






<!-- Сжатие LZ77, LZ78 и LZW (LZ77, LZ78 & LZW Compress) -->
Основная идея, используемая в замещающих компрессорах, состоит в замене появления определенной фразы или группы байт во фрагменте данных ссылкой на предыдущее появление этой фразы. Существуют два основных класса методов, названных в честь Якоба Зива (Jakob Ziv) и Абрахама Лемпеля (Abraham Lempel), впервые предложивших их в 1977 и 1978.
Алгоритм LZ78 вносит все встреченные им последовательности в словарь. Всякий раз, когда среди данных, которые надо сжать, встречается последовательность, программа обращается к словарю:
· если последовательность находится в словаре, то в выходной файл заносится код для этой записи;
· если последовательность представляет собой расширенный вариант последовательности из словаря, то она добавляется в таблицу.
Например, если программа сжатия уже имеет последовательность ABC в словаре и увидит последовательность ABCA, то она вначале занесет в выходной файл код из словаря для ABC, затем для символа A, после чего последовательность ABCA будет добавлена в словарь. Если же она позже встретит ABCAB, то выведет код для ABCA, затем код для символа B и добавит ABCAB в словарь. Каждый раз, когда программа встречает последовательность из словаря, она выдает код и добавляет новую запись, которая на один байт длиннее. Таким образом, каждый раз при повторении последовательности байтов, словарь должен будет расти, чтобы включить продолжение этой последовательности. Обратите внимание на то, что программа должна встретиться с последовательностью ABCABC по крайней мере 6 раз (по числу букв), прежде чем в словаре будет создана запись, содержащая всю последовательность.
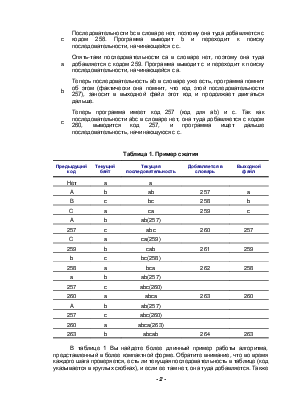
Фактически, предшествующий абзац немного искажает реальную картину. Программа сжатия обрабатывает в каждый момент времени лишь один, а не несколько байтов, хотя конечный результат остается по-прежнему таким же. Первоначально словарь содержит всевозможные однобайтовые значения, пронумерованные от 0 до 255, и одну дополнительную запись с номером 256 (о ней я расскажу немного позже). Давайте посмотрим, как программа сжатия LZ читает каждый байт abcabc.
|
a |
Уже есть в словаре, и программа сжатия знает об этом. Поэтому она запоминает этот символ и переходит к следующему байту. |
|
b |
Последовательности ab в словаре нет, поэтому она туда добавляется с присваиваемым ей кодом 257. Программа выводит в выходной файл а и начинает накапливать последовательность, начинающуюся с b. |
|
c |
Последовательности bc в словаре нет, поэтому она туда добавляется с кодом 258. Программа выводит b и переходит к поиску последовательности, начинающейся с с. |
|
a |
Опять-таки последовательности са в словаре нет, поэтому она туда добавляется с кодом 259. Программа выводит с и переходит к поиску последовательности, начинающейся с а. |
|
b |
Теперь последовательность ab в словаре уже есть, программа помнит об этом (фактически она помнит, что код этой последовательности 257), заносит в выходной файл этот код и продолжает двигаться дальше. |
|
c |
Теперь программа имеет код 257 (код для ab) и с. Так как последовательности abc в словаре нет, она туда добавляется с кодом 260, выводится код 257, и программа ищет дальше последовательность, начинающуюся с с. |
Таблица 1. Пример сжатия
|
Предыдущий код |
Текущий байт |
Текущая последовательность |
Добавляется в словарь |
Выходной файл |
|
Нет |
a |
a |
||
|
A |
b |
ab |
257 |
a |
|
B |
c |
bc |
258 |
b |
|
C |
a |
ca |
259 |
c |
|
A |
b |
ab(257) |
||
|
257 |
c |
abc |
260 |
257 |
|
C |
a |
ca(259) |
||
|
259 |
b |
cab |
261 |
259 |
|
b |
c |
bc(258) |
||
|
258 |
a |
bca |
262 |
258 |
|
a |
b |
ab(257) |
||
|
257 |
c |
abc(260) |
||
|
260 |
a |
abca |
263 |
260 |
|
A |
b |
ab(257) |
||
|
257 |
c |
abc(260) |
||
|
260 |
a |
abca(263) |
||
|
263 |
b |
abcab |
264 |
263 |
В таблице 1 Вы найдете более длинный пример работы алгоритма
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.