ГОУ ВПО НГТУ
Кафедра прикладной математики
по Методам трансляции
Группа: ПМ – 54
Студентки: Красноштанова И.В.
Старкова О.А.
Преподаватели: Еланцева И.Л.
Полетаева И.А.
Новосибирск
2008
1.Текст задания.
1) проектирование таблиц лексем, используемых в трансляторе;
2) проектирование блока лексического анализа (сканер);
3) проектирование блока синтаксического анализа;
4) проектирование генератора кода.
2.Вариант задания.
Подмножество языка С++ включает:
· данные типа int;
· инструкции описания переменных;
· операторы присваивания, while любой вложенности и в любой последовательности;
· операции +, – , < =, >= , < , >.
3.Анализ.
3.1
В данной задачи используется 2 типа таблиц: постоянные и переменные.
К постоянным относятся:
К переменным относятся:
Таблицы имеют функции добавления и поиска элементов, добавления атрибутов.
3.2
Сканер просматривает литеры исходной программы слева направо и строит лексемы программы – константы (целого и символьного типов), переменные (идентификаторы), ключевые слова, знаки операций и разделители. При этом проверяется соответствие литер заданному алфавиту и соответствие правилам построения лексем. На этой стадии проверяется правильность использования комментариев вида // и /* */, а также их исключение. Сканер заносит отсутствующие константы и переменные в таблицы, разработанные в л/р №1. Сканер создает файл токенов, в котором всем лексемам соответствуют пары чисел (число1, число2), где число1- номер таблицы, к которой относится лексема, число2- позиция в этой таблице. Для ключевых слов, разделителей и знаков операций- порядковый номер, а для идентификаторов и констант- это число, у которого две последние цифры обозначают порядковый номер в строке, а впередистоящие цифры показывают номер строки в таблице.
Ошибки, которые могут возникать на данном этапе, это:
1. Недопустимый символ.
2. Недопустимый идентификатор или константа.
Диаграмма состояния сканера.
D – класс цифр
L – класс букв A,B,…,Z,a,b,…,z
Raz – {+ , - , = , <= , >= , < , > , ( , ) , { , } , ; , , , _ , \n , \t , // , /*}
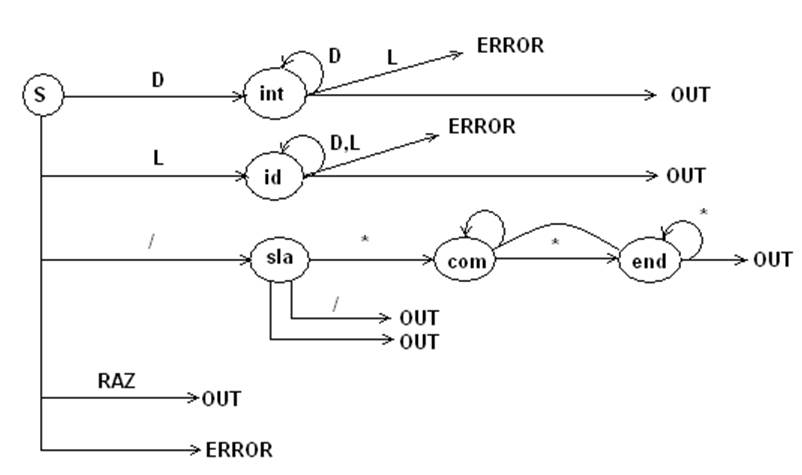
3.3
Источником входных данных является текстовый файл токенов с именем «token.txt», сформированный в лабораторной работе №2.
Выходными данными являются файл постфиксных записей и файл ошибок.
В файле ошибок указывается классификация ошибки и неправильно используемый терм.
Файл постфиксной записи строится до встречи синтаксической ошибки (ошибки объявления переменных не учитываются).
Ключевые слова на этапе синтаксического анализа не исключаются.
Схема разбора для LL-грамматики.
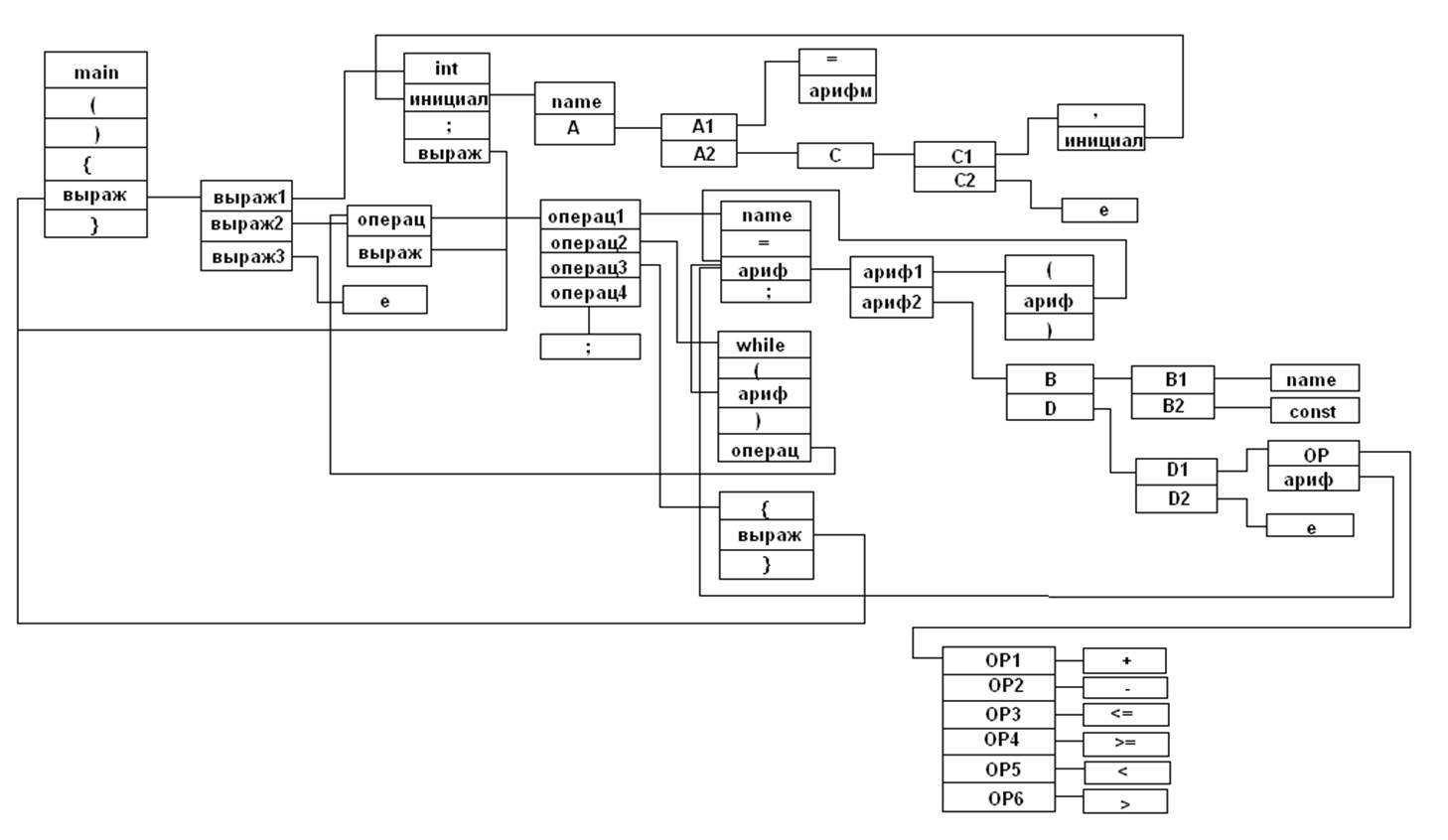
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.




