Уже при проектных нормах 0,25…0,18 мкм достижима тактовая частота 1…2 ГГц, и размере кристалла 1…2 см время распространения сигнала от одного края кристалла до другого превышает длятельность такта. Поэтому гигагерцовые БИС уже не могут быть синхронными (с единым тактированием). В МП Alpha до 40% мощности расходуется на распределение тактового сигнала. Для дальнейшего повышения тактовой частоты надо переходить к асинхронным структурам на кристалле.
Уменьшение длины внутрикристальных соединений достигается увеличением количества слоев металлизации (при этом экспоненциально растет процент брака).
Увеличение пропускной способности подсистемы памяти достигается сбалансированным выбором многоуровневой сруктуры КЭШ-памятей и пропускной способности шин между этими уровнями. Следует помнить, что эффективность использования (быстрой) кэш-памяти основана на принципе «один раз медленно из основной памяти в кэш, а затем много раз быстро из кэша в процессор».
В зависимости от специфики конкретной программы эффективность кэша может варьировать от очень высокой - 5…10 кратное ускорение (для задач с малым объемом кода и данных, которые целиком помещаются в кэш и с высокой степенью их повтороного использования – типичный пример –итеративная вычислительная задача) до отрицательной, когда значительная часть данных (чаще) или кода (реже) используется лишь однократно.
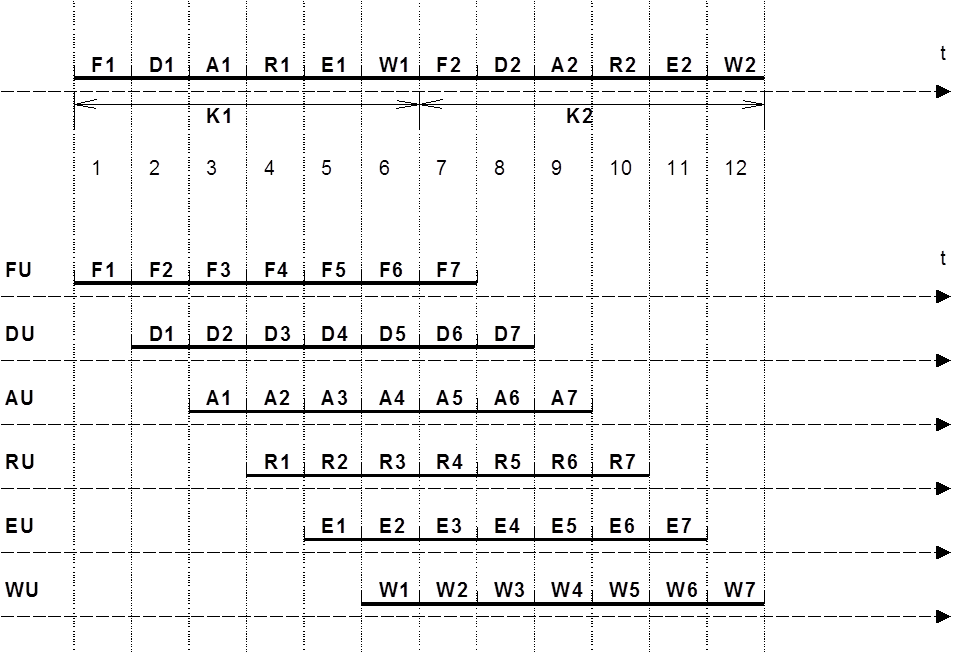
Структура выполнения машинной команды в пространстве и во времени.
Структура команды во времени (этапы выполнения команды)
1) Выборка команды (F - fetch)
2) Дешифрация (D - decode)
3) Вычисление (исполнительного адреса и трансляция) адреса источника (ов) (A
–addr.clc)
4) Выборка операнда (ов) (R – read)
5) Исполнение операции (E - execute)
6) Запись результата (W – write, retire)
Приведенное разбиение команды на этапы может быть сделано различными способами, приведенный отнюдь не является ни единственным, ни наилучшим.
Все структурные способы повышения производительности сводятся к организации параллельного выполнения, этапов отдельной команды, соседних (во времени) команд или отдельных частей программы.
Реализация описанных далее способов стала возможна по мере роста степени интеграции, когда на кристалле стало возможным уместить все необходимые блоки. Количество исполнительных блоков, их разрядность и набор выполняемых операций растут с ростом степени интеграции.
Конвейеризация. Это введение в процессор нескольких исполнительных блоков (вместо ранее имевшегося одного). Если каждый этап команды выполняется отдельным блоком и на выполнение каждого этапа расходуется одинаковое время (один такт), то на выходе процессора каждый такт, начиная с 7-го появляется результат очередной команды.
 Фактически количество этапов, на
которые конструкторы разбивают выполнение процессорной команды может быть различным (в разных моделях процессоров
х86 колеблется от 2 ‑ i8088 до 20 ‑ Pentium IV).
Фактически количество этапов, на
которые конструкторы разбивают выполнение процессорной команды может быть различным (в разных моделях процессоров
х86 колеблется от 2 ‑ i8088 до 20 ‑ Pentium IV).
Суперскалярная архитектура процессора. Состоит в том, что в процессоре делается более, чем один конвейер. Очередная команда в такой структуре поступает на первый освободившийся конвейер (если конвейеры одинаковы). В реализациях структура, как правило, более сложная (см. напр. Pentium Pro), когда невозможно выделить отдельные “нити” нескольких конвейеров, но тем не менее, для каждой стадии выполнения команды существует более одного исполнительного блока.
Идеальная конвейеризация, изображенная на рисунке, а также эффективная работа нескольких конвейеров в суперскалярном процессоре возможны, лишь, если:
1) Все команды имеют одинаковую структуру в пространстве и во времени. (Для CISC архитектуры характерно большое разнообразие форматов команды как в пространстве (для от 1 до 16 байтов), так и во времени (для i8086 этап исполнения команды длился от от 3 до >20 тактов). Вследствие этого реальный конвейер работает менее эффективно.)
2) последующие команды «не зависят» от предыдущих.
«Зависимости» одних команд от других (dependencies) состоят в том, что данная команда не может продолжить (завершить) свое выполнение, пока не завершилось выполнение некоторых предшествующих команд. Зависимости проявляются в нескольких аспектах:
1) “Истинные» зависимости (True Dependenciesили Data Dependencies) – команде требуются результаты одной из предшествующих команд (которые еще не готовы)
2) «Ложные» зависимости (False Dependencies) – команда должна использовать ресурсы, которые заняты предшествующей командой (под ресурсами здесь имеются в виду элементы схемотехники процессора – шины, регистры, декодеры, блоки АЛУ, если бы были свободные, данная команда могла бы завершиться).
3) Управляющие зависимости (Control Dependencies) – данная команда начала выполняться, но должна быть прервана (с аннулированием всех промежуточных результатов), так как произошло (условное) ветвление на другую ветвь.
Для уменьшения влияния перечисленных факторов на работу параллельных структур используются приемы, которые можно разбить на три вида:
1) Схемотехнические – подходящий сбалансированый выбор набора и производительности блоков, которые должны работать параллельно,
2) Унификация структуры команд с целью обеспечить их лучшую конвейеризуемость.
3) Оптимизация программного (исполняемого) кода (ручная или автоматическая) с целью уменьшения зависимостей между близко расположенными командами.
В 80-е годы сложилась парадигма проектирования структур процессоров, которая получила название RISC-архитектуры (RISC – Reduced Instruction Set Computers – компьютер с сокращенным набором команд – в противоположность CISC – Compex (или Complicated) …). Вот основные положения этого направления:
A) Система команд построена так, что структура всех команд унифицирована: все команды имеют одинаковую длину и выполняются за одинаковое количество тактов. Для этого отказываются от использования сложных способов адресации.
B) Минимизируется количество обращений к памяти за операндами, для чего в процессоре делается большое количество регистров общего назначения, в которых можно расположить все промежуточные и временные переменные.
C) Регистры унифицируются, что позволяет уменьшить влияние ложных зависимостей (любой регистр можно использовать в любой команде в любом месте и с любым способом адресации).
D) В процессор вводится (накристальный) кэш с малым временем доступа. Кэш команд и данных разделяется, что позволяет производить (пред)выборку кода параллельно с выборкой операндов.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.