МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
Федеральное агентство по образованию
НОВОСИБИРСКИЙ ГОСУДАРСТВЕННЫЙ
ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
Учебный Центр Информационных Технологий «Информатика»

Лабораторная работа № 3
по дисциплине «Информатика и программирование ч.1»
Направление подготовки: 230105 - «Программное обеспечение вычислительной техники и автоматизированных систем»
Выполнил слушатель:
Вариант: № 9
Дата сдачи: __/__/____
Преподаватель:
Новосибирск, 2016г.
1. Цель.
Научиться работать со строками.
2. Вариант задания№9.
Найти в строке два одинаковых фрагмента длиной более 5 символов (не включая пробелы) и возвратить индекс начала первого из них (т.е. для “aaaaaabcdefgxxxxxxbcdefgwwwww” вернуть n=6 – индекс начала “bcdefg”).
3. Анализ задачи и алгоритм.
1) Анализ задачи
Входные данные: массив – строка символов.
Результат: значение индекса начала повторяющегося фрагмента символов.
Метод решения: в дополнительный массив сохраняем первые 6 символов исходного массива, проверяя при этом отсутствие символа пробела, и сохраняем значение индекса первого символа, взятого из исходного массива. Проверяем условие совпадения всех символов дополнительного массива с символами очередного фрагмента исходного массива. При выполнении данного условия выводим на экран фрагмент и предварительно сохранённый индекс. Если условие не выполнено, то производим сдвиг на один символ от начала строки.
2) Алгоритм решения задачи
· копирование первых шести символов исходного массива в дополнительный, проверяя при этом, что очередной символ не является пробелом;
· поиск фрагмента исходного массива, все символы которого совпадают со всеми символами дополнительного массива, сохранение индекса начала этого фрагмента;
· вывод фрагмента строки и его индекса.
4. Описание программной реализации.
Используемые переменные
str[] – исходная строка символов, тип char;
podstr[] – строка-шаблон, тип char.
Используемые функции
voidfill(str, podstr, k) – заполнение массива символов podstr[] элементами из массива str[], начиная с индекса k;
voidfind(str, podstr, k) – поиск в массиве str[] фрагмента совпадающего с содержимым массива podstr[]; поиск начинается с текущего индекса k, который и выводится при совпадении.
5. Пример работы программы.
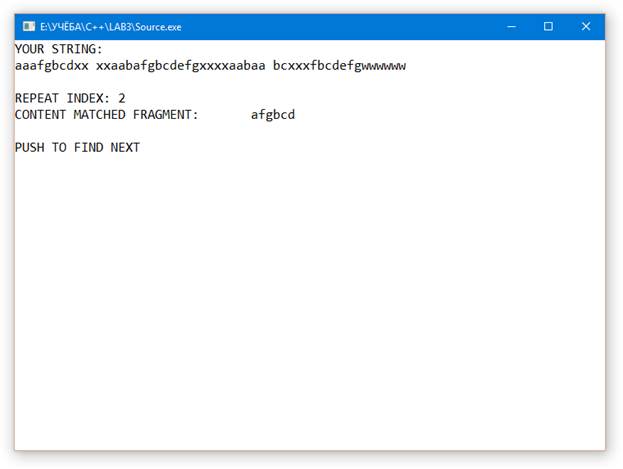
6. Вывод.
В ходе выполнения лабораторной работы я ознакомился с основами работы со строками. Освоил поиск одинаковых фрагментов строк.
7. Текст программы.
#include <stdlib.h>
#include <stdio.h>
#include <conio.h>
void fill(char*, char*, int); // заполнение массива символов podstr[]
void find(char*, char*, int); // поиск в массиве str[]
int main()
{
char str[80] = "aaafgbcdxx xxaabafgbcdefgxxxxaabaa bcxxxfbcdefgwwwwww"; // исходная строкa
printf("YOUR STRING:\n%s\n", str);
char podstr[7]=" "; // дополнительный массив
for (int k = 0; str[k] != '\0'; k++) // проходим по всей строке
{
fill(str, podstr, k);
find(str, podstr, k);
}
printf("\nNO MORE REPEAT\n");
_getch();
return 0;
}
void fill(char* str, char* podstr, int k)
{
for (int i = k, j = 0; j<6; i++, j++) // заполнение дополнительного массива
{
if (str[i]==' ') break; // при обнаружении пробела выходим из цикла
podstr[j] = str[i];
}
}
void find(char* str, char* podstr, int k) // поиск совпадающего фрагмента
{
for (int i = k + 6; str[i] != '\0'; i++)
{
if (podstr[0] == str[i] && podstr[1] == str[i + 1] && podstr[2] == str[i + 2] && podstr[3] == str[i + 3] && podstr[4] == str[i + 4] && podstr[5] == str[i + 5])
{
printf("\nREPEAT INDEX: %d\nCONTENT MATCHED FRAGMENT:\t%s\n\nPUSH TO FIND NEXT\n", k, podstr);
_getch();
}
}
}
8. Дополнительные вопросы.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.

