E (Executable) – признак исполняемости сегмента. (Для сегмента кода E=1, для сегментов данных или стека E = 0).
C (Conforming) – признак подчиненности сегмента: (При С=1 код запрашиваемого сегмента будет исполняться, если текущий уровень привилегий процессора (CPL) не выше уровня привилегий дескриптора запрашиваемого сегмента (DPL); При С=0 (неподчиненный сегмент), управление на данный сегмент может передаваться, только, если CPL=DPL).
R (Readable) – признак читаемости кодового сегмента. При R=1, можно считать, т.е. скопировать содержимое кодового сегмента. Если же R=0, то содержимое кодового сегмента считать нельзя, что является защитой от несанкционированного (случайного или умышленного) копирования программ.
A (Accessed) – признак обращения к данному сегменту. Если A=0, то это означает, что к моменту контрольного обращения к этому биту, обращения процессора к данному сегменту (кода, данных или стека) не было. Если же A=1, то это означает, что к данному моменту селектор этого сегмента уже загружался в сегментный регистр или для него выполнялась команда тестирования. Обычно, операционная система привлекает бит A для того, чтобы выбрать нечасто используемые сегменты, которые при необходимости можно передать на жесткий диск (при P = 0) в процессе свопинга (swapping). Биты A у дескрипторов всех сегментов первоначально должны находиться в состоянии 0. Через регулярные интервалы времени ОС сканирует все дескрипторы и сбрасывает их биты A в нуль. Если в некоторый момент времени у дескриптора определялся бит A=1, то это означает, что к нему после предыдущего сканирования были обращения. При этом ОС производит инкремент времени последнего использования таких сегментов. Когда появляется необходимость выбирать сегмент в оперативной памяти для передачи его на жесткий диск, то этим сегментом будет сегмент неиспользованный за интервал сканирования, т.е. тот у которого бит A=0. Если к этому моменту у всех сегментов A=1, то будет выбран сегмент, к которому дольше всего не было обращения, т.е. интервал времени от последнего обращения к нему до момента принятия решения о свопинге было максимальным. Описанный принцип, по которому из оперативной памяти выбирается сегмент, подлежащий передаче во внешнюю память, носит название алгоритма LRU (Least Recently Used – наименее используемый к настоящему моменту времени).
Очевидно, каждому сегменту должен соответствовать свой счетчик, подсчитывающий время от последнего обращения к сегменту. Тогда, при использовании, например, 16 сегментов, необходимо 16 счетчиков. Если же сегментов значительно больше, то и счетчиков соответственно должно быть больше. Поэтому иногда делают так, что биты A сбрасываются все после того, как они у всех дескрипторов стали равными 1 (при этом дескриптор, к которому было последнее обращение, остается с битом A=1) и все начинается сначала. Такой способ особенно широко применяется при свопинге страниц, при использовании страничной организации памяти.
ED (ExpansionDirectionили ExpandDown) – признак направления изменения адресов при обращении к данному сегменту. Этот признак является признаком отличия сегмента стека (ED = 1) от сегмента собственно данных (ED = 0). Он управляет интерпретацией поля предела. В сегменте данных адресация в процессе изменения начинается с базового адреса сегмента (зафиксированного в сегментном регистре), и границей сегмента будет адрес равный сумме базового адреса и предела сегмента. Поэтому для сегмента данных допустимыми будут все смещения меньшие или равные указанному пределу.
В сегменте стека, адреса ячеек стека, при его использовании, изменяются в сторону уменьшения адресов. Поэтому начальным адресом стековой памяти будет являться сумма базового адреса и константы 0FFFFh (64К-1), в случае, когда бит D = 0, т.е. в случае 16 разрядной адресации, либо суммой базового адреса и константы 0FFFFFFFFh (4Г-1), в случае, когда бит D = 1, т.е. в случае 32 разрядной адресации. Минимальный же адрес стековой памяти определяется значением предела. Так как все смещения в сегменте должны быть больше предела, максимальный размер стека получается, когда предел равен 0. Минимальный же размер стека получается, когда предел равен либо 0FFFFh (при D=0), либо 0FFFFFFFFh (при D = 1), что соответствует пустому сегменту с нулевым размером.
Сегменты стека по существу являются разновидностью сегментов данных. Они отличаются от сегментов, собственно данных, с разрешенными операциями записи и считывания, только интерпретацией поля предела, которое определяет размер стека с учетом бита гранулярности G. Отметим сразу же, что термин «расширение вниз», т.е. к меньшим адресам, относится к той графической иллюстрации адресного пространства, в которой нулевой адрес находится внизу рисунка, а максимальный адрес вверху.
На рис III.5 иллюстрировано различие между интерпретацией поля предела для сегментов данных и сегментов стека в случае, когда они оба имеют предел 1FFFh (G = 0). Отметим, что в процессорах i386+ при бите D = 1, бит гранулярности G также должен находиться в состоянии 1. Если же бит D = 0, то и бит G должен находиться в состоянии 0. Следовательно, необходимо не только определить 32 битный сегмент стека с максимальным адресом 4Г-1, но и установить предел в единицах 4К байт (т.е. в страницах).
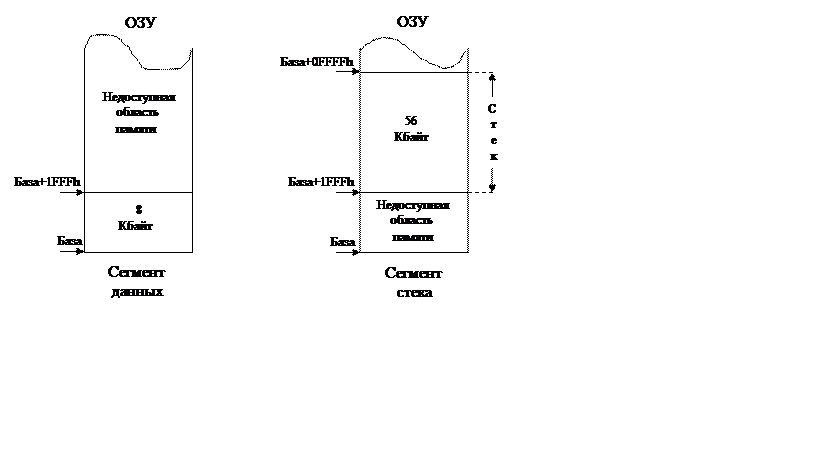
Рис III.5. Интерпретация поля предела для сегментов данных и
сегментов стека
W (Writable) – признак того, что в данный сегмент данных информация может быть записана и модифицирована (W = 1). Если же W =0, то этот сегмент является сегментом, для которого разрешено только считывание информации. Запись же информации в него или ее модифицирование – запрещена. Таким образом, память сегмента данных в этом случае работает в режиме ROM – памяти. Этот режим работы сегмента бывает очень важным в случае, если в сегменте размещены некоторые данные, таблицы, константы, которые широко используются многими программами и изменение, в которых может быть осуществлено только на системном уровне.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.