Разработанная в первом пункте задания система регулярных выражений определяет лексику разрабатываемого учебного языка. На её основе строится лексический акцептор. На данном этапе работы необходимо выполнить построение лексического анализатора, который не просто проверяет лексическую правильность текста программы, а также выполняет дополнительные действия, связанные с поиском/пополнением таблиц идентификаторов и констант.
Вот как выглядит расширение лексического акцептора, дополненного необходимыми действиями:
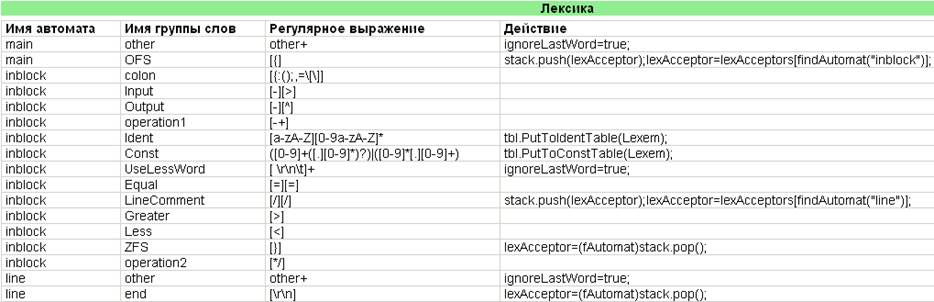
Рис. 4 Представление системы регулярных выражений, дополненной действиями
Кроме рассмотренных ранее действий в системе регулярных выражений, определяющих лексику учебного языка, появились новые действия. Кратко опишем каждый из них:
· Метод PutToIdentTable (Lexem); Данный метод выполняется тогда, когда программная модель конечного автомата переходит в финальное состояние акцепта любого слова группы Ident (идентификатор). Перед тем, как занести вновь обнаруженный идентификатор в соответствующую таблицу, в данном методе должна быть выполнена проверка того, не является ли вновь обнаруженный идентификатор предопределённым оператором языка (if, else, mem, calc, link). Если он является таковым, то заносить его в таблицу идентификаторов не нужно. В противном случае в данной таблице должен быть выполнен поиск текущего идентификатора. Если поиск завершился успешно, то необходимо вернуть индекс строки, в которой хранится вся необходимая информация по данному идентификатору. В противном случае, он должен быть занесён в таблицу;
· Метод PutToConstTable (Lexem); Данный метод полностью аналогичен описанному выше за исключением того, что в работа происходит с таблицей констант.
Детали реализации:
В данном варианте в качестве таблицы используется хэш-таблица, которая обеспечивает линейную зависимость затрат времени на поиск от общей длины программы в словах и на пополнение – от количества различных слов.
Предусмотрены две различные таблицы – таблица идентификаторов и констант. Структура записи хэш-таблицы класса java.util.Hashtableимеет следующий вид:
Запись - <key><value>, т.е. <ключ> и <значение>.
В качестве ключа в таблице хранится текст слова (поле lexem.textOfWord). Значением является ссылка на стек, куда могут помещаться атрибуты переменной. Причём элементом стека может являться ссылка на связный список, где будут храниться атрибуты объекта в текущей области видимости. Если встретится объявление переменной другого типа, имеющей такой же идентификатор, то в этом случае прежняя переменная перестанет быть видна, а на верхушке стека окажется ссылка на список атрибутов нового объекта другого типа (класса).
Ниже приведена разработанная формальная грамматика класса LL(1), определяющая синтаксис заданного языка:
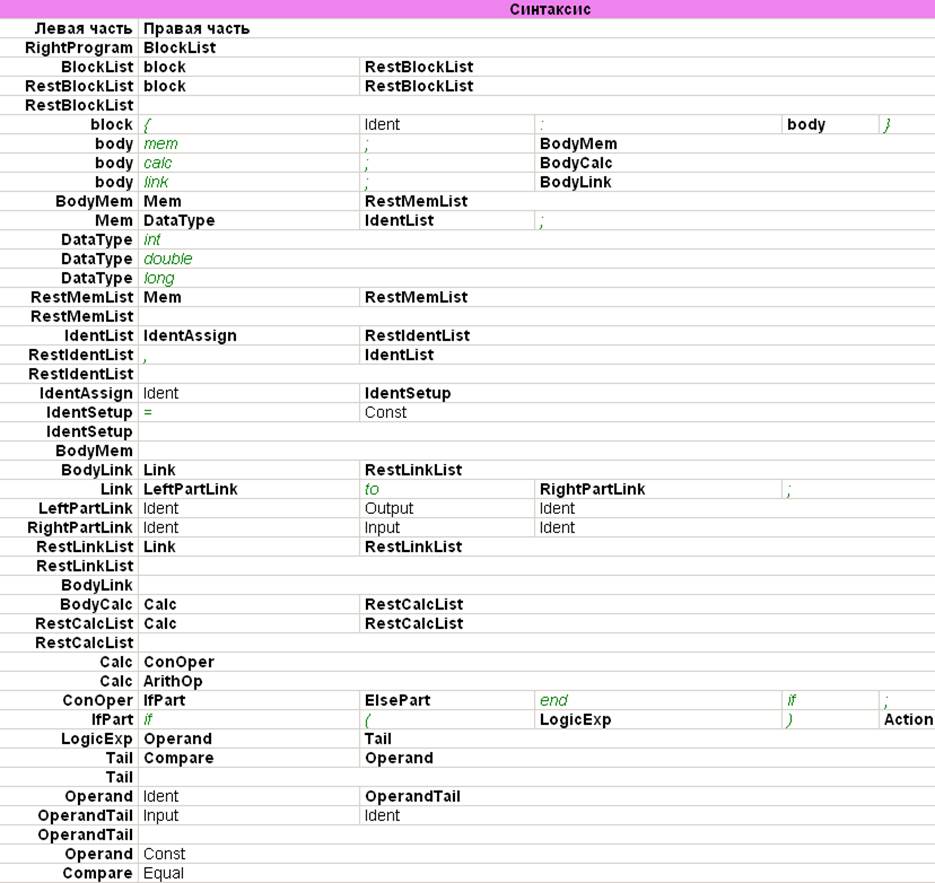

Рис. 5 Представление формальной грамматики класса LL(1) в пакете WebTransLab
Используя пакет WebTransLab, построим автоматную реализацию нисходящего синтаксического акцептора. Рассмотрим работу автомата на тестовом примере (Рис. 7.).
Допустим, при написании программы была совершена ошибка следующего вида:
В вычислительном блоке с3 во вложенном блоке if-else пропущена открывающая скобка перед проверкой условия, т.е. if (c3->in2==1), а с ошибкой текст описания блока выглядит следующим образом: if c3->in2==1). Посмотрим на работу синтаксического акцептора:
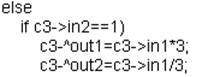

Рис. 6 Работа синтаксического акцептора в случае синтаксической ошибки
Таким образом, синтаксический анализатор в отличие от лексического анализатора признаёт программу правильной только в том случае, если она является правильной и лексически, и синтаксически, т.е. правильно описаны грамматические конструкции заданного языка. В предыдущем примере текст программы правилен лексически и неправилен синтаксически, потому что допущена именно синтаксическая ошибка.
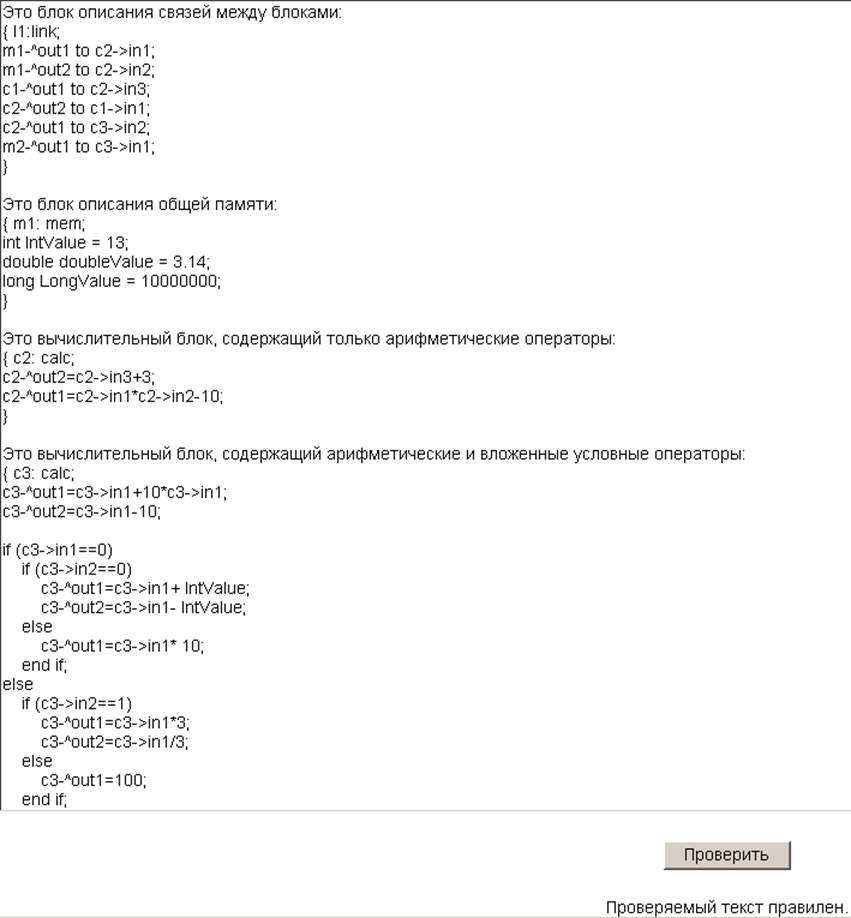
Рис. 7 Проверка работоспособности автоматной реализации нисходящего синтаксического акцептора
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.