарю делает данную реализацию, в отличие от стандартной, с использованием бинарного дерева, гораздо более быстрой и позволяет существенно снизить стоимость информации по времени, за счёт чего, собственно и может быть повышена производительность системы «устройство-ЭВМ». Необходимо отметить, что для того, чтобы порядок вторичных проб работал, размер таблицы должен быть простым числом. Это объясняется тем, что проба может быть любым целым между 1 и размером таблицы. Если проба и размер таблицы не являются взаимно простыми, поиск свободных мест может закончиться неудачей, даже если они есть.
Реализация алгоритма распаковки имеет свой набор проблем. Одна из проблем алгоритма сжатия здесь исчезает. Когда выполняется сжатие, необходимо организовать поиск в таблице для данной строки. При распаковке необходимо организовать просмотр для отдельного кода. Это означает, что можно хранить префиксы кодов и добавочные символы, индексируясь по их строковому коду. Это устраняет необходимость в хэш-функции и освобождает массив, использовавшийся для хранения значений кодов.
К сожалению метод, использованный для хранения строковых величин, приводит к тому, что декодировка строк должна выполняться в инверсном порядке. Это значит, что все символы для данной строки при декодировании должны помещаться в стековый буфер, а затем выводиться в обратном порядке. В приведенной программе это выполняется функцией decode_string.
Проблема появляется, когда чтение входного потока прерывается при достижении конца потока. Для этого частного случая в программе зарезервирован последний определяемый код MAX_VALUE как признак конца данных. Это не является необходимым при чтении файла, но может помочь при чтении буфера сжатых данных из памяти. Затраты на потерю одного определяемого кода весьма малы сравнительно со всем процессом.
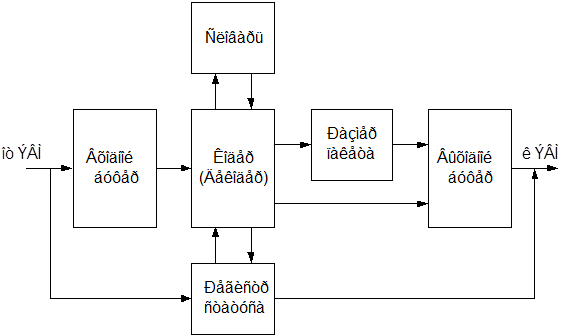 |
Рисунок 2.1. Схема работы микропрограммы устройства.
После включения или сброса компьютера, а также при сбое питания, сигнал RESET DRV с шины ISA (или RESET LPT-порта) переводит в начальное состояние. Программное обеспечение, которому нужно сжать информацию, производит чтение регистра состояния устройства. Если устройство готово к приёму данных, ПО последовательно записывает данные в регистр данных устройства. Запись производится побайтно, в режиме программного обмена. Записывать можно не более 16 килобайт. (Более подробная информация об особенностях протокола обмена между устройством и компьютером в обоих вариантах исполнения расположена в разделах «Описание принципиальной схемы устройства для варианта реализации на шине ISA» и «Описание принципиальной схемы устройства для LPT-порта»). Когда все данные переданы, ПО производит операцию записи в регистр состояния устройства. Записанное слово состояния содержит информацию о том, какую операцию необходимо выполнить над принятым блоком данных. В ответ устройство выводит в регистр состояния слово, говорящее о его занятости, и приступает к стадии сжатия, в случае, если слово записанное в регистр состояния слово содержит код сжатия. В случае его отсутствия выполняется программа распаковки.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.