Задание
Обращение матрицы A размером N*N можно выполнить с помощью разложения в ряд:
![]()
где ![]() ,
, 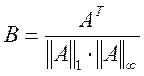 ,
,
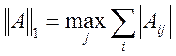 ,
,
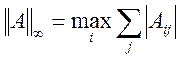 ,
,
I – единичная матрица (на диагонали – единицы, остальные – нули).
Тип данных float.
Размер N предполагается кратным четырем.
N=512,
Число шагов 10.
Ключ компиляции О2
Характеристика компьютера:
Процессор: Intel (R) Core (TM)2 DUO CPU E6600 @ 2.40 GHz
ОП: 3072 Mb
ОС: Microsoft Windows XP SP3
Текстпрограммы:
#include <stdio.h>
#include <conio.h>
#include <time.h>
#include <stdlib.h>
#include <xmmintrin.h>
#include <math.h>
#define N 512
#define iter 10
float proizv (float *x,float *y) //умножение матриц с SSE
{
float summa;
int i;
__m128 *xx,*yy;
__m128 p,s;
xx=(__m128 *)x;
yy=(__m128 *)y;
s=_mm_set_ps1(0); // устанавливает четыре значения, выровненные по адресу
for (i=0;i<N/4;i++)
{
p=_mm_mul_ps(xx[i], yy[i]); // векторное умножение 4 чисел
s=_mm_add_ps(s,p); // векторная сумма
}
p=_mm_movehl_ps(p,s); // перемещение 2-х старших значений s в младшие p
s=_mm_add_ps(s,p); // сложение
p=_mm_shuffle_ps(s,s,1); // перемещение 2-го значения s в младшую позицию p
s=_mm_add_ss(s,p); // сложение
_mm_store_ss(&summa,s); // запись младшего значения в память
return summa;
}
void dot (float A[],float B[],float C[]) // произведение векторов с SSE
{
int i,j,k;
float *mas;
mas = new float[N*N];
for(i = 0;i<N;i++)
for(j = 0;j<N;j++)
mas[j*N+i] = B[i*N+j];// транспанирование
for(i = 0;i<N;i++)
for(j = 0;j<N;j++)
C[i*N+j] = proizv(&A[i*N],&mas[j*N]); // произведение
}
void add (float A[],float B[],float C[]) // сложение векторов с SSE
{
int i,j,k;
__m128 p,s;
for(i=0;i<N;i++)
{ __m128 *xx,*yy;
xx=(__m128*)&A[i*N];
yy=(__m128*)&B[i*N];
for(k = 0;k<N/4;k++)
{ p=_mm_add_ps(xx[k],yy[k]); //сложение
_mm_store_ps(&C[i*N+k*4],p); // записать четыре значения по выровненному адресу
}
}
}
void sub (float A[],float B[],float C[]) // вычитание векторов с SSE
{
int i,j,k;
__m128 p;
for(i = 0;i<N;i++)
{
for(k = 0;k<N/4;k++)
{
__m128* xx,*yy;
xx=(__m128*)&A[i*N];
yy=(__m128*)&B[i*N];
p = _mm_sub_ps(xx[k],yy[k]); // векторное вычитание 4-х чисел
_mm_store_ps(&C[i*N+k*4],p); // запись младшего значения в память
}
}
}
double S_SSE(float mas[],float BB[])
{
float *I,*B,*R,*C,*sib,max1,maxst;
int summa,i,j;
clock_t start1;
I = new float[N*N];
B = new float[N*N];
R = new float[N*N];
C = new float[N*N];
sib = new float[N*N];
max1 = 0;
summa = 0;
for(i = 0;i<N;i++)
{
for(j = 0;j<N;j++)
summa = summa + fabs(mas[i*N+j]);
if(summa>max1)
max1 = summa;
}
maxst = 0;
summa = 0;
for(j = 0;j<N;j++)
{
for(i = 0;i<N;i++)
summa = summa + fabs(mas[i*N+j]);
if(summa>maxst)
maxst = summa;
}
for(i = 0;i<N;i++)
for(j = i;j<N;j++)
{
B[(i)*N+(j)] =mas[(j)*N+(i)] /(max1*maxst);
B[(i)*N+(j)] =mas[(j)*N+(i)]/(max1*maxst);
}
for(i = 0;i<N;i++)
for(j=0;j<N;j++)
if(i==j)
I[i*N+j] = 512;
else
I[i*N+j] = 1;
dot(mas,B,C);
sub(I,C,R);
for(i = 0;i<N;i++)
for(j = 0;j<N;j++)
{
BB[(i)*N+(j)] = I[i*N+j];
sib[i*N+j] = I[i*N+j];
}
start1 = clock(); // замеряем время
for(int s = 1;s<=iter;s++)
{
dot(sib,R,C);
for(i = 0;i<N;i++)
for(j = 0;j<N;j++)
sib[i*N+j] = C[i*N+j];
add(BB,sib,BB);
}
dot(BB,B,C);
start1 = clock() - start1; // конец замеры времени
for(i = 0;i<N;i++)
for(j = 0;j<N;j++)
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.



