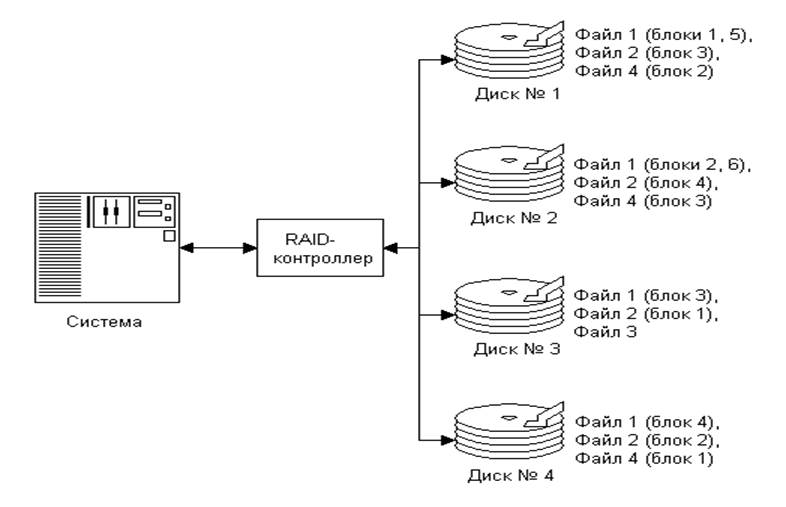
На рисунке представлена блок-схема RAID-конфигурации с чередованием. Один контроллер (аппаратный или программный) разбивает файлы на блоки или байты и распределяет их по нескольким жестким дискам. Размер блока определяет, на сколько "частей" разбиваются файлы. В приведенном примере первый блок файла 1 посылается на диск №1, затем второй блок на диск №2 и т.д. Когда все четыре диска имеют по одному блоку файла 1, пятый блок направляется на диск №1 и процесс продолжается до окончания файла. Отметим, что файл 3 находится только на одном диске; это означает, что размер файла меньше размера блока.
Само по себе чередование не вносит избыточности и не обеспечивает защиты данных. Иногда вместо термина чередование используется термин перекрытие (spanning).
Зеркалирование используется в некоторых уровнях RAID для защиты данных в RAID-массиве. Несмотря на то, что зеркалирование имеет определенные достоинства и хорошо подходит для некоторых реализаций, у него имеются и недостатки. Главный недостаток - высокая стоимость, так как 50% накопителей в массиве зарезервированы только для дублирования данных; кроме того, зеркалирование не повышает производительность, как это делает чередование. Поэтому как альтернатива зеркалированию разработан другой способ защиты данных, который опирается на использовании информации о паритете. Эта информация представляет собой избыточную информацию, которая вычисляется из фактических значений данных.
Используемый в RAID-массивах паритет очень похож на паритет для памяти RAM. Принцип паритета довольно простой: нужно взять "N" фрагментов данных и по ним вычислить дополнительный фрагмент. Затем нужно взять "N+1" фрагментов данных и сохранить их в "N+1" накопителях. Если потерян любой один из "N+1" фрагментов данных, его можно восстановить из оставшихся "N" фрагментов независимо от того, какой фрагмент потерян. Защита по паритету применяется в RAID с чередованием и "N" фрагментов данных обычно являются блоками или байтами, распределяемыми по накопителям массива. Информацию о паритете можно хранить в отдельном выделенном накопителе или смешать с данными во всех накопителях массива.
Паритет обычно вычисляется с помощью логической операции исключающего ИЛИ (exclusive OR или XOR). Напомним, что оператор XOR дает истинное значение (true), если только один из операндов имеет истинное значение.
Операция "XOR" интересна тем, что при выполнении два раза подряд она "отменяет саму себя". Если вычислить "A XOR B", а затем взять результат и выполнить с ним еще одну операцию "XOR B", то в результате получится первоначальное значение A. Другими словами, "A XOR B XOR B = A". Именно это свойство и используется при вычислении паритета в RAID-системе. Если имеются четыре элемента данных D1, D2, D3 и D4, можно вычислить данные паритета "DP" как "D1 XOR D2 XOR D3 XOR D4". После этого, зная любые три из четырех элементов D1, D2, D3, D4, а также DP, можно выполнить для этих элементов операцию XOR и получить отсутствующий элемент, соответствующий вышедшему из строя накопителю.
Операцию "XOR" можно выполнять над любым числом битов. Отметим, что эта операция довольно проста, а это важно, потому что ее необходимо выполнять для каждого бита, хранящегося в RAID-массиве с паритетом.
По сравнению с зеркалированием паритет (используемый совместно с чередованием) имеет достоинства и недостатки. Наиболее очевидное его преимущество состоит в том, что паритет защищает данные от отказа любого одного накопителя в массиве, не требуя 50% потерь при зеркалировании. Потери при паритете равны (100/N)%, где N - общее число накопителей в массиве. Чередование с паритетом обеспечивает также выигрыш в производительности. Основные недостатки чередования с паритетом относятся к сложности: все байты паритета необходимо вычислять (миллионы байтов в секунду!), а для этого требуется вычислительная мощность. Следовательно, для достижения высокой производительности нужен аппаратный контроллер, поскольку при реализации программного RAID-массива с чередованием и паритетом системный процессор просто "захлебнется" в вычислениях. Кроме того, по сравнению с зеркалированием усложняется восстановление при отказе накопителя.
Первоначально RAID-системы разрабатывались для защиты данных путем повышения отказоустойчивости. Несмотря на то, что сейчас вопросы надежности, доступности и отказоустойчивости продолжают играть важную роль, все большее внимание уделяется производительности. Встречаются реализации RAID-массивов, направленные только на повышение производительности без всяких средств избыточности и защиты данных. Даже при использовании избыточности желательно "выжать" из RAID-массива максимальную производительность.
Ключевым моментом в повышении производительности RAID-систем является параллелизм. Возможность обращения к нескольким дискам одновременно позволяет записывать и считывать данные в RAID-массиве быстрее, чем в одном накопителе.
Жесткие диски выполняют две разные функции: запись данных и считывание данных. Электронные и механические процессы, происходящие при выполнении этих операций, во многом аналогичны. Однако даже в одиночном накопителе производительности считывания и записи отличаются хотя и небольшими, но важными моментами. В RAID-массивах различия производительностей считывания и записи проявляются сильнее из-за различий в способах организации дисков в массивы и разных способах хранения данных.
Основное различие между считыванием и записью в RAID-системе заключается в следующем: при записи данных в среде с избыточностью необходимо обращаться к каждому месту, где сохраняются данные; при считывании данных нужно считать только минимальный объем данных, необходимый для получения фактических данных - при считывании к избыточной информации обращаться не нужно. Рассмотрим, как в этом отношении отличаются различные способы хранения данных:
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.