13. Написать программу для сортировки методом прямых включений латинских букв по алфавиту.
14. Написать программу для быстрой сортировки букв английского алфавита.
15. Написать программу для быстрой сортировки букв английского алфавита, если последовательность менее 6 элементов методом прямых включений.
16. Написать программу для двоичного поиска числа в заранее отсортированном файле. Сортировка производится стандартной функцией.
Ввод и вывод информации осуществляется в графическом режиме. Дизайн на усмотрение студента.
2.2. Некоторые структуры данных
Среди преимуществ отметим следующие:
Недостатки массивов не так очевидны. Лучше всего массивы годятся для данных, значения которых не изменяются, порядок которых (важен он или не важен) также не изменяется. Если порядок элементов в массиве подвергается изменению, то каждый раз, когда порядок меняется, перестановка элементов требует очень много времени.
Рассмотрим, например, N-элементный массив CS100(N), в котором содержатся лексикографически упорядоченные имена студентов, слушающих в данный момент курс программирования CS100 (рис. 1, а).
 |
Рис. 1. Переорганизация линейного списка.
Если студенты Гридин и Сидоров перестают посещать курс, а новый студент Дроздов добавляется, то нам бы хотелось получить новый список слушателей, приведённый на рис. 1,б. Подумайте о трудности и стоимости написания и выполнения программы, которая смогла бы перестроить массив CS100 в соответствии с этими изменениями.
С другой стороны, связанный список представляет собой структуру данных, которая требует дополнительной памяти, но позволяет легко вносить такие изменения.
2.2.1. Связанные списки
На рис. 2,а массив CS100 преобразован из одномерного в двумерный массив CS100L. В столбце 1 массива CS100L по-прежнему содержатся фамилии студентов, зачисленных на курс CS100, хотя, как явствует из рис. 2,б, теперь уже не требуется, чтобы эти фамилии были упорядочены по алфавиту. В столбце 2 массива CS100L содержатся неотрицательные целые числа, называемые связями или указателями, значениями которых являются номера строк массива, содержащих фамилию следующего студента (в алфавитном порядке) в текущем списке. Звездочкой (*) мы отметили те указатели, значения которых изменились в связи с удалением фамилий ГРИДИН и СИДОРОВ и добавлением ДРОЗДОВ. Заметим, что на рис. 2,б:
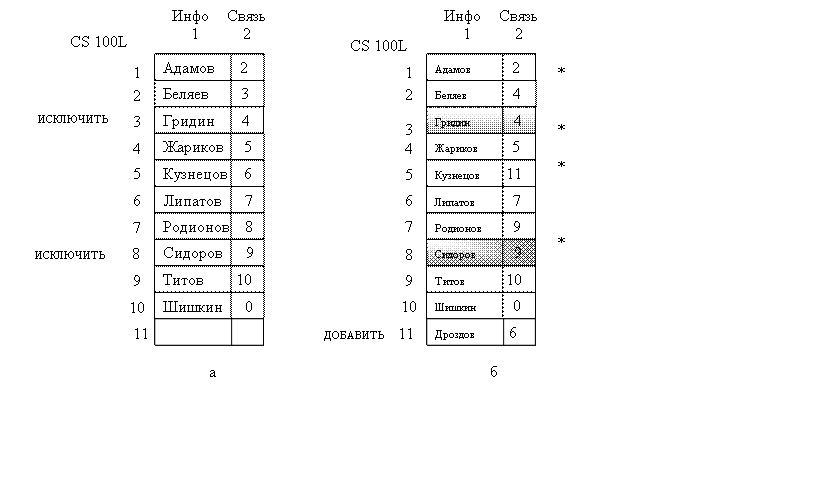
Рис. 2. Переорганизация связанного списка.
АДАМОВ указывает на БЕЛЯЕВ {CS100L (1, 2)=2 и CS100L(2 ,1)= БЕЛЯЕВ}.
БЕЛЯЕВ указывает на ЖАРИКОВ {CS100L(2, 2) =4 и CS100L (4, 1)= ЖАРИКОВ}
КУЗНЕЦОВ указывает на ДРОЗДОВ.
ДРОЗДОВ указывает на ЛИПАТОВ и т.д.
Массив CS100L(I,J) размера N×2 работает как линейный связанный список. Линейный связанный список – это конечный набор пар, каждая из которых состоит из информационной части INFO (ИНФО) и указующей части LINK (СВЯЗЬ). Каждая пара называется ячейкой. Если мы хотим расположить ячейки в порядке Ci1,Ci2,...,Cin,то СВЯЗЬ (ij)=ij+1 для j=1,...,n-1,а СВЯЗЬ (in)=0 и указывает на конец списка.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.