FDIV 40 тактов
FCOS/FSIN 18-124 такта
FBSTP * 150 тактов
Наиболее эффективным способом борьбы с издержками, описанными выше, является использование межблочных буферов.
При использовании буфера между двумя соседними блоками конвейера команд их работа становится во многом независимой друг от друга, так как предыдущий блок может выполнять свою работу над последовательными командами программы до полного заполнения своего выходного буфера.
В свою очередь, последующий блок конвейера, использующий этот буфер как входной, может выполнить свою работу при наличии хотя бы одного элемента команды в этом буфере.
Уже в первой реализации простейшего двухступенчатого конвейера команд в процессоре Intel 8086 имелся подобный буфер емкостью 6 байт, называемый очередью команд - IQ (Instruction Queue). В последующих моделях этот буфер сохранился, однако возросла его длина. Примером другого буфера может служить очередь декодированных команд, которая является результатом работы блока конвейера DU (Decode Unit).
Еще одной причиной снижения производительности конвейера команд являются запросы аппаратных прерываний (в частности, по вводу/выводу). Вследствие их асинхронного характера по отношению к выполняемой программе каких-либо методов их предсказания и уменьшения степени их влияния предусмотреть невозможно.
Основные способы увеличения производительности конвейера команд
Простейшие способы были рассмотрены ранее в качестве мер, уменьшающих конфликты различных видов.
1. Использование буфера BTB на этапе выборки команд для организации спекулятивной выборки и выполнения команд.
2. Использование межблочных буферов для сглаживания различий в длительностях фаз конвейера.
3. Разделение трудоемких фаз конвейера на более мелкие ступени, т.е. переход к супер- и гипер- конвейерной архитектуре. За счет этого можно увеличить тактовую частоту и, следовательно, производительность процессора. (Временная диаграмма работы суперконвейера и его сравнение с обычным конвейером - Цилькер и Орлов стр. 445-446).
4. Расширение уровней параллелизма в конвейере команд.
В обычном линейном конвейере команд, даже в том случае, если он супер- или гипер- могут параллельно выполняться n машинных команд (n - число ступеней конвейера), каждая на своей фазе конвейера. Принципиально можно использовать 2 подхода для увеличения возможностей ILP (распараллеливания) в конвейере команд:
• использование нескольких параллельных конвейеров команд;
• использование одного конвейера команд и нескольких параллельно работающих исполнительных (обрабатывающих) блоков на фазе EX линейного конвейера.
И тот и другой подходы переводят процессор в ранг суперскалярных (Super Scalar Architecture).
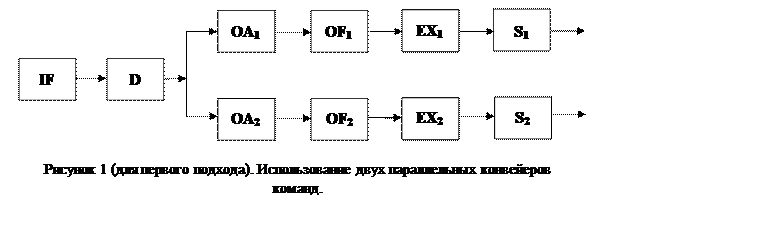
Подобный подход реализован первой модели процессора Pentium.
![]()
Подобный подход впервые реализован фирмой Intel в модели Pentium Pro (архитектура Р6).
В качестве исполнительных блоков, реализующих параллельно фазу EX для нескольких команд, могут использоваться:
- несколько (2-3) целочисленных ALU (IU);
- блок FPU;
- блоки мультимедийной (векторной) обработки: MMX, SSE, AltiVec, 3DNow! и т.д.
Понятия суперскалярной архитектуры и суперскалярных процессоров.
1. (по Столлингсу) Под суперскалярной реализацией архитектуры процессора понимается такая реализация, в которой обычные машинные команды - арифметики, загрузки, сохранения и условного перехода - могут запускаться на выполнение одновременно и выполняться независимо друг от друга.
2. (по Цилькеру и Орлову) Суперскалярным называется центральный процессор, который одновременно выполняет более чем одну скаляруню команду. Это достигается за счет включения в состав ЦП нескольких самостоятельных функциональных (исполнительных) блоков, каждый из которых отвечает за свой класс операций и может присутствовать в процессоре в нескольких экземплярах. Суперскалярность предполагает параллельную работу максимального числа исполнительных блоков, что возможно лишь при одновременном выполнении нескольких скалярных команд. Последнее условие хорошо сочетается с конвейерной обработкой, при этом желательно, чтобы в суперскалярном процессоре было несколько конвейеров (например, 2 или 3).
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.