Доказательство. Пусть
матрица Н обладает свойством, что ![]() столбцов
линейно независимы,
столбцов
линейно независимы, ![]() - кодовый вектор. Тогда
- кодовый вектор. Тогда ![]() или, раскрыв матричную запись,
получим
или, раскрыв матричную запись,
получим 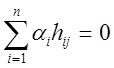 . Число элементов
. Число элементов ![]() (т.е. столбцов Н), реально
участвующих в проверках, очевидно, равно числу ненулевых компонент
(т.е. столбцов Н), реально
участвующих в проверках, очевидно, равно числу ненулевых компонент ![]() вектора
вектора ![]() ,
т.е. весу кодового вектора. В силу условия линейной независимости
,
т.е. весу кодового вектора. В силу условия линейной независимости ![]() столбцов матрицы Н равенство
нулю возможно только при d или большем числе ненулевых
столбцов матрицы Н равенство
нулю возможно только при d или большем числе ненулевых ![]() ;. Значит, минимальный вес кодового
вектора равен d или больше и кодовое расстояние тоже d или
больше. Теорема доказана.
;. Значит, минимальный вес кодового
вектора равен d или больше и кодовое расстояние тоже d или
больше. Теорема доказана.
Можно, как следствие,
заметить, что если все столбцы матрицы Н различны, то кодовое расстояние
равно трем или больше. Действительно, при всех различных столбцах никакие два
из них в сумме не равны нулю, т.е. линейно независимы. Отсюда ![]() .
.
2. Если имеется модулярное представление кода, в частности двоичного, то спектр этого кода можно найти на основании теоремы Макдональда.
Веса каждого из ![]() ненулевых кодовых слов двоичного
группового кода могут быть найдены как компоненты вектора, получающегося в
результате матричного умножения (как матриц с действительными числами) вектора
ненулевых кодовых слов двоичного
группового кода могут быть найдены как компоненты вектора, получающегося в
результате матричного умножения (как матриц с действительными числами) вектора
![]() модулярного представления кода на
матрицу
модулярного представления кода на
матрицу ![]() :
: ![]() или
или
![]() . Веса кодовых слов оказываются
упорядоченными так же, как кодовые слова в матрице
. Веса кодовых слов оказываются
упорядоченными так же, как кодовые слова в матрице ![]() .
.
3. Граница Синглтона.
Минимальный вес любого линейного ![]() -кода
удовлетворяет неравенству
-кода
удовлетворяет неравенству ![]() .
.
Доказательство. Ненулевое
слово минимального веса имеет вес d. Имеются слова в систематическом
коде о одним ненулевым информационным символом. Так как еще имеется только ![]() проверочных символов в слове, то вес
не может быть больше
проверочных символов в слове, то вес
не может быть больше ![]() . Код с
. Код с ![]() называется кодом с максимальным
расстоянием.
называется кодом с максимальным
расстоянием.
4. Спектры линейного кода А
и двойственного ему ![]() взаимосвязаны. Эта связь
оказалась весьма полезной для расчета спектров многих блоковых кодов. Пусть
взаимосвязаны. Эта связь
оказалась весьма полезной для расчета спектров многих блоковых кодов. Пусть ![]() - спектральная функция
- спектральная функция ![]() -кода А,
-кода А, ![]() - спектральная функция
- спектральная функция ![]() . Согласно тождеству Мак-Вильямс:
. Согласно тождеству Мак-Вильямс:
![]() (*)
(*)
Спектры кодов до ![]() в настоящее время находятся с
помощью ЭВМ. С помощью (*) удается найти спектр кода большей длины, лишь бы
число проверочных символов не превышало 25.
в настоящее время находятся с
помощью ЭВМ. С помощью (*) удается найти спектр кода большей длины, лишь бы
число проверочных символов не превышало 25.
Методы декодирования линейных кодов
Декодирование по максимуму правдоподобия является наиболее общим методом. Для симметрично искажающих каналов без памяти декодирование заключается в последовательном сравнении принятой последовательности с каждым из возможных кодовых слов и выборе среди них ближайшего по метрике Хемминга в качестве результата декодирования. Чтобы реализовать этот метод, целесообразно построить таблицу стандартной расстановки. Как эта таблица получается, проще всего пояснить на примере группового кода, код в этом случае есть подгруппа. Элементы подгруппы - кодовые комбинации. Их запишем в первую строку таблицы, поместив нулевую комбинацию в начало, и разложим группу по смежным классам. Все возможные на приеме последовательности будут содержаться в таблице.
|
Лидеры смежных классов |
|
. |
|
|
… |
|
|
|
. |
|
|
… |
|
|
|
|
. |
|
|
… |
|
|
|
Смежный класс |
||||||
|
|
. |
|
|
… |
|
|
|
|
. |
|
|
… |
|
|
Каждая строка образует смежный класс. Первый элемент строки называют лидером смежного класса (образующим). Если в качестве лидеров выбраны элементы строки с минимальным весом, то приведенная таблица называется стандартной расстановкой. Весом смежного класса считают вес его лидера.
Пусть а - переданное
слово; ![]() - принятая последовательность. Если
используется ДСК без памяти, то в качестве лидеров надо выбирать векторы ошибок
наиболее вероятные, т.е. с одиночной ошибкой, двойной и т.д., пока позволяют
свойства кода. Декодирование будет состоять в следующем:
- принятая последовательность. Если
используется ДСК без памяти, то в качестве лидеров надо выбирать векторы ошибок
наиболее вероятные, т.е. с одиночной ошибкой, двойной и т.д., пока позволяют
свойства кода. Декодирование будет состоять в следующем:
- находится в таблице последовательность, равная ![]() ;
;
- определяется лидер той строки, в которой оказалась
последовательность ![]() ;
;
- вычисляется ![]() как результат
декодирования.
как результат
декодирования.
Ценность стандартной
расстановки относительна. Для больших ![]() и
и
![]() технически реализовать такую таблицу
на ЭВМ становится невозможным. Трудность табличного декодирования была
отмечена в главе I. Это не означает полного отрицания метода декодирования по
максимуму правдоподобия. Обычно за счет дополнительной информации о достоверности
символов удается ограничить "объем пространства" просматриваемых
комбинаций. Типичным примером являются алгоритмы Чейза [13].
технически реализовать такую таблицу
на ЭВМ становится невозможным. Трудность табличного декодирования была
отмечена в главе I. Это не означает полного отрицания метода декодирования по
максимуму правдоподобия. Обычно за счет дополнительной информации о достоверности
символов удается ограничить "объем пространства" просматриваемых
комбинаций. Типичным примером являются алгоритмы Чейза [13].
Синдромом вектора ![]() называет вектор
называет вектор ![]() , где
, где ![]() -
проверочная матрица. Если а - кодовый вектор, то, очевидно,
-
проверочная матрица. Если а - кодовый вектор, то, очевидно, ![]() . Утверждается, что все векторы,
принадлежащие одному смежному классу, имеют совпадающие синдромы.
Действительно, если
. Утверждается, что все векторы,
принадлежащие одному смежному классу, имеют совпадающие синдромы.
Действительно, если ![]()
![]() и
и
![]() - векторы одного смежного класса с
образующим, равным
- векторы одного смежного класса с
образующим, равным ![]() , то
, то ![]() ,
, ![]() ,
т.е.
,
т.е. ![]() .
.
Синдромы разных смежных
классов различны. Декодирование будет состоять в вычислений синдрома ![]() ; нахождении в памяти лидера,
соответствующего этому синдрому, выдачи результата декодирования в виде
; нахождении в памяти лидера,
соответствующего этому синдрому, выдачи результата декодирования в виде ![]() .
.
С помощью синдромов можно различать ошибки с точностью до смежных классов, которые они образуют.
Техническая реализация этого способа проще, чем по максимуму правдоподобия, но все еще достаточно сложна. Оценим и сравним сложность аппаратной реализация кодирования и декодирования двоичным кодом по максимуму правдоподобия и синдромному. Сложность будем оценивать в первом приближении числом элементов, из которых состоит кодер ила декодер, считая ах однородными.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.