Сразу после запуска производится сканирование каталога программы на наличие таблиц перекодировки и таблиц весов, найденные таблицы загружаются в память. Для осуществления распознавания необходимо открыть файл из программы. Текст целиком читается в память и только после этого производится его обработка. Файл побайтно подается на вход нейронной сети, таким образом устанавливая входы первого слоя нейронов. При этом на каждом входе производится подсчет числа символов с соответствующим кодом. После этого вычисляется доля каждого символа в тексте по формуле (1). И только после описанных действий производится запуск в работу нейронной сети. Такой подход обеспечивает максимальную параллельность обработки данных, что снижает затраты времени на анализ. Алгоритм распознавания кодировки приведен на рис.3.
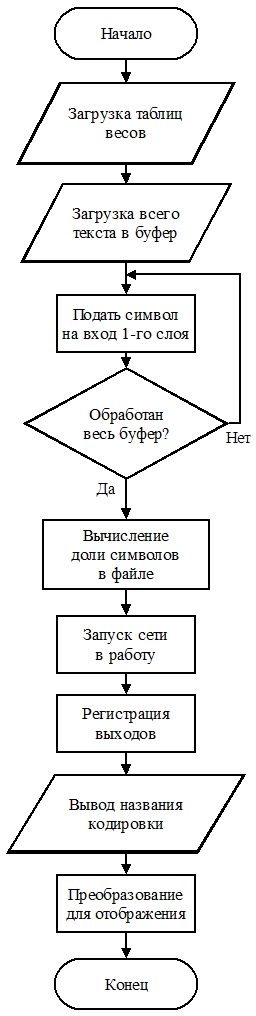
Рисунок 3 Алгоритм распознавания кодировки
Ключевым звеном алгоритма перекодирования является сопоставление кодов исходной и конечной кодировок.
Для наибольшей скорости обработки сначала производится формирование промежуточной таблицы перекодировки для конкретных двух кодировок – исходной и конечной, после чего каждый символ исходного текста заменяется соответствующим ему символом в новой кодировке. Алгоритм перекодирования представлен на рис.4.
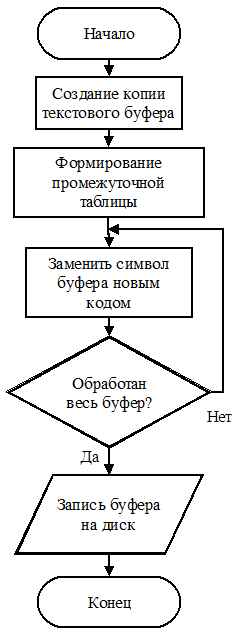
Рисунок 4 Алгоритм перекодирования
Частью алгоритма обучения является алгоритм распознавания кодировки. Отличием является лишь то, что при выполнении этого алгоритма известен ожидаемый результат. И в случае несовпадения ожидаемого и реального результатов производится корректировка весов сети. Алгоритм обучения нейронной сети представлен на рис.5.
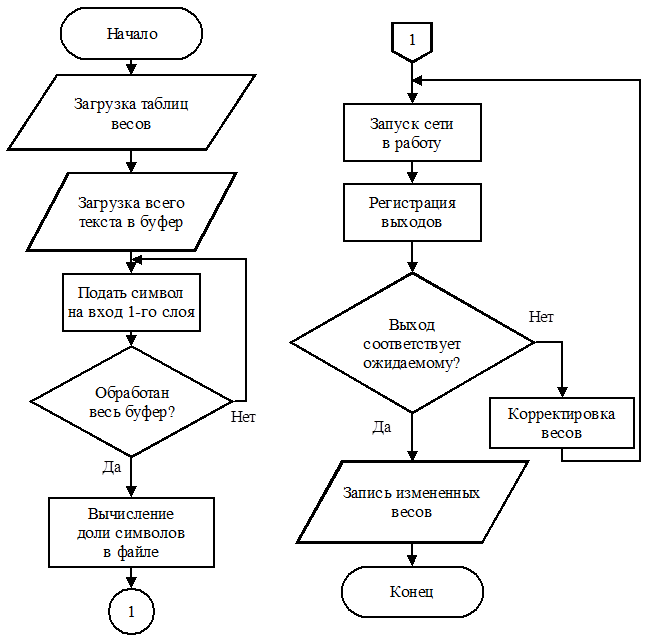
Рисунок 5 Алгоритм обучения нейронной сети
Использование RAD значительно упрощает и ускоряет процесс создания интуитивно понятного интерфейса в приложениях. Использование меню, кнопок, форм и окон сообщений позволяет создавать интерфейс, подчиняющийся стандартам Windows и схожий с интерфейсами других приложений.
Во время инициализации переменных приложения и загрузки таблиц перекодировки на экране отображается форма, показанная на рис.6.

Рисунок 6 Визуализация процесса загрузки приложения
В нижней строке формы можно видеть имена файлов кодовых таблиц по мере обнаружения их программой в своем каталоге.
Для определения кодировки файла, необходимо нажать кнопку «Открыть» (или выбрать пункт меню «Файл»®«Открыть…»). После чего отобразится линейка прогресса, показывающая примерное число процентов проделанной работы. Когда процесс распознавания кодировки завершится, пользователь видит это в соответствующем сообщении программы (рис.7).
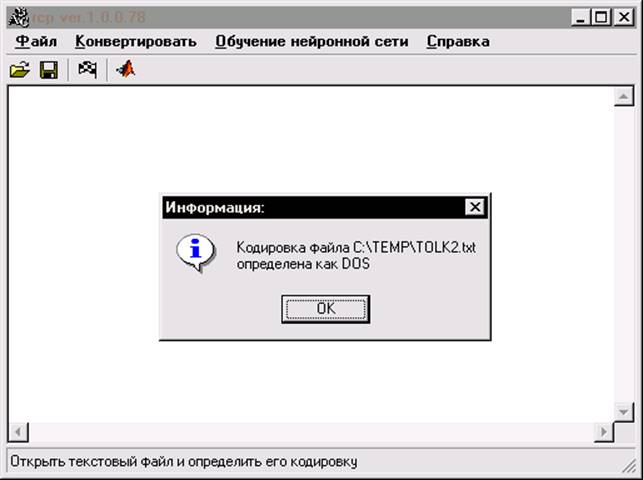
Рисунок 7 Сообщение об определении кодировки
После определения кодировки можно произвести преобразование текста в любую другую (из доступных) кодировку. Для этого надо выбрать пункт меню «Конвертирование» или нажать соответствующую кнопку в панели. В диалоге перекодировки пользователю предоставляется выбор новой кодировки текста (рис.8).
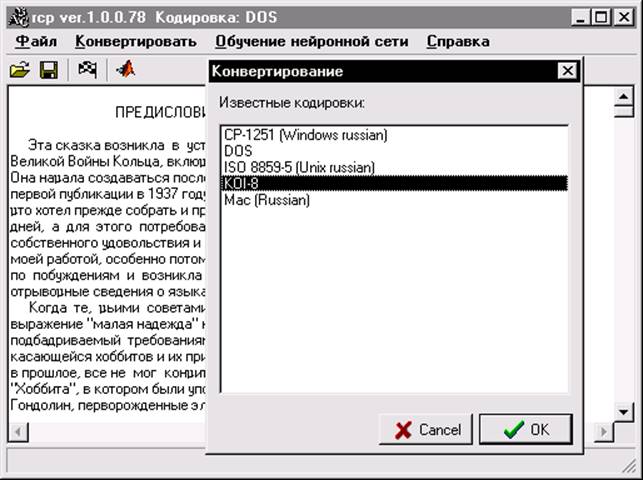
Рисунок 8 Диалог конвертирования
Диалог обучения нейронной сети вызывается путем выбора пункта меню «Обучение нейронной сети». В этом диалоге от пользователя требуется выбрать название кодировки (или ввести имя неизвестной) для обучения и имя файла-эталона. Эталон служит для анализа частот повторения различных символов в файле. Эти частоты подаются на вход нейронной сети и вычисляется выход.
К файлу-эталону предъявляются жесткие требования:
1. он должен быть по возможности большим;
2. файл должен содержать как можно более развитую речь, включающую как общеупотребительные, литературные слова, так и технические термины;
3. эталон должен содержать как можно меньше примесей символов в другой кодировке, латинских символов, цифр и псевдографики.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.