На рис. 3,а приведена стандартная диаграмма линейного связанного списка; на рис 3,б приведена диаграмма связанного списка с рис. 2,б. Заметим, что ГРИДИН и СИДОРОВ отсутствуют в списке на рис 3,б хотя они присутствуют на рис 2,б как затемненные элементы. При реализации связанных списков участвует переменная FIRST(ПЕРВЫЙ) или HEAD (ГОЛОВА), значение которой есть адрес первой ячейки списка (рис 3,а).
Как было указано выше, одно из главных преимуществ связанных списков заключается в том, что можно легко удалять и добавлять элементы списка. Далее мы приводим два алгоритма, которые можно использовать при выполнении модификаций, требуемых для преобразования рис. 2,а в 2,б.
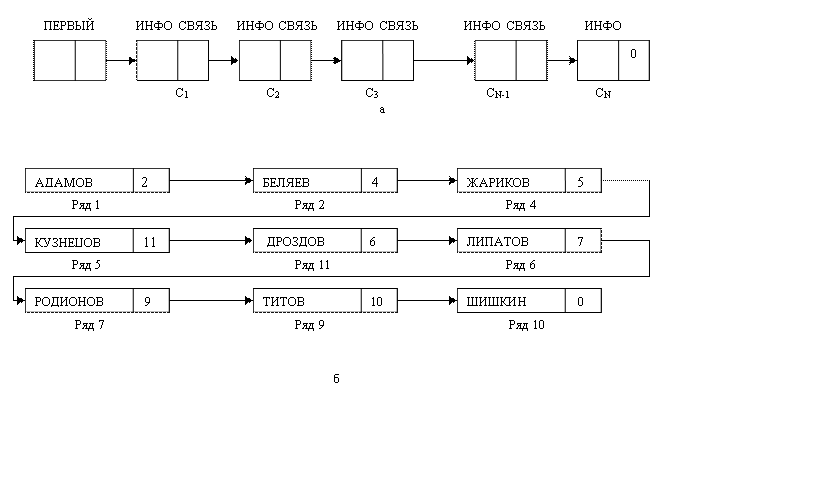

Рис. 3. Диаграммы линейных связанных списков.
Первый алгоритм будет удалять заданный элемент из связанного списка. Этот процесс иллюстрируется на рис. 4, где мы ищем ячейку Сi, у которой ИНФО (i)=ТРИ, передвигая указатели PREV и PTR до тех пор, пока такая ячейка не будет найдена. Затем мы заменяем значение СВЯЗЬ в ячейке, на которую указывает PREV, на значение СВЯЗЬ в ячейке, на которую указывает PTR. Далее следуют блок-схема (рис. 5), формальное описание и реализация этого алгоритма.
AlgorithmDELETE (УДАЛЕНИЕ). Удаляется ячейка Сi, у которой INFO(i)=VALUE из связанного списка, первая ячейка которого задается переменной FIRST.
Шаг 1 .[Выбор первой ячейки] SetPTR ←FIRST; PREV← 0/
Шаг 2. [Ячейка пуста ?] While PTR ≠0 doшаг 3od.
Шаг 3.[Это она?] If INFO (PTR)=VALUE
then[Это первая ячейка?]
if PREV=0 then[удалить спереди]
set FIRST←LINK (PRT); and STOP
else [удалить изнутри]
set LINK (PREV)←LINK(PTR);
and STOP fi
else[Выбор следующей ячейки]
set PREV←PTR; PTR←LINK(PTR) fi.
Шаг 4 . [Не в списке ] НАПЕЧАТАТЬ «ЗНАЧЕНИЕ НЕ В СПИСКЕ»;
and STOP.


Рис. 4 Удаление ячейки из связанного списка.
Следующий алгоритм будет вносить в связанный список новую ячейку. Предположим, что в списке ячейки упорядочены в порядке возрастания содержимого поля ИНФО(INFO). Этот алгоритм аналогичен алгоритму DELETE (УДАЛЕНИЕ) в том отношении, что при выполнении операции внесения используются указатели PREV и PTR.
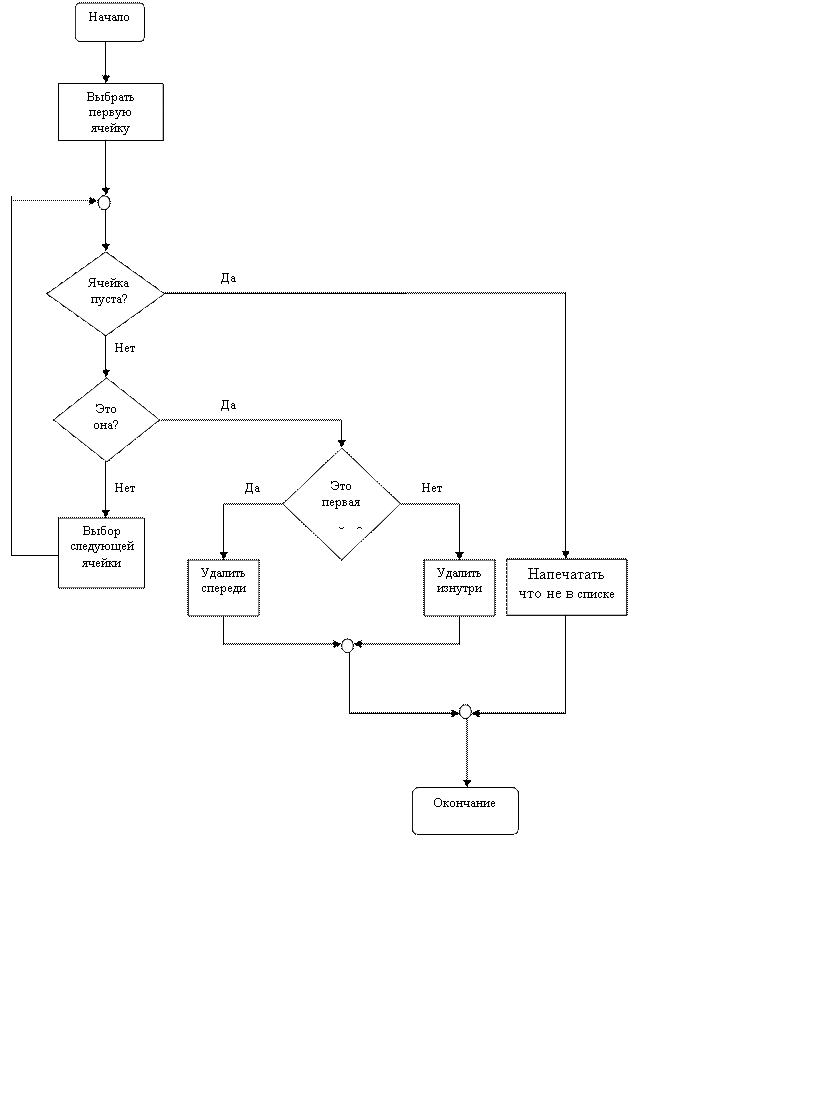

Рис. 5. Блок-схема DELETE (УДАЛЕНИЕ).
На рис. 6 проиллюстрирован процесс внесения, причем мы предполагаем, что:
ОДИН<ДВА<ТРИ<ЧЕТЫРЕ


Рис. 6. Внесение ячейки в связанный список.
На рис. 7 приведена блок-схема следующего алгоритма:
AlgorithmINSERT(ВНЕСЕНИЕ). Внести новую ячейку ROW (РЯД), где INFO (ROW)=VALUE, в упорядоченной связанный список, первая ячейка которого задаётся в FIRST (ПЕРВЫЙ).
Шаг 1. [Выбор первой ячейки] SetPTR ←FIRST; PREV←0
Шаг 2[Ячейка пуста ?]WhilePTR ≠ doшаг 3 od.
Шаг 3.[Предшествует ли новая ячейка выбранной?] IfVALUE≤ INFO (PTR)
then[вносится спереди?]
ifPREV=0 then[внести новую ячейку спереди]
set FIRST←ROW;
LINK (ROW)←PTR;
and STOP
else [внести новую ячейку внутрь]
set LINK(PREV)←ROW;LINK (ROW)←PTR;and STOP fi
else [Выбрать очередную ячейку]
set PREV← PTR;PTR←LINK(PTR) fi.
Шаг 4.[Список пуст?] IfPREV=0
then[внести новую ячейку как единственную ячейку в списке ]
set FIRST← ROW;LINK (ROW)←0;and STOP
else [внести новую ячейку в конец списка]
set LINK(PREV)←ROW; LINK (ROW)←0; and STOP fi.
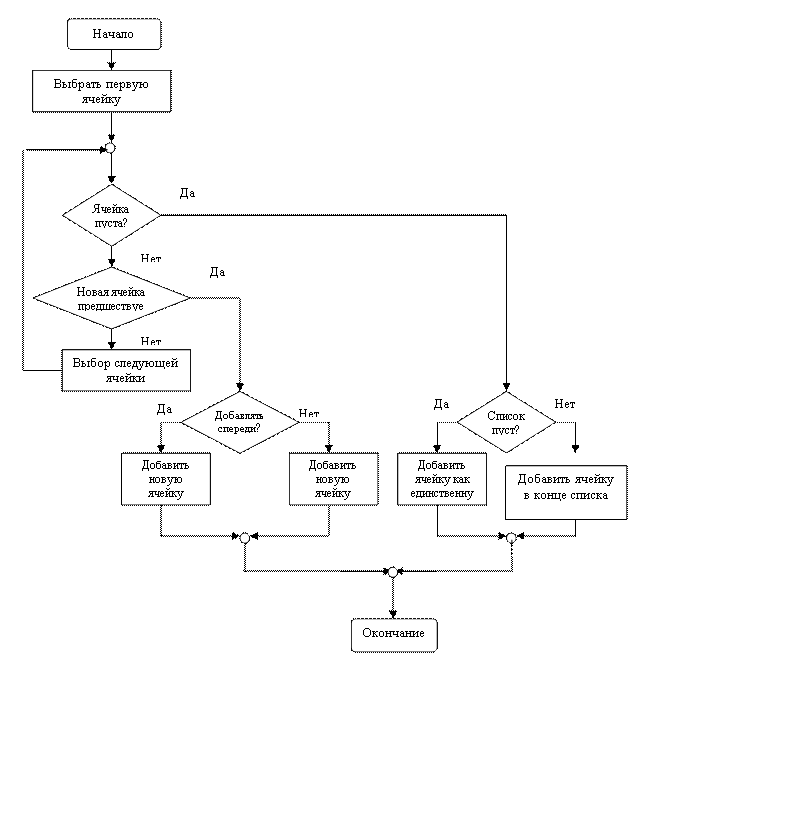

Рис. 7. Блок-схема INSERT (ВНЕСЕНИЕ).
2.2.2. Стековые списки и стеки
Мы увидели, что (линейные) связанные списки – это эффективная структура данных для моделирования ситуаций, в которых подвергаются изменениям упорядоченные массивы элементов данных. В частности, это справедливо для случая, когда модификациями являются главным образом внесение элементов в середину массивов или удаление элементов из середины массива . Когда модификации касаются лишь начала и конца, необходимость в связанных списках исчезает, и становятся достаточными простые линейные (одномерные) массивы.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.