











Федеральное министерство по образованию.
Сибирский государственный индустриальный университет
Кафедра Информационных технологий.
Пояснительная записка к курсовой работе по теме:
“Система распределения неинтерактивных задач по ресурсам.
Анализ эффективности различных алгоритмов распределения ”
Выполнил: ст.гр. ИСП-07
Доронкин А.В.
Проверил: ст. преподаватель
Климов В. Ю.
Новокузнецк 2009г.
1. Введение
2. Постановка задачи
3. Особенности реализации
4. Используемые алгоритмы и структуры данных
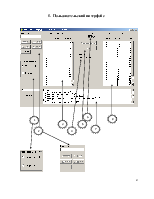
5. Пользовательский интерфейс
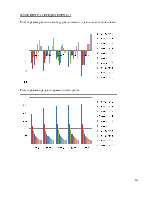
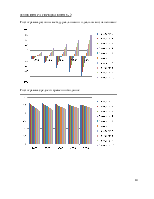
6. Анализ результатов моделирования
7. Вывод
1. Введение
В языках программирования существует другой, отличный от статического выделения памяти, способ, который называется динамическим. В нем память под величины отводится во время выполнения программы. Такие величины называются динамическими. Раздел оперативной памяти, распределяемый статически, называется статической памятью; динамически распределяемый раздел памяти называется динамической памятью (динамически распределяемой памятью).
Использование динамических величин предоставляет программисту ряд дополнительных возможностей. Если потребность в каких-то данных отпала до окончания программы, то занятую ими память можно освободить для другой информации. Использование динамической памяти позволяет создавать структуры данных переменного размера.
Работа с динамическими величинами связана с использованием еще одного типа данных — ссылочного типа. Величины, имеющие ссылочный тип, называют указателями.
Указатель содержит адрес поля в динамической памяти, хранящего величину определенного типа.
Адрес величины — это номер первого байта поля памяти, в котором располагается величина. Размер поля однозначно определяется типом.
Следует отчетливо понимать, что работа с динамическими данными незначительно замедляет выполнение программы, поскольку доступ к величине происходит в два шага: сначала ищется указатель, затем по нему — величина. Как это часто бывает, действует "закон сохранения неприятностей": выигрыш в памяти компенсируется проигрышем во времени.
2. Постановка задачи
Программа должна просто и доступно имитировать распределение процессов по приоритетам, поступление процессов на обработку в условный «процессор». При остановке программы – анализировать произошедшее распределение.
Пользователь, использующий программу, должен иметь возможность добавлять процессы, выставляя им приоритет, удалять процессы, полностью очищать рабочее поле. Также должна быть возможность сохранения и загрузки готовых списков процессов с различными приоритетами.
Визуально программа должна отображать информацию об обрабатываемом процессе, счетчик процессорного времени, списки процессов, а также место, на которое выводятся результаты анализа работы программы.
Анализ должен включать в себя расчет близкого к идеальному выделенного процессором времени на обработку одного процесса с i-ым приоритетом, расчет среднего реального времени обработки, опережение-отставание времени обработки от приближенного к идеальному времени.
Интерфейс должен быть максимально прост и понятен для пользователя.
Систем распределения должно быть как минимум две. Каждая из систем должна обладать каким-либо уникальным свойством, по которому ее можно отличить от другой.
Система распределения №1:
Основным критерием для выбора на обработку является идеально рассчитанное время, которое должно достаться на обработку каждого процесса с соблюдением приоритетов (чем больше приоритет, тем больше времени на обработку должно достаться и тем меньше процесс должен простаивать). Идеальное время для каждого приоритета рассчитывается по формуле:
I = p * (t / Cp)
Где:
I – идеальное время, p – приоритет процесса, t – общее время, Cp – сумма всех приоритетов процессов.
Соответственно если время обработки процесса отстает от идеально рассчитанного, то процесс поступает на обработку. Эта система распределения наиболее правильно распределяет «процессорное» время для каждого приоритета. Правда при этом существует огромнейшая дискриминация для малых приоритетов.
Система распределения №2:
Существенное отличие от прошлой системы распределения заключается в том, что основным критерием для выбора процесса является максимальное время простоя, которое для каждого приоритета свое. Максимальное время простоя рассчитывается по формуле:
M = 12 – p
Где:
M – максимальное время простоя, p – приоритет процесса.
Соответственно если время простоя процесса превышает установленный для него максимум, то процесс немедленно поступает на обработку. Эта система распределения понижает дискриминацию процессов с меньшими приоритетами.
3. Особенности реализации
Для реализации поставленных задач решено было использовать среду программирования Delphi.
Delphi позволяет использовать такие компоненты класса TObject, как TListBox, TMemo и т.д. Так же язык программирования Delphi является для меня наиболее удобным.
Часть программы базируется на использовании компонента класса TObject TList. TList служит для создания списков объектов и работы с ним.
Также были дополнительно написаны такие классы как: TProcess и TManager. Класс TProcess является классом процесса и нужен для хранения основной и переменной информации о процессе. Класс TManager позволяет управлять списками процессов и является фактически основным костяком программы.
1. Структура класса процесса (TProcess):
Prior:integer; – Приоритет процесса
ProcTime: integer; - Общее значение времени, выделенного на обработку процесса
StayTime: integer; - Значение времени простоя процесса
Check: Boolean; - Значение, показывающее получил ли процесс одну условную единицу времени на обработку
2. Структура класса менеджера (TManager):
index: integer; – Индекс процесса, находящегося на обработке
IdealProcTime: double; – Близкое к идеальному выделенное процессором время на обработку одного процесса с наименьшим приоритетом
CommonPrior: integer; – Сумма всех приоритетов в момент старта распределения
CommonTime: integer; – Общее время, выделенное процессором на обработку всех процессов
MasStay: array [1..10] of integer; - Массив времени простоя для каждого приоритета
MasCount: array [1..10] of integer; - Массив кол-ва процессов для каждого приоритета
PriorProc:TProcess; – Процесс, находящийся на обработке
ProcInWork:Boolean; – Метка, показывающая находится ли любой процесс на обработке в данный момент времени
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.