· простота, единообразие и интуитивная понятность интерфейса обеспечивается современными средствами RAD (Rapid Application Development) – программа писалась на Borland C++ Builder 3.0.
Задача распознавания кодировки русского текста сходна с задачами распознавания образов. Имеется определенный набор (в данном случае 256 кодов символов) параметров, значения которых зависят от кодировки обрабатываемого массива символов. В качестве параметров будем использовать долю символа в общем объеме текста:
![]()
где mi – вес i-го символа в данном тексте;
i – код символа в ASCII;
ni – количество символов с кодом i в тексте;
N – общее количество всех символов в тексте.
Таким образом, признаками в данном случае будут являться веса символов во входном тексте, которые будут преобразовываться по мере работы программы в зависимости от ранее установленных весов на каждом из входов нейронов промежуточных, входного и выходного слоев нейронной сети. Суммарные веса на входах нейронов последнего (выходного) слоя дадут ответ на вопрос о кодировке текста.
Для осуществления распознавания кодировок применим структуру сети, разработанную Розенблатом в 1957 году. Однослойный персептрон способен распознавать простейшие образы. Отдельный нейрон вычисляет взвешенную сумму элементов входного сигнала, вычитает значение смещения и пропускает результат через жесткую пороговую функцию, выход которой равен +1 или -1. В зависимости от значения выходного сигнала принимается решение: +1 - входной сигнал принадлежит классу A, -1 - входной сигнал принадлежит классу B.
Связи между нейронами одного слоя отсутствуют, между выходами промежуточного слоя и входами выходного слоя существует связь типа «каждый с каждым». Это обеспечит:
1) гибкую структуру сети, которая может быть изменена в соответствии с несложным алгоритмом в процессе работы программы;
2) каждый нейрон выходного слоя способен анализировать веса всех возможных кодов символов, что расширяет круг кодировок, которые будет способна анализировать программа.
Структура сети представлена на рис.1.
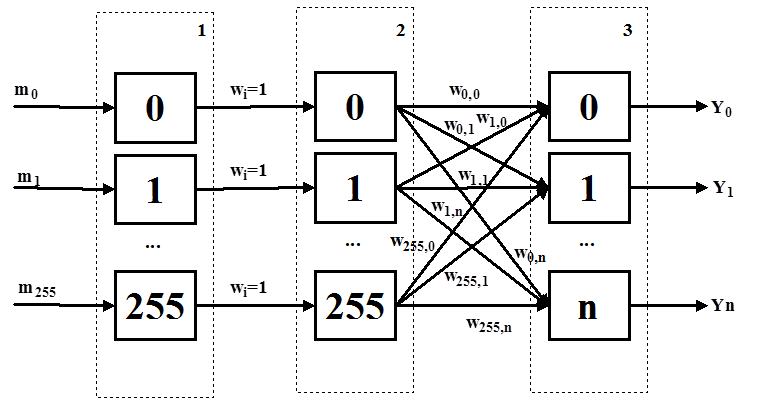
Рисунок 1 Структура нейронной сети
Слой №1 служит как бы входным буфером – на его входы поступают веса символов в тексте mi. Второй слой не осуществляет взвешиваний выходов нейронов первого слоя, т.к. матрица весов заполнена единицами. Второй слой только осуществляет усиление входного сигнала, поступившего от нейронов первого слоя.
Выход каждого нейрона второго слоя подается на вход каждого из нейронов выходного слоя. Между вторым и третьим слоями находится матрица весов – предпочтений нейронов третьего слоя. Строго говоря, таких матриц n – т.е. для каждой кодировки своя матрица весов. Единица на выходе (Yi) одного из нейронов третьего слоя сигнализирует о принадлежности текста определенной кодировке. В нашем случае для обеспечения большей гибкости алгоритма и возможности значительного увеличения числа распознаваемых кодировок, примем, что на выходе нейрона единица, если его выходное значение больше, чем у всех остальных.
В качестве передаточной функции выберем сжимающую сигмоидальную функцию. Выбор основывается на том, что эта функция обеспечивает сужение диапазона изменения выходной величины при изменениях входа и большее усиление при малых значениях входной величины.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.