Показать - Щелчок по этому пункту приводит к появлению списка свойств, отношений и множеств, которые могут быть показаны для последней обработанной построителем совокупности синтаксических правил - формальной грамматики. Выбор любой строки из этого списка приводит к открытию нового окна браузера, содержащего соответствующую информацию.
Очистить - этот пункт предназначен для удаления всех регулярных выражений и правил грамматики из блоков лексики и синтаксиса.
Настроить - предназначен для модификации и сохранения некоторых параметров визуализации данных основного окна, а именно - семейства шрифтов, размеры шрифтов, жирность, курсив, цвета текста и фона элементов основного окна. Сохранение этих параметров производится в cookie, поэтому настройка будет иметь эффект только в том случае, если клиентский браузер поддерживает cookie и эта поддержка не отключена. Если же cookie отключены, то будут использоваться заданные по умолчанию значения этих параметров. Результат сохранения новых настроек отображается немедленно в нижнем фрейме основного окна. Вид верхнего фрейма будет соответствовать новым настройкам только при следующем открытии основного окна.
Помочь - для открытия этого окна краткой справочной информации по «ВебТрансЛаб».
Рестарт - щелчок по этому пункту возвращает пользователя в начальное окно «ВебТрансЛаб» для повторной регистрации.
Ввод/редактирование лексических и синтаксических правил
Под основным меню находится блок данных лексического анализатора(скрыт на рис.2.), в этом блоке на языке JAVA, можно описать какими дополнительными данными будет обладать лексический анализатор.
Ниже расположена таблица лексических правил, в этой таблице можно описать лексику языка.
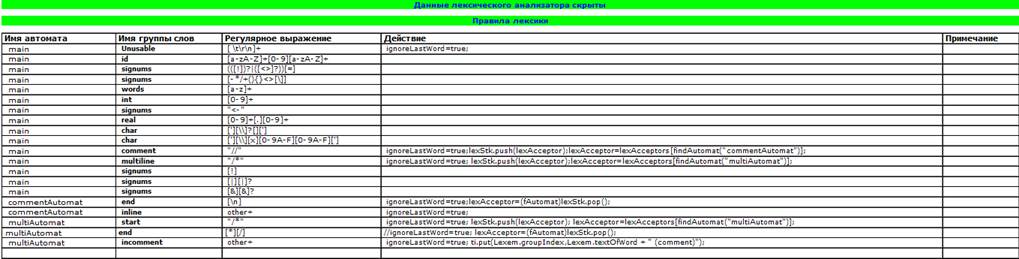
Рис. 3.- Таблица лексических правил
Самым простым способом добавить новое правило, является клик по нижней пустой строке таблица, приведем пример добавления нового лексического правила.
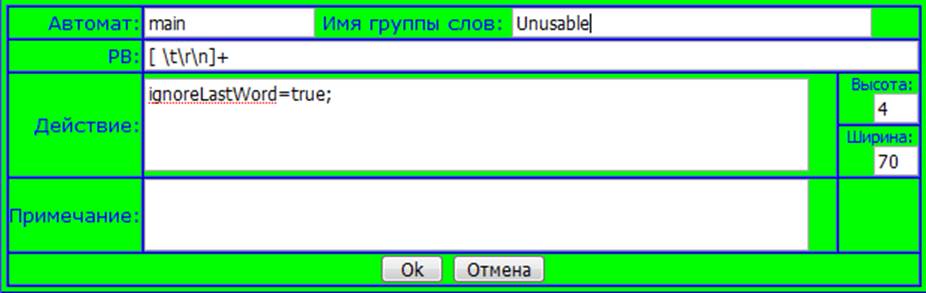
Рис. 4.- Добавление нового лексического правила.
На рис. 4. Показан вид формы с заполненными полями. Первое поле носит имя Автомат, в него вводится имя автомата, к которому относится описываемое правило, дело в том, что ВебТрансЛаб поддерживает мультиавтоматный режим работы лексического анализатора. Единственное ограничение заключается в том, что всегда должен присутствовать автомат с именем main.
Следующее поле называется Имя группы слов, и оно указывает в каком состоянии, должен остановиться автомат, при распознании слова, удовлетворяющего регулярному выражению этого правила.
Поле РВ служит для ввода регулярного выражения определяемого задаваемым правилом
В поле Действия модно на языке JAVA, описать действия, которые должен выполнить автомат при распознании слова удовлетворяющего задаваемому правилу.
В поле Примечание вводится комментарий к правилу, это поле не как не влияет на работу лексического анализатора, равно как и поля Высота и Ширина, которые позволяют изменить размер поля Действия.
Редактирование правил осуществляется кликом левой клавиши мыши.
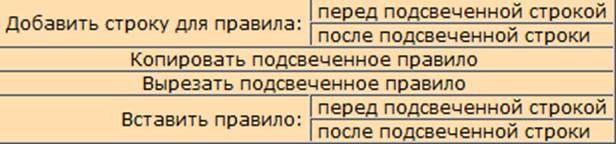
Рис. 5.- Контекстное меню таблицы лексических правил.
Кликнув по любому правилу правой кнопкой мыши, можно вызвать контекстное меню, позволяющее добавить новую пустую строку для лексического правила до или после выделенного правила, скопировать или вырезать выделенное правило, и наконец, вставить скопированное или вырезанное правило.
Клик по заголовку столбца таблицы Имя группы слов позволяет отсортировать таблицу лексических правил по алфавиту.
Ниже располагаются блок данных синтаксического анализатора и его таблица правил, но их описывать мы не будем.
XML файл
Рассмотрим структуру текстового XML-файла содержащего систему лексических правил. Для чего сохраним нашу таблицу лексических правил в файл и откроем его.
<?xml version="1.0" encoding="windows-1251"?>
<transLab>
<lexic>
<automat name='main'>
<rule groupWordsName='Unusable'>
<expression>[ \t\r\n]+</expression>
<action>ignoreLastWord=true;</action>
</rule>
<rule groupWordsName='id'>
<expression>[a-zA-Z]+[0-9][a-zA-Z]+</expression>
</rule>
<rule groupWordsName='signums'>
<expression>(([!])?|([<>]?))[=]</expression>
</rule>
<rule groupWordsName='signums'>
<expression>[-*/+(){}<>[\]]</expression>
</rule>
<rule groupWordsName='words'>
<expression>[a-z]+</expression>
</rule>
Первой строкой в файле идет заголовок XML-документа, в котором указана кодировка. Затем идет тег, указывающий на блок тегов для ВебТрансЛаба, следом тег, указывающий на начало таблицы лексических правил. Затем идет тег описания автомата с указанием имени описываемого автомата. Внутри автомата находятся теги описания правил, в теге описания правил указывается имя описываемой группы слов. Внутри находятся теги, хранящие РВ, Коментарий и Действия, поля Высота и Ширина в файле не сохраняются. После чего идет закрытие тега описания правила. Затем описание прочих правил автомата. После - закрытие тега автомата, описание остальных автоматов и закрытие тега таблицы лексического анализатора. Закрытие тега данных ВебТрансЛаба.
4. Выводы
В этой лабораторной работе я освоил основные навыки работы с учебным пакетом программ автоматизации разработки трансляторов ВебТрансЛаб, изучил и освоил пользовательский интерфейс пакета и формат файлов с создаваемыми правилами. Изучил метаязык регулярных выражений и создал свою начальную систему лексических правил, которую буду использовать при выполнении курсовой работы.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.