правила грамматики , оставшиеся после удаления недостижимых и/или бесплодных символов;
отношение предшествования и свойства символов грамматики;
отношение последования и свойства символов грамматики;
множества выбора правил грамматики:
управляющую таблицу нисходящего синтаксического акцептора с одним состоянием (если грамматика относится к классу LL(1));
управляющую таблицу нисходящего синтаксического акцептора с несколькими состояниями (если грамматика относится к классу LL(1));
таблицу канонических конфигураций правил грамматики (имеющих в точности один символ ожидаемого правого контекста);
таблицу расширенных конфигураций правил грамматики, построенную путем объединения неконфликтующих канонических конфигураций одного состояния;
управляющую таблицу восходящего синтаксического акцептора.
Очистить - этот пункт предназначен для удаления всех регулярных выражений и правил грамматики из таблиц нижнего фрейма.
Настроить - предназначен для модификации и сохранения некоторых параметров визуализации данных основного окна, а именно - семейства шрифтов, размеры шрифтов, жирность, курсив, цвета текста и фона элементов основного окна.
Сохранить как - щелчок по этому пункту (или нажатие клавиши Enter в текстовом боксе справа от этого пункта меню) приводит к сохранению текущей совокупности лексических и синтаксичсеких правил в файле, имя которого содержится в текстовом боксе. Если имя файла, введенное пользователем, не содержит расширения, то к имени добавляется ".xml".
Рестарт - щелчок по этому пункту возвращает пользователя в начальное окно ВебТрансЛаба для повторной регистрации.
Под меню находятся два зеленых блока и два сиреневых блока. Каждый можно независимо открыть/закрыть щелчком мыши. Первый и третий блоки (данные лексического/синтаксического анализатора) предназначены для описания на Java необходимых пользователю для работы классов, структур, функций и т.д. Во втором и четвертом записываются правила лексики и синтаксиса соответственно (пример лексических правил на рис. 3).

Рис 3. Пример таблицы лексических правил.
Создание нового правила происходит путем клика мышкой на пустую строку в таблице и заполнения появившейся формы (рис. 4).
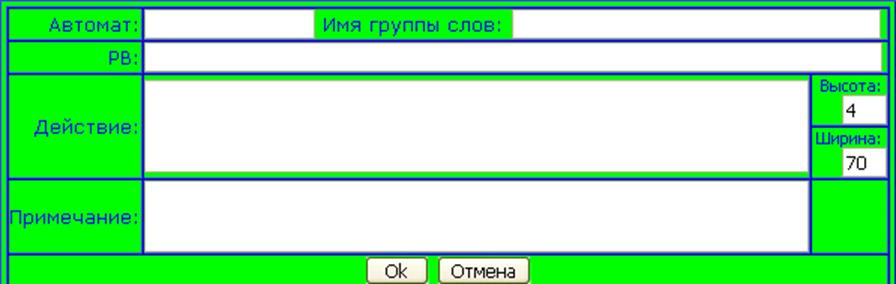
Рис 4. Создание нового правила/редактирование старого.
Автомат: имя автомата, к которому будет относиться правило. Писать можно любые имена за тем исключением, что обязательно должно быть хотя бы одно правило для main.
Имя группы слов: может быть использовано в качестве терминального символа при определении лексики.
РВ: описание построения правильного слова данной группы.
Действие: операторы на языке Java, которые будут выполняться в момент обнаружения слова из данной группы. Не обязательно к заполнению.
Примечание: комментарий к правилу, если он требуется. Для построения автомата не требуется.
Поля ширина и высота сохраняют свои параметры только до закрытия браузера.
Возможно перетаскивание строк таблицы методом D&D. А если кликнуть правой кнопкой по имени автомата, то вызывается контекстное меню (рис. 5).
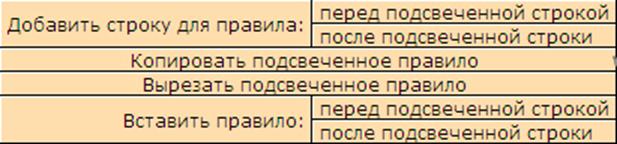
Рис 5. Контекстное меню.
Для сортировки таблицы правил нужно кликнуть по строке с заголовками колонок.
Рассмотрим структуру xml файла в котором сохраняются правила. Содержательной частью файла является только тело тега с именем <transLab>. Вебтранслаб игнорирует все то, что предшествует открывающему тегу <transLab> и следует после закрывающего тега </transLab>. Игнорируется также все то, что содержится в теле тега <transLab>, но находится вне тегов <lexic>…</lexic> и <syntax>…</syntax>.
<?xml version="1.0" encoding="windows-1251"?>
<transLab>
<lexic>
<automat name='main'>
<rule groupWordsName='id'>
<expression>[a-zA-Zа-яА-Я]+[0-9]</expression>
<action>ti.put(0,Lexem.groupIndex,Lexem.textOfWord);</action>
</rule>
<rule groupWordsName='delim'>
<expression>[ \t\n\r]</expression>
<action>ignoreLastWord=true;</action>
</rule>
<rule groupWordsName='const'>
<expression>[0-9]+([.][0-9]+)?</expression>
<action>ti.put(2,Lexem.groupIndex,Lexem.textOfWord);</action>
</rule>
<rule groupWordsName='bool'>
<expression>[01]+[b]</expression>
<action>ti.put(3,Lexem.groupIndex,Lexem.textOfWord);</action>
</rule>
<rule groupWordsName='symbol'>
<expression>(['][\\]?[]['])|([0-9A-F][0-9A-F]"h")</expression>
<action>ti.put(4,Lexem.groupIndex,Lexem.textOfWord);</action>
</rule>
</automat>
</lexic>
</transLab>
Тег <lexic> может содержать произвольное количество тегов <automat>. Тело тега <automat> должно содержать единственный тег <name>, определяющий имя автомата, и произвольное количество тегов <rule>. Каждый тег <rule> (в разделе лексики) должен содержать теги <groupWordsName> и <expression> и может содержать теги <action> и <comment> в произвольном сочетании. Как уже говорилось, примечания, составляющие тело тега <comment>, никак не используются построителем, поэтому далее этот тег не рассматривается.
Тег <groupWordsName> предназначен для задания имени той группе слов, которая определяется регулярным выражением, содержащимся в теге <expression>. Тег <action> - это соответствующие действия.
Эта лабораторная работа позволила познакомиться с пакетом, с которым предстоит работать далее, а именно – изучить пользовательский интерфейс, назначение пунктов меню, работу с таблицами правил, пользование шаблонами и т.д. Также была создана простейшая система своих правил лексики, которая является маленьким зернышком курсовой работы.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.