5.2 Основные теоретические сведения
Ранговый однофакторный анализ
Если ничего не известно о распределении наблюдений, полученных при различных уровнях фактора, то для проверки совпадения нескольких средних часто используют информацию, которая содержится в рангах наблюдений xij при их упорядочении в порядке возрастания. Обозначив через rij ранг значения xij, получим следующую таблицу.
|
Номер испытания |
Уровни фактора А |
||||
|
А1 |
Aj |
Ak |
|||
|
1 2 … i ... n |
r11 r12 ... ri1 … rn1 |
… … … … … … |
r1j r2j ... rij … rnj |
… … … … … … |
r1k r2k ... rik … rnk |
В рамках ранговых критериев нулевая гипотеза формулируется как гипотеза H0: все k совокупностей (столбцов таблицы) одинаково распределены. Строго говоря, если нулевая гипотеза отвергается, то можно только утверждать, что распределения совокупностей различны. Это, однако, не означает, что их средние не равны между собой. Для вывода о том, что выборки производились из совокупностей с различными средними, необходимо предположить, что эти совокупности одинаковы по всем другим параметрам. На практике, однако, допустимы умеренные отклонения от этого правила.
Непараметрический критерий Краскела-Уоллиса для проверки нулевой гипотезы основан на статистике
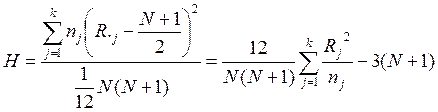 ,
,
где 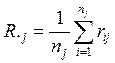 – средний ранг, рассчитанный
по j-му столбцу;
– средний ранг, рассчитанный
по j-му столбцу; 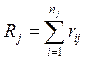 – сумма рангов j-го
столбца;
– сумма рангов j-го
столбца; 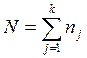 – общее число наблюдений.
– общее число наблюдений.
Для небольших объемов выборок имеются таблицы процентных точек распределения статистики Краскела-Уоллиса. При больших объемах выборок статистика H при справедливости нулевой гипотезы распределена приближенно по закону χ2 с k-1 степенями свободы. Если в таблице данных есть совпадающие значения, то при их ранжировании следует использовать средние ранги. Если совпадений много, то рекомендуется применять модифицированную форму статистики H:
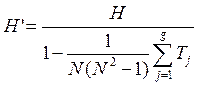 ,
,
где
g – число групп совпадающих наблюдений; ![]() ;
; ![]() – число
совпадающих наблюдений в группе с номером j.
– число
совпадающих наблюдений в группе с номером j.
Ранговый двухфакторный анализ
Рассмотрим двухфакторный эксперимент, когда на уровнях фактора В проведено по одному наблюдению (неповторяемый эксперимент), при котором таблица данных имеет следующий вид
|
A1 |
… |
Ai |
… |
Ak |
|
|
В1 |
x11 |
… |
xi1 |
… |
xk1 |
|
… |
… |
… |
… |
… |
… |
|
Вj |
x1j |
… |
xij |
… |
xkj |
|
… |
… |
… |
… |
… |
… |
|
Вn |
x1n |
… |
xin |
… |
xkn |
В отличие от факторного анализа ранжирование осуществляется не по всей совокупности величин xij, а по строкам (для проверки однородности данных по столбцам таблицы данных), т. е. ранжируется каждая отдельная строка таблицы данных. Этим устраняется влияние "мешающего" фактора В, значение которого для каждой строки постоянно.
Для проверки гипотезы H0: влияние фактора A (эффектов столбцов) отсутствует, при H1: влияние фактора A есть, используется статистика Фридмана
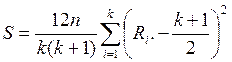 ,
,
где
– средний ранг, рассчитанный по j-му
столбцу; rij –
ранг величины xij.
При вычислениях удобно использовать другую запись статистики:
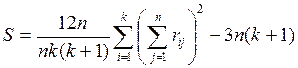 .
.
Для небольших значений k и n имеются таблицы процентных точек распределения статистики
Фридмана, позволяющие при заданном уровне значимости ![]() находить
критические значения S(k, n,
находить
критические значения S(k, n, ![]() ). Гипотеза H0 не отвергается, если расчетное
значение статистики меньше критического.
). Гипотеза H0 не отвергается, если расчетное
значение статистики меньше критического.
При больших n при справедливости нулевой гипотезы статистика S аппроксимируется распределением χ2 с k-1 степенями свободы.
Если в строках таблицы данных имеются совпадающие значения, при переходе к таблице рангов используются средние ранги, а вместо статистики S используется ее модификация.
Для проверки гипотезы об эффектах фактора В (строк) следует поменять местами строки и столбцы таблицы данных.
5.3 Вопросы для самоконтроля
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.