Таблица представляет собой список состояний с множествами выбора и набором флагов. Флаги предназначены для управления автоматом:
· Флажок а - управляет чтением следующего входного символа
· Флажок s - управляет занесением точки возврата в стек
· Флажок r - обеспечивает переключение автомата в состояние, номер которого снимается с верхушки стека
· Флажок е - запрещает останов по ошибке в случае, когда состояние соответствует нетерминалу из левой части и есть еще хотя бы одно правило для такого нетерминала.
С учетом этого каждая клетка управляющей таблицы содержит поля: Множество выбора состояния, флажки, адрес перехода.
ü Построить конечный автомат со стековой памятью и одним состоянием, управляемый входным символом и символом, снятым с верхушки стека (шаблон …SyntAsOneSA…), разобраться в структуре управляющей таблицы автомата, уяснить способы формирования и использования клеток таблицы;
Часть управляющей таблицы автомата с одним состоянием
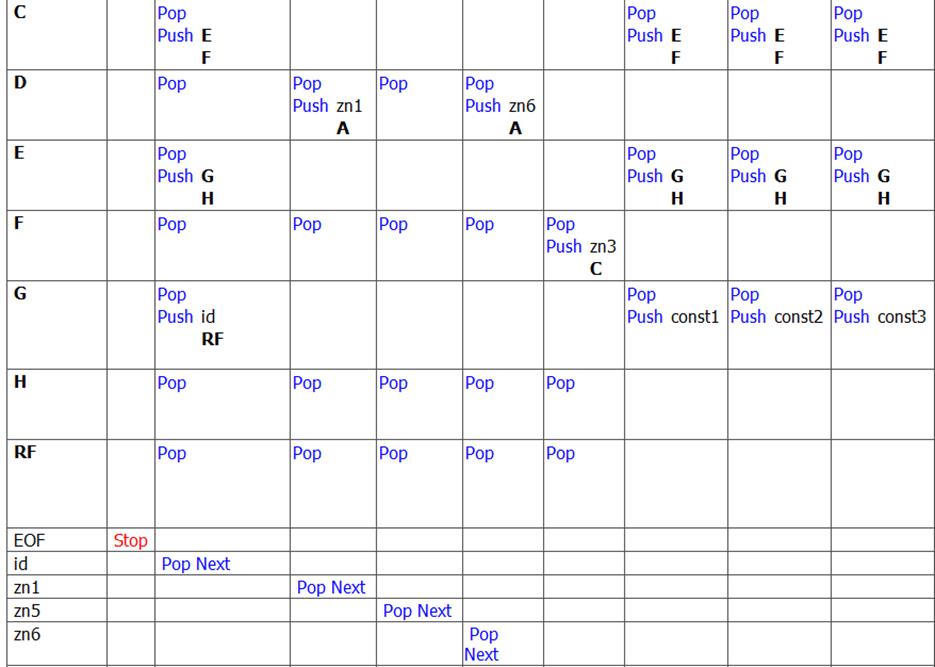
В клетки управляющей таблицы автомата с одним состоянием заносятся комбинации действий:
Pop - Снять верхний символ со стека
Push - Поместить в стек цепочку символов, находящуюся в клетке справа от слова Push (верхний символ цепочки становится верхним символом стека)
Next - Прочитать следующий терминал со входа
Stop - Останов по окончанию восстановления дерева разбора правильного предложения
Пустая клетка - Останов по ошибке
Расмотрим основные элементы языка из шаблона:
//Part_6: синтаксический акцептор/анализатор
class parser{
lexAnalyzer la; //экземпляр лексического анализатора
lexem currentLexem; //текущая лексема
int cCnt=0; //счетчик количества циклов работы автомата
/*^if(grammar.pertainToLL1)^*/
Stack stk=new Stack(); //стек символов
Integer stkItem; //элемент стека символов
int curWordIndex; //индекс текущего терминала/*^if(grammar.symbolSet.hasWords)^*/
String[] words={/*^forEach(currentWord in grammar.symbolSet)^*/
"/*^=currentWord.text^*/"/*^if(currentWord.hasNextWord)^*/,/*^endIf^*/
/*^endFor^*/};/*^endIf^*/
//Part_6_0 данные и методы из правил
/*^=parser.data^*/
//end of Part_6_0
//Part_6_1: конструктор СА
public parser(String s){
la=new lexAnalyzer(new textReader(s)); //создание экземпляра лексического анализатора
stk.push(new Integer(/*^=EndOfFile.indexForGrammar^*/));// индекс символа EOF в стек
stk.push(new Integer(-1));// индекс начального нетерминала в стек
}
//Part_6_2: вызов лексического анализатора и преобразование лексемы в код терминального символа
private int getWordIndex(){ //эта функция вызывает лексический анализатор, получает лексему и пытается найти обнаруженное слово
// в массиве строк литер words. При удаче - возвращает индекс этой строки, иначе - индекс группы слов, сформированный лексическим анализатором.
int i;String w;
currentLexem=la.getLexem();/*^if(grammar.symbolSet.hasWords)^*/
w=new String(currentLexem.textOfWord);
for(i=0;i<words.length;i++) //просмотрим слова, определенные в грамматике как строки литер
if(words[i].compareToIgnoreCase(w)==0) //если входное слово найдено в массиве строк литер
return i+/*^=symbolSet.firstWord.index^*/; //вычислим и вернем его индекс/*^endIf^*/
return currentLexem.groupIndex; //вернем индекс группы слов
}
public int getStatistic(int i){
return cCnt;
}
//Part_6_3: собственно восстановление дерева грамматического разбора
public boolean parse(){
curWordIndex=getWordIndex(); //прочитаем первый терминал из входного потока
while(stk.size()>0){ //и до тех пор, пока стек не пуст, выполняем основной цикл
stkItem=(Integer)stk.pop(); //снимаем символ с верхушки стека
//внешний переключатель обрабатывает символы из стека (в том числе - индексы действий и терминалы)
//каждый внутренний переключатель содержит индексы только тех терминалов, которые входят в множество выбора символа внешнего переключателя
//в комментариях указано, что, откуда и как обрабатывается
switch (stkItem.intValue()){
case /*^=EndOfFile.indexForGrammar^*/:// EOF из стека
return ((stk.size()==0)&&(curWordIndex==/*^=EndOfFile.indexForGrammar^*/));/*^forEach(currentNonTerminal in grammar.symbolSet)^*/
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.