



























Алгоритм LZW
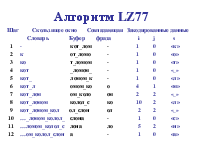
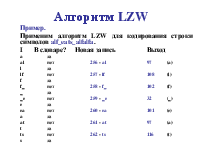
Пример. Применим алгоритм LZW для кодирования строки символов alf_eats_alfalfa. I В словаре? Новая запись Выход a да al нет 256 - al 97 (a) l да lf нет 257 - lf 108 (l) f да f_ нет 258 - f_ 102 (f) _ да _e нет 259 - _e 32 (_) e да ea нет 260 - ea 101 (e) a да at нет 261 - at 97 (a) t да ts нет 262 - ts 116 (t) s да
Алгоритм LZW
Пример (продолжение). Применим алгоритм LZW для кодирования строки символов alf_eats_alfalfa. I В словаре? Новая запись Выход s_ нет 263 - s_ 115 (s) _ да _a нет 264 - _a 32 (_) a да al да alf нет 265 - alf_ 256 (al) f_ да fa нет 266 - fa 102 (f) a да al да alf да alfa нет 267 - alfa 265 (alf) a да a,eof нет 97 (a)
Алгоритм LZW
Декодер начинает с заполнения словаря первыми символами алфавита (их, обычно, 256). Затем он читает входной файл, который состоит из указателей в словаре, использует каждый указатель для того, чтобы восстановить несжатые символы из словаря и записать их в выходной файл. Кроме того, он строит словарь тем же методом, что и кодер (этот факт, обычно, отражается фразой: кодер и декодер работают синхронно или шаг в щаг). На каждом шаге декодирования после первого декодер вводит следующий указатель, извлекает следующую строку J из словаря, записывает ее в выходной файл, извлекает ее первый символ x и заносит строку Ix в словарь на свободную позицию (предварительно проверив, что строки Ix нет в словаре). Затем декодер перемещает J в I. Теперь он готов к следующему шагу декодирования.
Алгоритм LZW
Специальное дерево является лучшей структурой для словаря. Один путь конструирования такой структуры данных – это построение дерева в виде массива узлов, в котором каждый узел является структурой из двух полей: символа и указателя на узел родителя. В самом узле нет указателя на его потомков. Перемещение вниз по дереву от родителя к потомку делается с помощью процесса хеширования, в котором указатель на узлы и символы потомков перемешиваются некоторой функцией для создания новых указателей. Предположим, что строка abc уже была на входе, символ за символом, и ее сохранили в трех узлах с адресами 97, 266, 284. Пусть далее за ними следует символ d. Теперь кодер ищет строку abcd, а точнее, узел, содержащий символ d, чей родитель находится по адресу 284.
Алгоритм LZW
Алгоритм LZW
Формат Deflate
Формат словарного сжатия Deflate, предложенный Кацем (Karz), используется популярным архиватором PKZIP. Сжатие осуществляется с помощью алгоритма типа LZH, иначе говоря, указатели и литералы кодируются по методу Хаффмена. Формат специфицирует только работу декодера, т.е. определяет алгоритм декодирования, и не налагает серьезных ограничений на реализацию кодера. В принципе в качестве алгоритма сжатия может применяться любой работающий со скользящим окном, лишь бы он исходил из стандартной процедуры обновления словаря для алгоритмов семейства LZ77 и использовал задаваемые форматом типы кодов Хаффмена.
Заключение
Все представленные здесь различные методы словарного сжатия используют одни и те же принципы. Они читают файл символ за символом и добавляют фразы в словарь. Фразы являются отдельными символами и строками символом входного файла. Методы сжатия различаются только способом отбора фраз для сохранения в словаре. Когда строка входного файла совпадает с некоторой фразой в словаре
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.